



年初 Mac Mini 一度缺貨,等待時間甚至長達一個半月。
Mac mini 是好產品,這件事大家一直很清楚。價格誠意高,M 晶片性能又好,入門款不到 2 萬元就可擁有,很適合當創作新手的主力機。然最近 Mac mini 爆紅,與創作或日常使用沒什麼關係。
關注科技新聞的讀者應該都知道原因:OpenClaw(之前叫 Clawdbot)爆紅。
OpenClaw 有多種部署方式:可以裝在自己的電腦,也可以配成專用電腦;部署在雲端的虛擬器/沙盒環境也沒問題。後來主流 AI 服務也推出雲端一鍵部署替代方案,降低 AI 小白門檻。但剛開始最快方法就是買一台 Mac mini。
理由一定不是因為便宜,更在要讓 OpenClaw 有意義,需要給它「肉身」,讓它存取檔案、操作軟體。雲端伺服器能跑 OpenClaw,但仍不是自己的電腦,沒有檔案、軟體、瀏覽器登錄的各種帳號,沒有所謂「上下文」。Mac mini 放在桌上,7×24 小時不用關機,甚至遠端操控聊天機器人連螢幕都不用。
給 OpenClaw 專用電腦,唯一可觀成本是後端接入的大模型 API 的 token 費,很多早期玩家都在這吃過虧。但如果再買規格夠高的 Mac mini,下載夠大的模型到本端運行,除了電費和網路費,簡直就是個免錢助理。
Sticky note, $0.01 fix pic.twitter.com/YQnXUSIZLG
— Ratchet&Clanker (@clankerdaddy) February 26, 2026
MacBook 也行,但是……
Tom′s Hardware 和 TechRadar 等外媒報導,OpenClaw 爆紅後,Mac mini 24GB 和 32GB 等待期延至六天到六星期;更高規格的 Mac Studio 交貨時間也從兩星期漲到兩個月。這些等待時間,是 OpenClaw 早期玩家用真實購買投的票(部分機型缺貨也和蘋果近期推出新款 Mac 桌機有關,以往每次臨近新機發表,舊機都會進入售罄狀態。OpenClaw 爆紅並非唯一原因)。
Mac 就這樣默默成為 2026 年首選的「AI PC」,反倒是鼓吹「AI PC」幾年的 Windows PC 一點屑屑都沒吃到。英特爾、AMD、高通等及主流 PC 品牌,2023 年就開始賣「AI PC」概念了,最新 Windows 電腦認證 Copilot+ PC 的比比皆是,GPU、NPU 性能也不差,有的整機價格比 Mac 同級產品更便宜。
但問題是,為什麼大家還是一窩蜂衝向 Mac?
為什麼是 Mac?
Windows PC 和 Mac 誰更好的爭論,永遠沒有絕對答案,但如果限定 AI 開發,Mac 就是心照不宣的選擇,雖然大模型「大腦」都在雲端伺服器,開發者的手卻都在 Mac 上。這跟 Mac 外形和操作體驗關係不大:macOS 流著 UNIX 的血,才是關鍵。
AI 代理的核心工作是操作檔案、調用命令行工具、調度 API 甚至控制圖形介面等,更直白點,代理就是智慧且自動化的「腳本工程師」,只是腳本由大語言模型即時產生。macOS 屬類 UNIX 系統,原生就支援 bash、zsh 指令。
這解決 AI 開發最基礎的環境搭建。Windows 系統可能得先安裝 WSL2 虛擬機,但 Mac 從 Python 環境到複雜的 C++ 編譯工具鏈,都是開箱即用。Homebrew 等包管理器,讓安裝各種工具和依賴一行指令就能搞定。
另外,macOS 符合 POSIX 標準,處理檔案路徑、多線程任務和網路協定時可靠性稍高。AI 代理往往需頻繁讀寫數據、調用 API,系統級高效調度讓代理在 Mac 跑的節奏更快。這種原生感和穩定性,讓開發者、嘗鮮使用者更快入門,時間真正花在編排代理。
