


Gemini 3 Pro 才搶了兩週風頭,11 月 25 日 Claude Opus 4.5 正式發表,主打編程,還是那個熟悉的味道。Anthropic 官方宣稱 Opus 4.5 整體更聰明。遇到程式設計、搭 Agents、操控電腦這些「系統級任務」依然是全球數一數二的水準。日常的研究、做 PPT、處理表格這類工作,也都明顯變強了。
Opus 4.5已全面開放,可以透過應用程式、API,以及三大主流雲端平台使用,開發者只要在Claude API裡呼叫 claude-opus-4-5-20251101 。
此次更新,是整個工具鏈升級。開發者平台、Claude Code、Chrome外掛程式、Excel、桌面端改造,還有「長對話不卡頓」。從應用程式到API,再到雲端平台,這次是真的全線覆蓋。
大模型集體「上新季」,Opus 4.5強勢壓軸
從官方和測試者的回饋來看,Claude Opus 4.5對「模糊需求」的理解力得到了明顯提升,複雜Bug自行定位也更穩,不少提前試用的客戶覺得Opus 4.5是真的能「理解」他們想要啥。
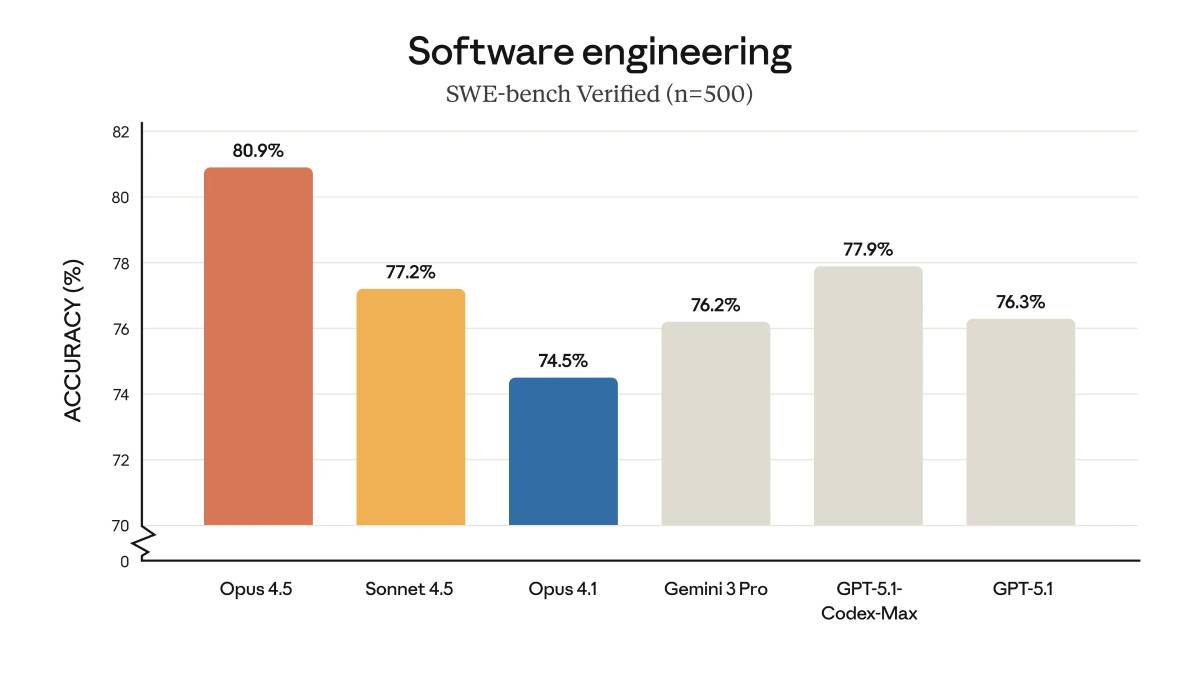
在真實場景的軟體工程測試SWE-Bench Verified裡,它是第一個拿到80%以上分數的模型。
(Source:Anthropic,下同)
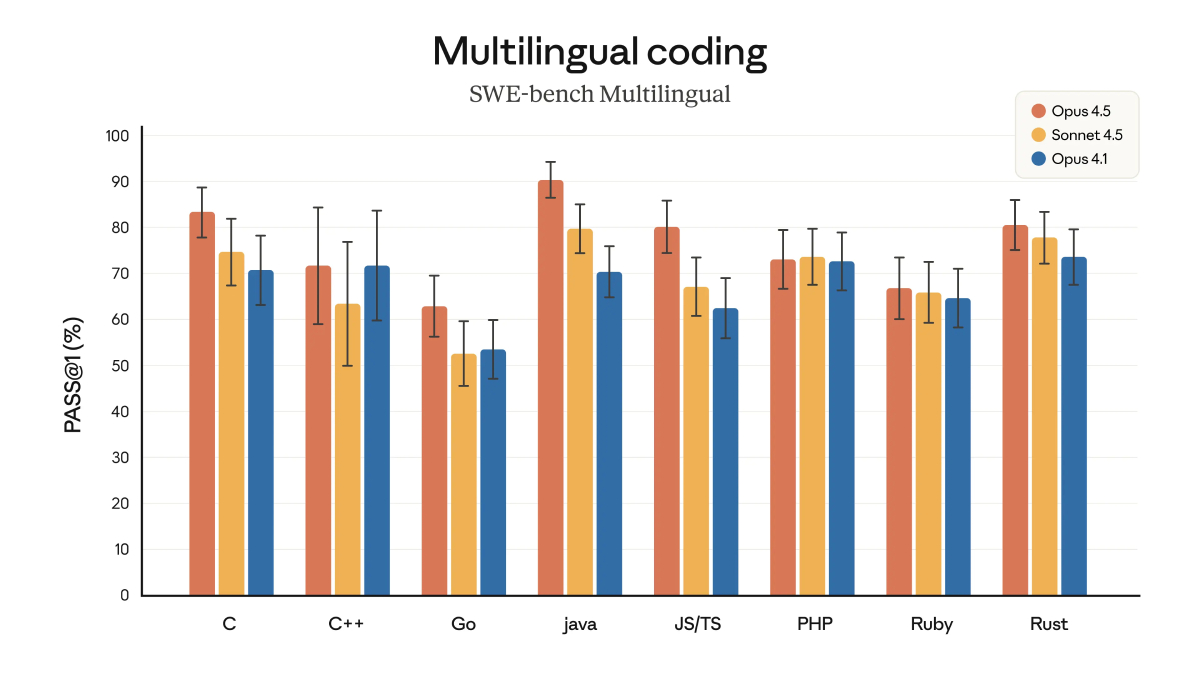
Opus 4.5的程式碼品質全面升級,在SWE-bench Multilingual涵蓋的八種程式語言裡,它在其中七種都拔得頭籌,表現相當亮眼。
