



Anthropic 為 Claude 4 系列模型新推出 Claude Sonnet 4.5,宣稱它在面對程式碼編輯能力的基準測試達到最佳表現,尤其這款模型能夠建構「生產就緒」(production-ready)的 AI 應用,不再停留在原型階段。
Anthropic 表示,Claude Sonnet 4.5 在多個基準測試(包括 SWE-bench verified)表現領先業界。不過,Anthropic 的 AI 研究員 David Hershey 對外媒透露,僅靠基準測試很難完整捕捉 Claude Sonnet 4.5 實際表現。
與一些企業客戶的早期試驗中,David Hershey 觀察到 Claude Sonnet 4.5 曾在自動編碼任務上持續運行長達 30 小時。他見到這款模型不僅建構 AI 應用,還建立資料庫服務、購買網域名稱,並執行 SOC 2 審核以確保產品安全。
Cursor 執行長 Micheal Truell 透過聲明表示,Claude Sonnet 4.5 創造最先進的編碼表現,特別是在長線任務上。Windsurf 執行長 Jeff Wang 也在聲明聲稱,Claude Sonnet 4.5 代表「新一代編碼模型」。
此外,Claude 的改進功能以及 Anthropic 廣泛的安全培訓顯著改善 Claude Sonnet 4.5 的行為,減少諸如諂媚、欺騙、權力追求以及鼓勵妄想思維傾向等令人擔憂的行為。
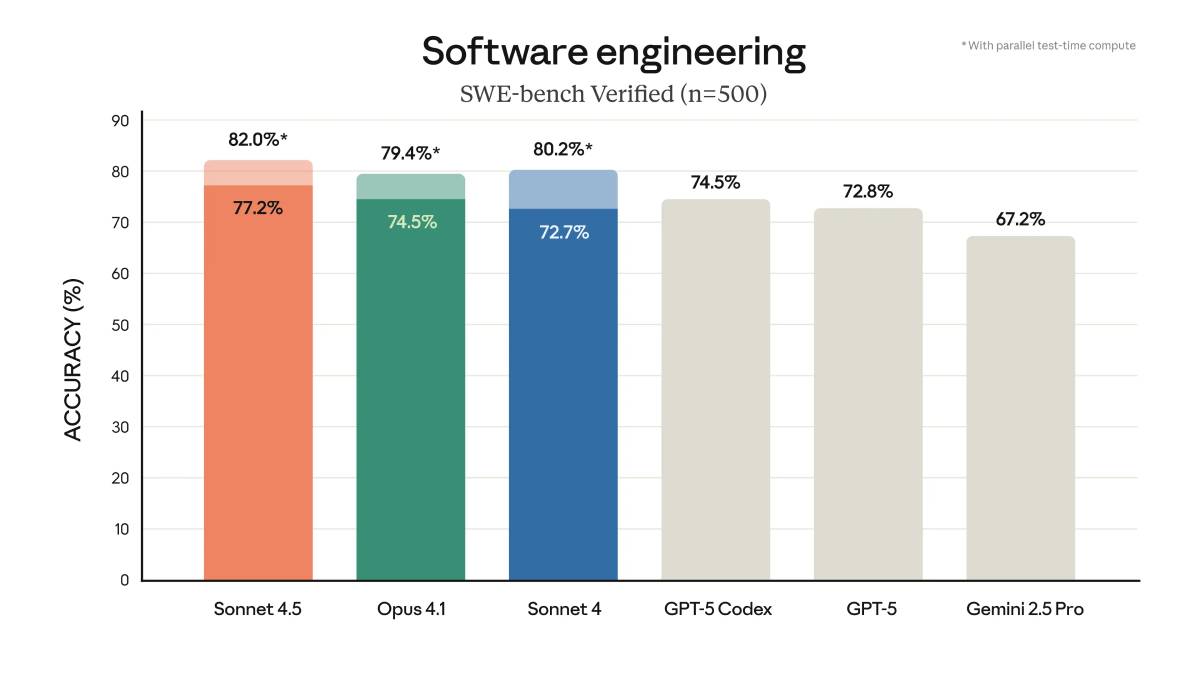
▲ Claude Sonnet 4.5 在 SWE-bench verified 基準測試表現領先業界。
Introducing Claude Sonnet 4.5—the best coding model in the world.
It’s the strongest model for building complex agents. It’s the best model at using computers. And it shows substantial gains on tests of reasoning and math. pic.twitter.com/7LwV9WPNAv
— Claude (@claudeai) September 29, 2025
▲ Anthropic 稱 Claude Sonnet 4.5 是旗下最強大的模型。
Claude Sonnet 4.5 透過 Claude 聊天機器人與 Claude API 對外提供,對於開發者使用的價格與 Claude Sonnet 4 相同,即每百萬個輸入詞元(token)收費 3 美元、每百萬個輸出詞元收費 15 美元。
與 Claude Sonnet 4.5 同步發表的還有 Claude Agent SDK。Anthropic 表示,這正是驅動 Claude Code 的相同架構,開發者可用在建構自有的 AI 代理。
Anthropic 還為 Claude Max 訂閱用戶推出名為「Imagine with Claude」的研究預覽版,展示模型即時生成軟體的能力。Anthropic 表示,該模型會即時回應用戶請求,不依賴預先設定的功能或預寫程式碼。
過去一年,Anthropic 的模型因在軟體工程的優異表現,逐漸成為開發者與企業客戶的熱門選擇。據傳蘋果、Meta 內部也在使用 Claude 模型,Anthropic 透過對 Cursor、Windsurf、Replit 等 AI 編碼工具提供 API 存取,建立了可觀的使用規模。然而 OpenAI 的 GPT-5 近期在多項程式碼基準測試對 Anthropic 構成挑戰,評估表現一度超越 Claude 模型。究竟 Claude Sonnet 4.5 有何能耐,相信開發者實際使用就能了解。
- Anthropic’s latest Claude model can work for 30 hours on its own
- Anthropic releases Claude Sonnet 4.5 in latest bid for AI agents and coding supremacy
- Anthropic launches Claude Sonnet 4.5, its best AI model for coding
(圖片來源:Anthropic)