Windows 有 WSL、PowerShell,功能大部分也涵蓋。但 WSL 是疊加在 Windows 上的相容層,還有路徑約定、登錄表機制、許可權模型等歷史遺留問題。 AI 模型和代理專案在 Windows 執行的摩擦力確實更高。
以 Ollama 和 LM Studio 為例,讓端側推理大模型變得像「下載、安裝、運行」簡單。Ollama 的 Windows 版比 macOS 晚了半年;LM Studio 雖然一開始就支援兩平台,但社群的 Mac 口碑始終更好,OpenClaw 也是如此。
往硬體層面繼續深入,記憶體是大語言模型推理運行的命脈。
還是以 OpenClaw 舉例,用戶可 token 付費接入雲端模型,但它更擅長端側模型推理驅動。經過普遍研究,想讓 OpenClaw 像智商合格的人工作,後端模型參數量底線約 70 億,往往要上到至少 320 億參數量才能較穩定運作。
這麼大的模型即便 4-bit 量化後,仍需約 20GB 記憶體(還要留一些給上下文視窗),Windows PC 的架構會顯得捉襟見肘。CPU 記憶體和顯示記憶體有物理隔離,數據經 PCIe 總線傳輸,受頻寬瓶頸影響。頻繁數據搬運,會影響推理速度。
更別提大模型普遍靠 GPU 加速推理,顯示記憶體得夠大到裝得下模型。輝達消費級顯卡,只有 90 結尾的 24GB 達到要求,但配成整機(只考慮新機)的話合計成本至少 6 萬元,用新顯卡更會飆破十萬元甚至超過 20 萬元。
蘋果統一記憶體架構 (Unified Memory Architecture)讓 M 系列晶片 Mac 的終端推理更大模型時游刃有餘。簡單說,統一記憶體架構效果,是 CPU、GPU、神經計算引擎共用同個記憶體池,不再有物理總線搬運損耗,讓 Mac 獲得極高記憶體頻寬,並多機串聯擴展性能更好。
以 Mac mini 為例,選擇性能更高的 M4 Pro 處理器,搭配 48GB 記憶體,其他選基礎就好,整機價格 萬元,即可達 OpenClaw 社群普遍推薦的 320 億參數量模型水準。當然這還只是對 token 吞吐速度有要求的專業規格,如果只是愛好者、嘗鮮玩一下 OpenClaw,降到常規 M4 晶片和 32GB 記憶體也能跑。
這成本比較還是有前提:專用終端推理跑 OpenClaw,而不是當成主力機。同價位 Windows PC 還能玩遊戲、剪影片,實用性更高。
另外,Mac 統一記憶體和 PC 平台獨顯記憶體也不是同一回事。統一記憶體由系統和模型共用,32GB 記憶體的 Mac mini,macOS 系統和其他軟體仍需佔幾個 GB。RTX 3090 記憶體獨立,模型可全部佔用,甚至配合 CPU 記憶體跑更大的量化模型。
如果你只用雲端 API 當 OpenClaw 大腦,不考慮終端部署,那 Mac 的易用性優勢依然在。CUDA 雖提供統一記憶體程式設計介面,但物理上 CPU 記憶體和 GPU 記憶體各自獨立,數據搬運和頻寬瓶頸並未消除。
再來看功耗。
AI 代理工作方式是個迴圈:任務觸發、思考推理、執行、等待、再觸發。上述 Windows PC 會跑到 300~400W 左右(本地部署),散熱噪音和電費都不是小數目。Mac mini 通常穩定功耗 10~40W,峰值功率 65W(M4)或 155W(M4 Pro),散熱可控,幾乎沒有風扇噪音,運行更安靜。這種低延遲、低功耗的持續工作方式,會產生不知不覺的體驗差異。

▲ 網友 3D 列印的 Mac mini 外殼套件「Clawy MacOpenClawface」。
當然本文還是圍繞 OpenClaw 這以推理為主的 AI 討論,如果工作涉及本地微調,且對效率有追求,那 macOS 平台要往往要上到 Mac Studio 或至少頂配 MacBook Pro,才能算摸到門檻。Mac 不支援 CUDA 也是可能永遠無法改變的事實,但 CUDA 的真正戰場是模型訓練,推理場景少得多,畢竟蘋果推理有 MLX 這張王牌(之後會詳述)。