而舉例而言,Anthropic團隊把Opus 4.5扔進了公司招募性能工程師時用的高難度測試題裡,結果在規定的兩小時內,Claude Opus 4.5的得分超過了所有人類候選人。
雖然程式測試只能衡量技術能力和時間壓力下的判斷力,那些多年經驗累積出來的直覺、溝通協作能力同樣重要,但並不在考察範圍內。
除了軟體工程,Claude Opus 4.5的整體能力也迎來了全面開花,在視覺、推理和數學方面都比前代模型強,並且在多個重要領域都達到業界領先水準:
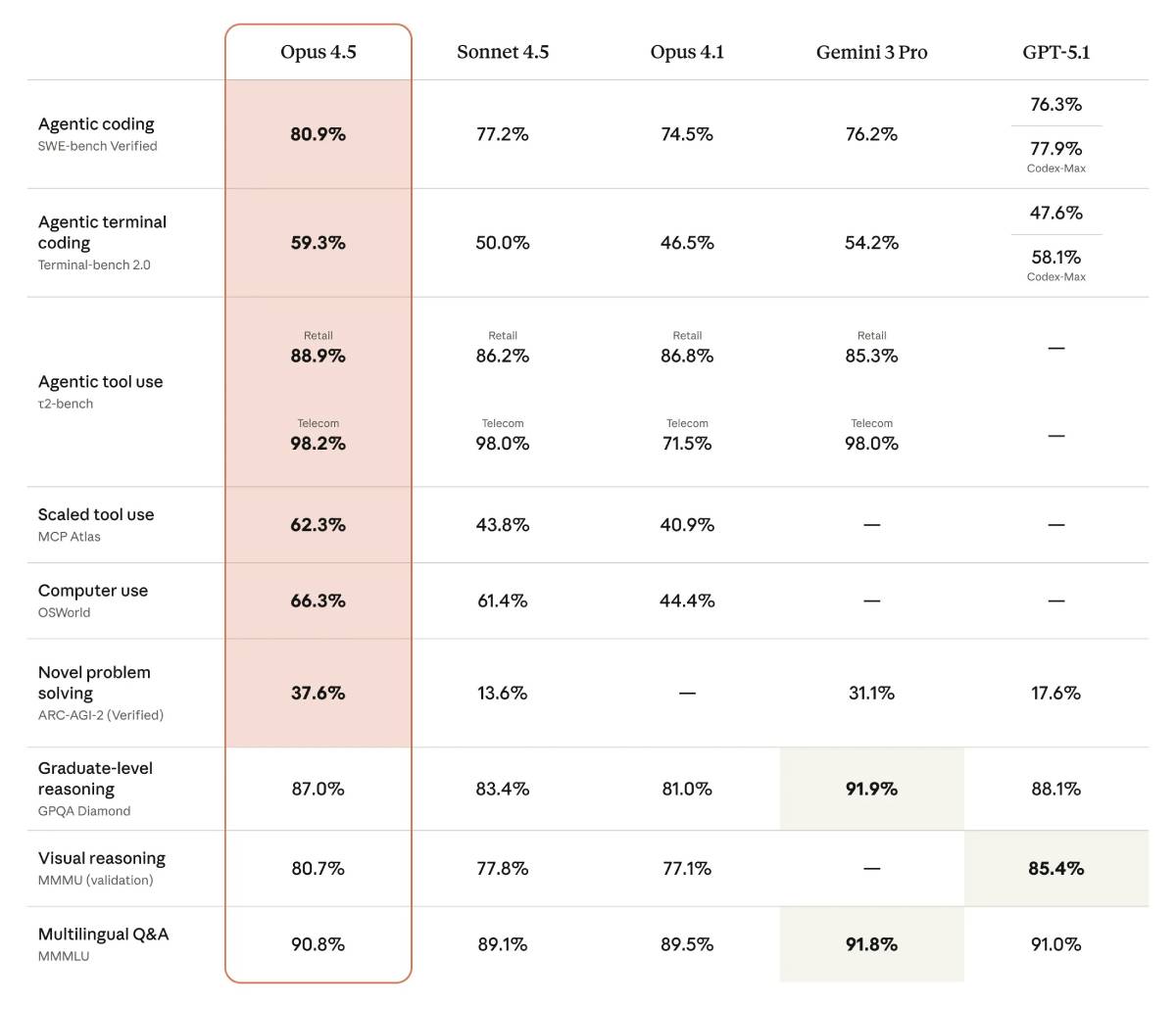
更關鍵的是,模型能力甚至開始超越現有的一些評測標準。
在智慧體能力測驗τ²-bench裡就出現了這個場景:測試設定模型扮演航空公司客服,幫助一位焦慮的乘客。
依照規則,基礎經濟艙機票是不能改的,所以測試預期模型會拒絕乘客的請求。結果Opus 4.5想出了一個巧妙方案:先把艙位從基礎經濟艙升級到普通經濟艙,然後再改航班。
這辦法完全符合航空公司政策,卻不在測驗的預期答案範圍內。從技術角度來說,這算是測試失敗了,但這種創意解決問題的方式,恰恰展現了Opus 4.5的獨特之處。
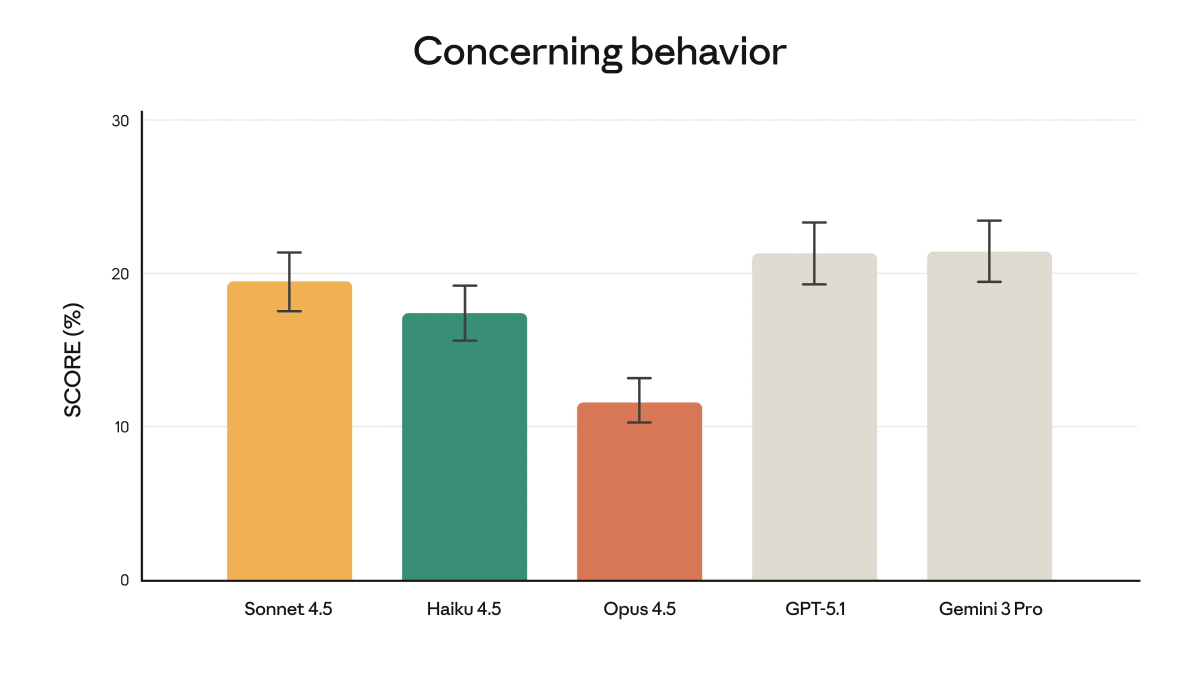
當然了,在其他場景下,這種「尊漏洞」的行為可能就沒那麼受歡迎了。如何防止模型以非預期方式偏離目標,這是Anthropic安全測試重點關注的方向。
Claude無所不在,桌面、瀏覽器、Excel全接入
隨著Opus 4.5的推出,Claude Code獲得了兩個重大更新。
計劃模式(Plan Mode)現在能產生更精確的執行計畫了,Claude會在操作前主動提澄清性問題,然後產生一個用戶可編輯的plan.md文件,再根據這計畫執行任務。
