



搶在 OpenAI 推出 GPT-5 模型前夕,Anthropic 6 日推出 Claude Opus 4.1 模型,強化了 Opus 4 在代理任務、程式碼編輯、推理方面的表現。Anthropic 甚至預告,未來數週內推出更大規模的模型升級。
Opus 4.1 將 Claude 的程式碼編輯能力在基準測試 SWE-bench Verified 提升 2 個百分點、達到 74.5%,同時改善 Claude 深入研究和資料分析技能,尤其在細節追蹤和代理式搜尋方面更勝以往。
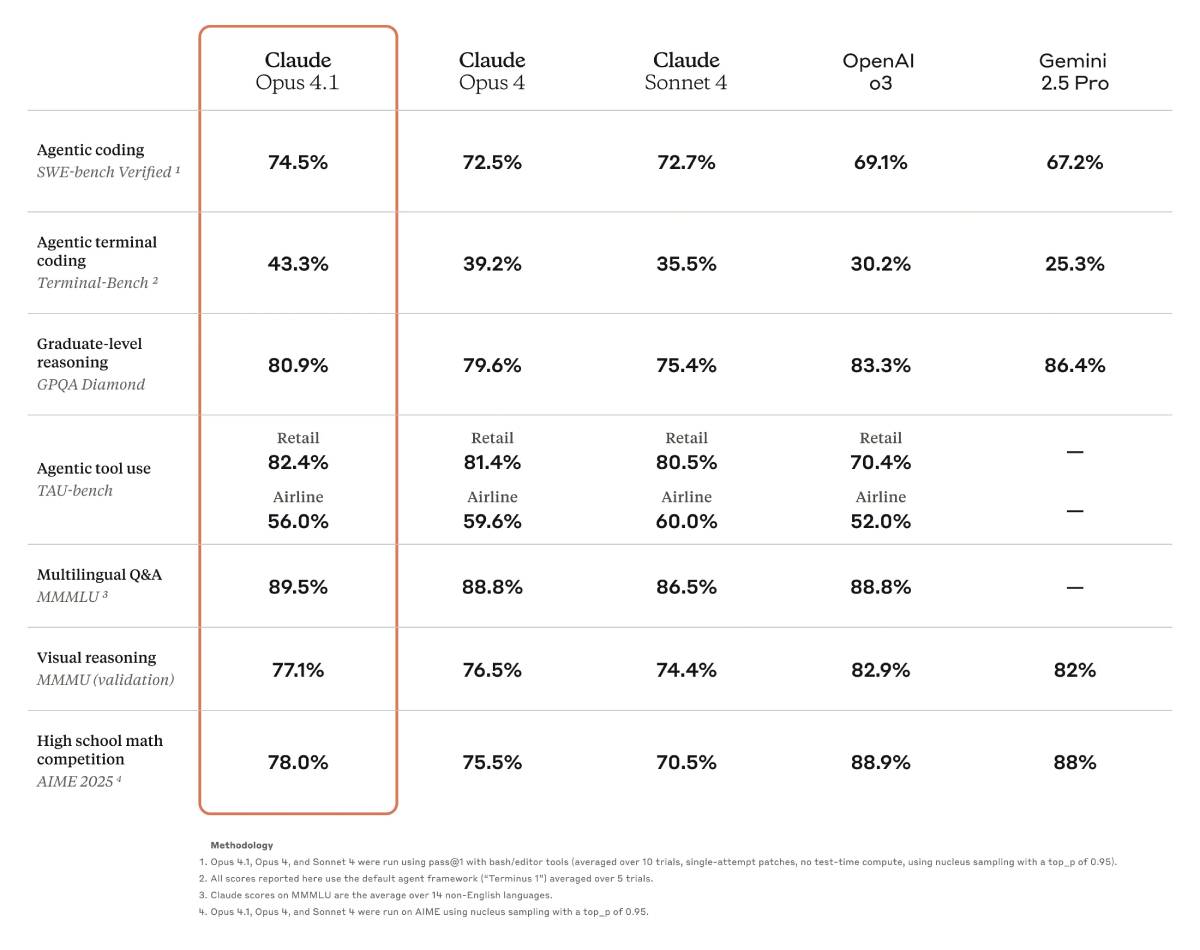
▲ Claude Opus 4.1 基準測試表現。
Anthropic 分享客戶測試情況,像是 GitHub 指出,相較 Opus 4,Opus 4.1 在多數功能上均有提升,其中多檔案程式重構的表現最為顯著。樂天集團(Rakuten Group)也發現,Opus 4.1 可在大型程式碼庫精準定位修正,避免不必要的調整或錯誤引進,樂天的團隊偏好在日常開發除錯保持這種精準度。Windsurf 則回報,Opus 4.1 在其「初級開發者基準測試」比 Opus 4 提升了一個標準差,性能提升幅度與 Sonnet 3.7 再到 Sonnet 4 大致相同。
Opus 4.1 定價與 Opus 4 相同,現在開放給付費訂閱用戶,並且可在 Claude Code 使用,客戶也能透過 Anthropic 的 API(claude-opus-4-1-20250805)、Amazon Bedrock 及 Google Cloud 的 Vertex AI 存取新版。
(首圖來源:Anthropic)