再回到 OpenClaw:創造者 Peter Steinberger 表示很喜歡 Windows,覺得功能更強。他在 Lex Fridman Podcast 說,Mac mini 不是唯一「肉身」選擇,以 WSL2 跑 OpenClaw 已非常成熟,他甚至公開吐槽蘋果 AI 領域「搞砸了」,且對蘋果生態封閉性很不滿。
Please don’t buy a Mac Mini, rather sponsor one of the many contributors of @clawdbot
You can deploy this on Amazon’s Free Tier. https://t.co/RoZPoAnNTo https://t.co/BofjbKlAcg
— Peter Steinberger 🦞 (@steipete) January 25, 2026
但客觀講,技術小白的部署門檻,Mac mini 確實是最省事、最容易上手的方案,主因就是功耗、靜音、體積夠小,就像只要一牆角就夠放、24 小時待機且不需要維護的「伺服器節點」。
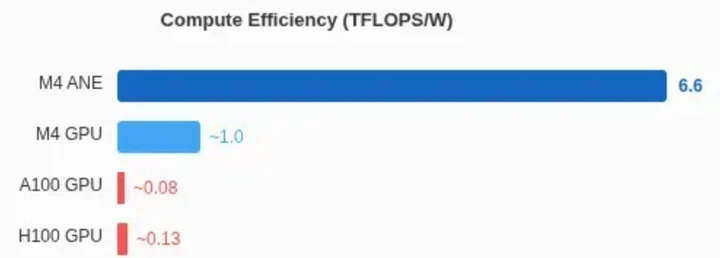
還有一個和功耗有關的例子:工程師 Manjeet Singh 成功逆向工程 M4 處理器「神經引擎」(Neural Engine,ANE),發現 ANE 功耗效率極高:算力跑滿時效率高達 6.6TOPS/W。蘋果 M4 GPU 約 1TOPS/W;輝達 H100 約 0.13TOPS/W,A100 是 0.08 TOPS/W。
折算 A100 單卡吞吐性能是 M4 ANE 的 50 倍,但 M4 ANE 功耗性能卻是 A100 的 80 倍。Singh 文章說:對終端推理,ANE 性能非常出色。
從神經引擎說起
2011 年蘋果 A5 處理器圖像處理單元(ISP)首次以硬寫入,做到臉部即時檢測等後來視為 AI 任務的功能。2014 年蘋果收購 PrimeSense,研發全新、神經網路計算專用的處理器。三年後 iPhone X 問世:A11 Bionic 處理器加入前面提到的神經引擎 ANE,算力只有區區 0.6TOPS,就可驅動 Face ID 和拍照人像模式。
AI 還沒進入大模型時代,主要跑各種機器學習演算法。市場對蘋果處理器沒什麼特別反應,但蘋果從未放棄,持續加碼。三年後 M1 發表,統一記憶體架構同時到位,ANE 也進駐 Mac,桌機功率預算更充足,也讓 ANE 算力跳到 11TOPS。之後每代更新:M2 是 15.8TOPS,M3 是 18TOPS,M4 是 38TOPS,到 2025 年底 M5 達 57TOPS,從 M1 到 M5,蘋果 ANE 算力漲超過五倍。
其他 PC 廠商當然很羡慕。蘋果為 Mac 加入 AI 加速硬體前,已有數千萬甚至上億台 iPhone 跑同一套 ANE 架構,功耗表現、穩定性、極端情形的邊緣案例,市售機早已驗證,再搬上 Mac。
英特爾和 AMD 行動端幾乎沒有消費級規模,高通雖然也把 Snapdragon 晶片放進數億台 Android 手機,但依舊只是晶片供應商。Android 的 AI 是 Google Gemini 及各大手機廠商聯合第三方 AI 實驗室做的,Windows 的 AI(Copilot)是微軟生的。
蘋果不同在於,做到垂直整合,同時掌控硬體和軟體,其他晶片廠商沒有這種統一控制權,當然 Mac 跑推理大模型和 ANE 沒什麼關係,它更擅長處理 Face ID、人像辨識這類固定模式 AI 任務,真正承擔主要計算量的是 GPU。