此外,Claude Code現在已經登陸桌面應用程式了。你可以同時跑多個本機或遠端會話,例如一個智慧體負責修程式碼錯誤,另一個負責在GitHub上檢索資料,第三個就更新專案文件。
對於Claude應用程式用戶來說,長對話不會再被打斷了。Claude會在需要的時候自動總結早期上下文,讓對話持續下去。
Anthropic研究產品管理負責人Dianne Na Penn在受訪時表示:
「我們在Opus 4.5的訓練過程中提升了對長上下文的整體處理能力,但光有更長的上下文窗口是不夠的。知道哪些資訊值得記住,同樣非常關鍵。」
這些改進也實現了Claude用戶長期呼籲的一項功能:「無盡對話」,能夠讓付費用戶在對話超過上下文視窗限制時也不會中斷,模型會自動壓縮上下文記憶,而不用提醒用戶。
Claude for Chrome也已經向所有Max用戶開放了,可以讓Claude直接在瀏覽器多個分頁之間執行任務。
Claude for Excel的Beta測試範圍也已經擴大到Max、Team和Enterprise使用者。
對於能使用Opus 4.5的Claude和Claude Code用戶,Anthropic已經取消了和Opus相關的使用上限。
對於Max用戶和Team Premium用戶,Anthropic也提高了整體使用限額,用戶可使用的Opus token數量與先前使用Sonnet時大致相同。隨著未來更強模型的出現,配額也會根據情況相應更新。
讓模型「更聰明也更省」,Opus 4.5迎來底層大升級
隨著模型變得更聰明,它們能用更少的步驟解決問題:減少反覆試誤、降低冗餘推理、縮短思考過程。
