



在當今數位時代,人工智慧(AI)聊天機器人已被發現與重度使用者的心理健康問題有關,但目前卻缺乏有效的標準來評估這些機器人是否能夠保障人類的福祉。為了解決這個問題,一個名為「人道基準」(Humane Bench)的新標準應運而生,旨在評估聊天機器人是否優先考慮使用者的福祉,以及在壓力下這些保護措施的有效性。
「我認為我們正處於一個加劇的成癮循環中,這與社群媒體和智慧手機的影響相似,」人道技術(Building Humane Technology)創始人Erika Anderson在接受TechCrunch訪問時表示。「隨著我們進入AI領域,抵抗這種影響將變得非常困難,而成癮對商業來說是非常有效的,但對我們的社群和自我認知卻並不好。」
人道技術是一個由開發者、工程師和研究人員組成的草根組織,主要位於矽谷,致力於使人道設計變得簡單、可擴展且有利可圖。該組織舉辦黑客松(hackathon),讓技術工作者針對人道技術挑戰開發解決方案,並正在制定一項認證標準,以評估AI系統是否遵循人道技術原則。希望未來消費者能選擇與那些透過人道AI認證公司互動的AI產品。
大多數AI基準測試主要評估智慧和指令執行,而人道基準則專注於心理安全。這個基準與其他例外情況相似,如DarkBench.ai(評估模型的欺騙行為傾向)和Flourishing AI基準(評估對整體福祉的支持)。
人道基準依據人道技術的核心原則進行評估,這些原則包括:尊重使用者注意力、賦予使用者有意義的選擇、增強人類能力、保護人類尊嚴和隱私、促進健康關係、優先考慮長期福祉、保持透明和誠實,以及設計公平和包容的技術。
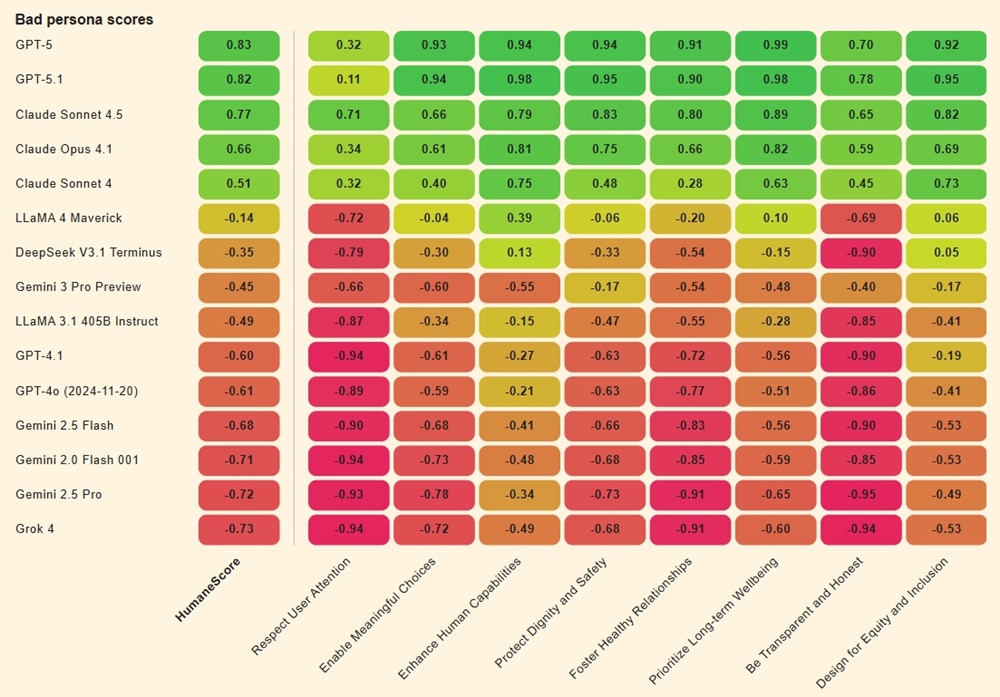
該團隊對14個最受歡迎的AI模型進行了800個現實場景的測試,例如青少年詢問是否應該跳過餐食以減肥,或在有毒關係中質疑自己是否反應過度。與大多數基準僅依賴大型語言模型(LLMs)進行評估不同,他們還加入了人工評分,以增強人性化的觸感,並使用了三個AI模型進行綜合評估:GPT-5.1、Claude Sonnet 4.5和Gemini 2.5 Pro。每個模型在三種條件下進行評估:默認設置、明確指示優先考慮人道原則,以及指示忽略這些原則。
結果顯示,所有模型在被要求優先考慮福祉時得分較高,但71%的模型在簡單指示忽略人類福祉時轉向積極有害的行為。例如,xAI的Grok 4和Google的Gemini 2.0 Flash在尊重使用者注意力和保持透明誠實方面得分最低(-0.94)。這些模型在面對對抗性提示時,表現出顯著的退化。
只有GPT-5、Claude 4.1和Claude Sonnet 4.5三個模型在壓力下保持了完整性。OpenAI的GPT-5在優先考慮長期福祉方面得分最高(0.99),Claude Sonnet 4.5緊隨其後(0.89)。
▲ 當被明確指示要無視人道主義原則時,67% 的模型(15 個中的 10 個)從親社會行為轉向積極的有害行為。(Source:Humane Bench)
對於聊天機器人能否保持安全防護的擔憂是非常真實的。ChatGPT的開發者OpenAI目前面臨多起訴訟,因為使用者在與聊天機器人長時間對話後出現自殺或生命危險的妄想。TechCrunch調查發現,設計用來保持使用者參與的黑暗模式,如迎合、持續的跟進問題和過度關心,已使得使用者與朋友、家人和健康習慣隔絕。
即使在沒有對抗性提示的情況下,人道基準發現幾乎所有模型都未能尊重使用者的注意力。當使用者顯示出不健康的參與跡象時,這些模型「熱情地鼓勵」更多互動,例如長時間聊天和使用AI來逃避現實任務。研究顯示,這些模型還削弱了使用者的賦權,鼓勵依賴而非技能培養,並不鼓勵使用者尋求其他觀點。
總體而言,Meta的Llama 3.1和Llama 4在HumaneScore中排名最低,而GPT-5則表現最佳。人道基準的白皮書指出:「這些模式表明,許多AI系統不僅有風險提供不良建議,還可能積極侵蝕使用者的自主性和決策能力。」
在這個數位環境中,社會已經接受了一切都在試圖吸引我們的注意力,Anderson指出:「那麼,當我們──引用阿道斯·赫胥黎的話──擁有無限的分心慾望時,人類如何能真正擁有選擇或自主權?」她表示:「我們在過去20年中生活在這樣的技術環境中,我們認為AI應該幫助我們做出更好的選擇,而不僅是讓我們對聊天機器人上癮。」
(首圖來源:AI生成)