最近情況又有細微變化。首先,M 系列晶片 ANE 已承擔提示詞注入 prefill 工作,以及剛提過的 M4 ANE 逆向工程:工程師還跳過 CoreML 直接調用 ANE,輸送量大舉提升。或許可用這種方法找到直接利用 ANE 加速推理甚至訓練的通用法。
2023 年底蘋果開源 MLX,把 M 系列晶片專用最佳化模型推理框架直接開放給開發者。去年基礎模型框架和 Apple Intelligence 一起發表,App 開發者可用 iPhone 和 Mac 調用內建基礎模型,無需連網,數據不離開設備。
Apple Intelligence 一再跳票沒什麼好說,但蘋果遠在十年前就開始試水,幾年前就為桌面級 AI 開發打下基礎,也是事實。但 Windows 方「AI PC」出現在英特爾、AMD 和 PC 廠商新聞稿和 PPT 是 2023 年底才開始的。
2024 年 5 月,微軟發表 Copilot+ PC 認證體系,旗艦功能名叫「Recall」,邏輯是系統會持續截圖螢幕,Windows 系統級 AI 就能幫你回憶過去看過的東西。先不說發表當時的意義是什麼,安全性首先就有嚴重問題:發表一個月後,研究員就發現 Recall 會把所有截圖存在未加密的本端明文資料庫。
微軟緊急撤下 Recall 功能。過半年後微軟再推測試版,再次因新安全問題延期。直到 2025 年 4 月,Recall 才上線,但改成預設關閉,啟動後資料加密存儲。
從發表會到真正能用近一年,可說整個 Windows 生態 AI PC 的旗艦功能砍掉重練,尷尬程度其實不亞於 Apple Intelligence/新 Siri 一跳再跳,但可能因 Windows 生態聲量太低,AI PC 沒多少人關注,很多人都沒聽過這回事。
Copilot+ PC 體系認證標準,微軟注重神經處理引擎 NPU,要求 40TOPS,但算力用途是即時字幕、背景虛化、照片增強,諸如此類的消費端小任務,大語言模型推理從來不在它的射程範圍(同理蘋果 ANE)。當開發者嘗試做終端大語言模型推理,會發現雖然這些電腦名為 AI PC,但並沒最佳化 AI 推理用途。微軟 Copilot 本身核心算力來自 Azure 雲端,和終端算力幾乎無關,買了 Windows AI PC 的使用者,最有感的 AI 提升,大概只有即時字幕和照片自動分類。

說到終端推理,還有一個關鍵因素:Windows AI 生態最佳化路徑很分散。
NVIDIA GPU 用 CUDA 和 TensorRT,英特爾 NPU 用 OpenVINO,高通 NPU 用 QNN SDK,AMD NPU 用自家驅動棧。模型存儲格式也很零碎,有 CPU+GPU 推理的通用格式(GGUF,準確說是 CPU 推理+GPU 分層卸載),也有 GPU-only 格式(EXL2)。
這代表想讓模型與模型驅動的功能在 Windows AI PC 跑,推理後端工作就會更複雜。微軟有 ONNX Runtime 和 DirectML(已進入續命狀態)為統一抽象層,但統一的代價是犧牲各廠商的峰值性能。蘋果是唯一為自家 PC 硬體專門開發並持續維護 LLM 推理框架的電腦廠商,框架就是 MLX。
Hugging Face 等開源模型平台,很容易就能找到大量採 MLX 框架的模型,只要帶有 MLX 副檔名,並記憶體/處理器允許,就是「開箱即用」。不過這幾天 MLX 主要貢獻者之一 Awni Hannun 剛從蘋果離職,為專案後續發展增添變數。Hannun 也表示 MLX 團隊仍有許多優秀員工,大家可以放心。
Today is my last day at Apple.
Building MLX with our amazing team and community has been an absolute pleasure.