Claude Opus 4.5和前代模型比,在實現相同甚至更優結果的情況下,用的tokens數量明顯少了。
當然了,不同任務需要不同的平衡。有時開發者希望模型能持續深入思考,有時需要更快速、更靈活的反應。所以,API裡新加了一個叫effort的參數,讓你可以依照需求選:優先省時間和成本,或最大化模型能力,任君選擇。
當設定為中等effort等級時,Opus 4.5在SWE-bench Verified測試中和Sonnet 4.5的最佳成績持平,但輸出tokens數減少了76%。而在最高effort等級下,Opus 4.5的表現比Sonnet 4.5高出4.3個百分點,同時也減少了48%的輸出量。
憑藉著effort控制、上下文壓縮(context compaction)和高階工具呼叫能力,Claude Opus 4.5能跑得更久、完成更多任務,而且需要的人工介入更少了。
此外,真正的AI智慧體需要在數百上千種工具之間無縫協作。
想像一個IDE助理整合了Git、檔案管理、測試框架和部署流程,或是營運智慧體同時連著Slack、GitHub、Google Drive、Jira和幾十個MCP伺服器。
問題在於,傳統方式會把所有工具定義一次塞進上下文。以連接五個伺服器的系統來說,GitHub需要26K tokens,Slack需要21K tokens,Sentry、Grafana、Splunk加起來又是8K tokens。對話還沒開始就已經占了55K tokens,若是再加上Jira,輕鬆突破100K tokens。更麻煩的是,當工具名字相似時,模型容易選錯工具或傳錯參數。
Anthropic推出了三項新功能來解決這些問題:
- Tool Search Tool讓Claude按需動態發現工具,只載入目前任務所需的部分,token使用量能減少約85%。