It’s still early days for AI on Apple silicon. Apple makes the best consumer hardware on the planet. There’s so much potential for it to be the leading platform for… pic.twitter.com/lFR7GZx1VF
— Awni Hannun (@awnihannun) February 27, 2026
我們自己的體驗
過去一年,愛范兒做了不少終端部署 AI 模型測試,也採訪相關外部開發者。有兩件事值得一提。
去年開春 DeepSeek 橫空出世,新 Mac Studio 不久後上市。愛范兒用一台售價快 10 萬人民幣的 M3 Ultra Mac Studio(512GB+16TB)跑 DeepSeek-R1 671B 模型(其實只要記憶體,硬碟不用那麼大,1TB SSD 售價 7 萬多人民幣型號就夠了),以及蒸餾過 70B 版本。
當時結論:終端部署對話,日常用 70B 足矣,花幾萬買台機器只為了跟 AI 聊天,當真是錢太多。當時模型能力確實不太行,後來才有新多模態模型和代理出來。但 671B 模型的天量參數模型能一台桌機推理,仍是個奇觀。512GB 統一記憶體,671B 模型佔了 400GB,加上上下文、macOS 系統本身及其他任務佔用,基本近滿載,但機器全程非常安靜,噪音也是正常範圍,不會過熱。
這個參數規模,傳統 AI 基礎設施邏輯屬資料中心等級,消費級硬體理論上不會出現,但那台 M3 Ultra Mac Studio 就硬生生也靜悄悄上場了。
之後愛范兒採訪英國牛津大學創業團隊 Exo Labs,用四台 512GB 統一記憶體 Mac Studio,串聯組成 128 核 CPU、320 核 GPU、2TB 統一記憶體、總記憶體頻寬超過 3TB/s 的算力集群。團隊為 Mac 集群開發調度平台 Exo V2,可同時載入兩個 DeepSeek 模型(V3+R1,8-bit 量化),不但兩模型並行推理,甚至可用 QLoRA 做一些本地微調,縮短訓練任務耗時。整套系統功耗控制在 400W 內,運行時同樣幾乎沒有風扇噪音。

同等算力的傳統方案,需約 20 張 NVIDIA A100,當時成本超過 200 萬人民幣;Exo Labs 方案總成本才不過 40 萬人民幣(同理 SSD 嚴重溢出,其實可以 30 萬人民幣就夠)。
Exo Labs 創辦人告訴愛范兒,牛津有自己的 GPU 集群,但需要好幾個月前申請,且一次只能申請一張卡。這些桎梏逼迫他們創新,又正好遇到趁手的工具:統一記憶體架構、MLX 及 Mac 電腦。採訪文說:「如果說輝達 H 系顯卡是 AI 開發的金字塔頂端,那 Mac Studio 就是中小團隊的瑞士刀。」
這件事,蘋果其實早就知道。

真正的 AI PC 是什麼?
去年蘋果發表基礎模型框架,讓 iOS 和 macOS 開發者可調用系統內建基礎模型,零網路延遲,零 API 費用,數據不離開設備。儘管後來蘋果基模團隊幾近分崩離析,但反覆運算方面蘋果沒有停在原地,一直知道開發者在哪裡、想要什麼。蘋果回應就是將大模型驅動的 AI 變成操作系統的基礎設施,讓開發者更方便調用。
前幾日蘋果開源 python-apple-fm-sdk,以往蘋果基模完整測試和最佳化,需 Swift 環境完成,現在這套 SDK 讓路變寬,習慣 Python 工作流的開發者也能參與。蘋果隱私設計哲學貫穿始終:python-apple-fm-sdk 調用的基礎模型完全本端運行,數據不離開設備。蘋果整套 AI 體系在必須上雲端的場景,走的是 Private Cloud Compute,數據處理完即刪除,蘋果無法存取。