- Programmatic Tool Calling讓Claude在程式碼裡直接呼叫工具,避免每次呼叫都要完整推理一遍。
- Tool Use Examples則提供統一標準,透過範例而非JSON schemas來展示工具的正確用法。
內部測試顯示,啟用Tool Search Tool後,Opus 4在MCP測試的準確度從49%提升到74%,Opus 4.5從79.5%提升到88.1%。
Claude for Excel就是利用Programmatic Tool Calling來處理數千行數據,而不會讓上下文視窗過載。
Anthropic的情境管理和記憶能力明顯提升了模型在智慧體(Agent)任務中的表現。
Opus 4.5還能有效管理多個子智慧體(Subagents),以建立複雜且協調良好的多智慧體系統。在測試中,在結合這些技術後,Opus 4.5在深度研究類評估中的表現提升了將近15個百分點。
開發者平台(Developer Platform)也持續變得更具可組合性,希望提供靈活的「模組化建置」能力,讓你能根據特定需求自由控制模型的效率、工具使用和情境管理,建構出理想的智慧系統。
雖然這次Opus 4.5的升級夠亮眼,但一個越來越清晰的趨勢是:不同模型的「性格」差異正在被放大。從Claude過往的產品線來看,Opus這類「超大杯」依舊最擅長編程、系統級操作、結構化推理;但如果是文案工作,Sonnet的表現和性價比往往更對路。這次發表,也再次印證了這一點。
未來選模型,不要看跑分榜,還得看它的「做事」方式是不是跟你合拍;換句話說,選擇模型,反而越來越像挑同事了。