反過來看微軟 Recall,同樣是讓 AI 存取使用者資料,第一版存在未加密的明文資料庫,一個架構阻斷洩密,一個是出事再修補。但話說回來,Mac 的 AI 開發和部署工具優勢,更像「相容度優勢」,也可以說是後天意外獲得。
意思是:蘋果做神經引擎,最初是為了服務 Face ID 和人像模式;做統一記憶體架構,是擺脫英特爾的必要工作;開源 MLX,是回應開發者對高效推理工具的需求──AI 代理爆發,Mac 正好趕上,是上述這些與更多沒提到的工程決策的意外收益。
Mac 一開始不是為 AI 設計,產品定位更接近「創作者工具」。蘋果主客群一直是影音工作者、藝術家、軟體工程師,他們需要低雜訊、持續性能、高記憶體容量、全天候運行的機器。
AI 模型推理及現在最紅的 AI 代理,只是恰好需要一樣的東西。
在M4 Max MacBook Pro上完整跑通了纯本地OpenClaw工作流,模型qwen3.5-35b-a3b四比特量化,~100 token/s,跟在线AI差不多,但我的所有数据和对话都不会离开自己电脑,然后我就成了全世界最后一个知道伊朗出事了的人,恍如隔世 pic.twitter.com/yV3MJJZC5x
— 林亦LYi (@linyiLYi) March 1, 2026
回頭看,十幾年前蘋果增加投資機器學習時,大概也沒預見 2025 年有個 OpenClaw 會爆紅。甚至十年前蘋果也不喜歡 OpenClaw 這種「回報高風向更高」,一旦出現幻覺就把用戶隱私、數據安全拋在腦後,無視各種軟體工程規章制度的東西。
但如今就算蘋果不喜歡它也不行。就像莫非定律,冥冥之中有些事早已注定。多年前蘋果打的每張牌,無論有意還是意外,今年這代理元年(希望這次是真的),成為很難不贏的牌組。2023 年開始力推 AI PC 的 Windows 陣營,還在追趕蘋果 2020 年 M1 就確定的架構優勢。當然 2025 年蘋果 AI 壞消息不斷,這差距有追上的可能,但蘋果當然也不會停下腳步。
最近蘋果推出 M5 Pro 和 M5 Max,採雙核心融合架構 (Fusion Architecture),新聞稿更點名 LM Studio 為 LLM 性能基準。蘋果過去硬體新品發表時不怎麼說「大語言模型」,特別是終端推理語境──現在就不一樣了。
說在最後
吹了蘋果整篇文,要冷靜一下,標題的答案為何?愛范兒還認為蘋果做得不夠多,還沒看到個人計算產品可稱之為 AI PC,或真正「原生的 AI 硬體」。回到 OpenClaw,今日從終端部署代理看到,真正 AI PC 應該長什麼樣子,已隱約可見。
應用層面,人類「應用」概念可能部分退化回無圖形介面時代。畢竟人類才需要圖形介面,AI 代理不需要。且你會發現,最近越來越多人開始習慣對話和下指令的互動方式了。今天 AI 代理的嘗鮮者,找工具和技能塞給代理,將來就是 AI 代理會自己去公開程式庫抓新工具和外掛程式補強。
系統層面,許可權體系將為 AI 代理工作原理重構,代理能直接操控各種介面。底層會有模型編排調度機制,根據任務隨時切換。本地推理和隱私雲端推理也會形成完整、安全、隱密的封閉環境。數據無論傳到哪裡,都經過向量化、加密存儲,即用即焚等等等。
換句話說,真正的 AI PC 應是從底層開始,設計之初就把 AI 當成「一等公民」的系統。
照這標準,Mac 和 Windows 都還是過渡品。Mac 較接近,因 Unix 環境、硬體統一、生態成熟,AI 代理出現前就已達成,Windows 歷史包袱更重,改起來更難,還在補課。但繞了一大圈,其實還沒問到最本質的問題:真正的 AI PC,還需要是實體「PC」嗎?
換個思路,所有 AI 代理部署和運行全在雲端,使用者相關數據,也即「上下文」都在雲端安全加密儲存,人類只需把終端設備當成「對話器」(communicator),以及感測器(sensor)用來拍照錄音上傳數據給代理,甚至不需太多終端算力。
Mac 是現在最好的 AI PC,但將來的「AI PC」卻可能更像……不就是 iPhone 嗎?





