



3 月 17 日,日本樂天集團(Rakuten)在日本經濟產業省(METI)GENIAC 計畫(Generative AI Accelerator Challenge)的支持下,高調發表了號稱「日本最大、性能最強」的 7,000 億參數大模型 Rakuten AI 3.0。但發表後不久,就被開源社群發現該模型的底層架構其實來自 DeepSeek V3,樂天只是做了日文資料的微調。
在知名的AI開源程式庫Hugging Face上,Rakuten AI 3.0赫然在自己的設定檔裡面寫著架構來自DeepSeek V3。
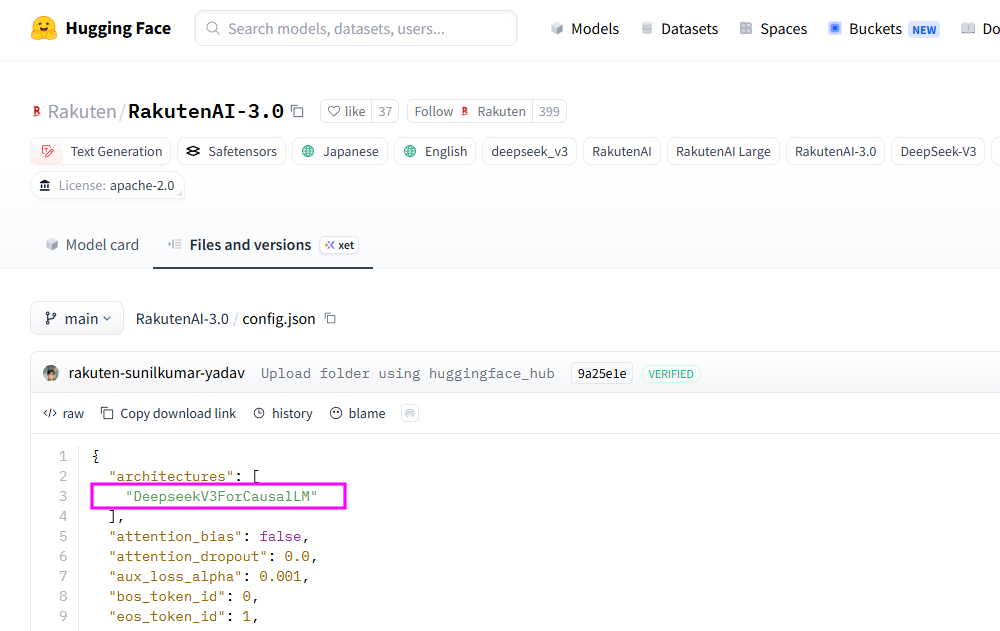
(Source:Hugging Face)
而在Rakuten AI 3.0模型的發布新聞稿裡,絲毫沒有提到任何關於DeepSeek的資訊,只是含糊的說「它融合了開源社群的精華」,讓網友們誤以為這款模型是日本自主研發的。
更致命的是,樂天為了掩蓋這個事實,在開源時偷偷刪除了DeepSeek的MIT開源協議文件。在被社群實錘後,才灰溜溜地以「NOTICE」檔名重新補上。
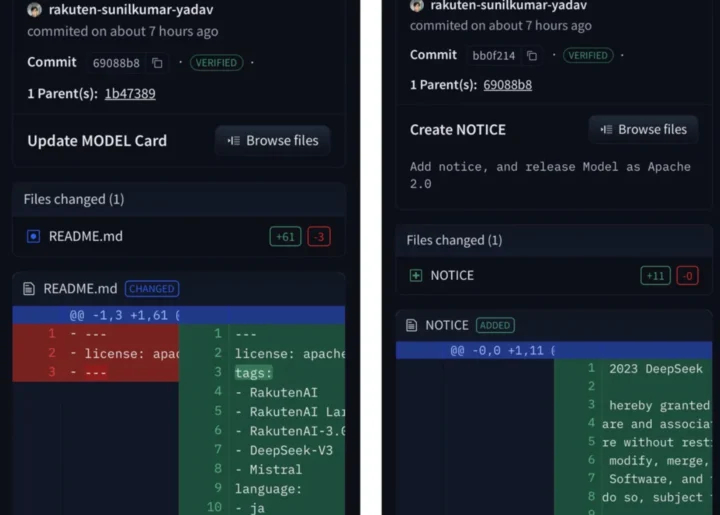
▲ 在Hugging Face上能看到專案文件的提交歷史顯示修改。
日本網友紛紛表示,「這讓人無法接受」,拿著日本政府補貼,竟然只是微調了中國的DeepSeek,還有人說,用DeepSeek就算了,還要偷偷藏藏真的很遜。
掩耳盜鈴的「日本最強」
單看Rakuten公司發布的公關稿,這個模型確實算得上是日本在LLMs領域的一次比較有實力的發表。
這是一款擁有約7,000億參數的混合專家(MoE)模型,經開源社群確認,是和DeepSeek V3一樣的671B總參數,啟動37B。樂天首席AI長Ting Cai將其形容為「數據、工程和創新架構在規模上的傑出結合」。
Ting Cai這名字一聽就不像是日本當地人,有日本網友在評論區說,用DeepSeek很過分,更過分的是,主導這個模型的大老闆,是個徹頭徹尾的移民強硬派。

▲ 樂天首席AI長Ting Cai。(Source:樂天)
Ting Cai曾在美國Google、蘋果公司工作過,並在微軟待了超過15年,本科在美國石溪大學電腦科學就讀。他曾在訪談中表示,18歲他第一次出國就是日本,確實是個「移民強硬派」。
關於Rakuten AI 3.0的模型表現,在官方公布的各項基準測試中,它在日語文化知識、歷史、研究生水平推理、甚至競技數學和指令遵循等維度上,得分表現都極其優異,大有橫掃日本本土大模型圈的架勢。
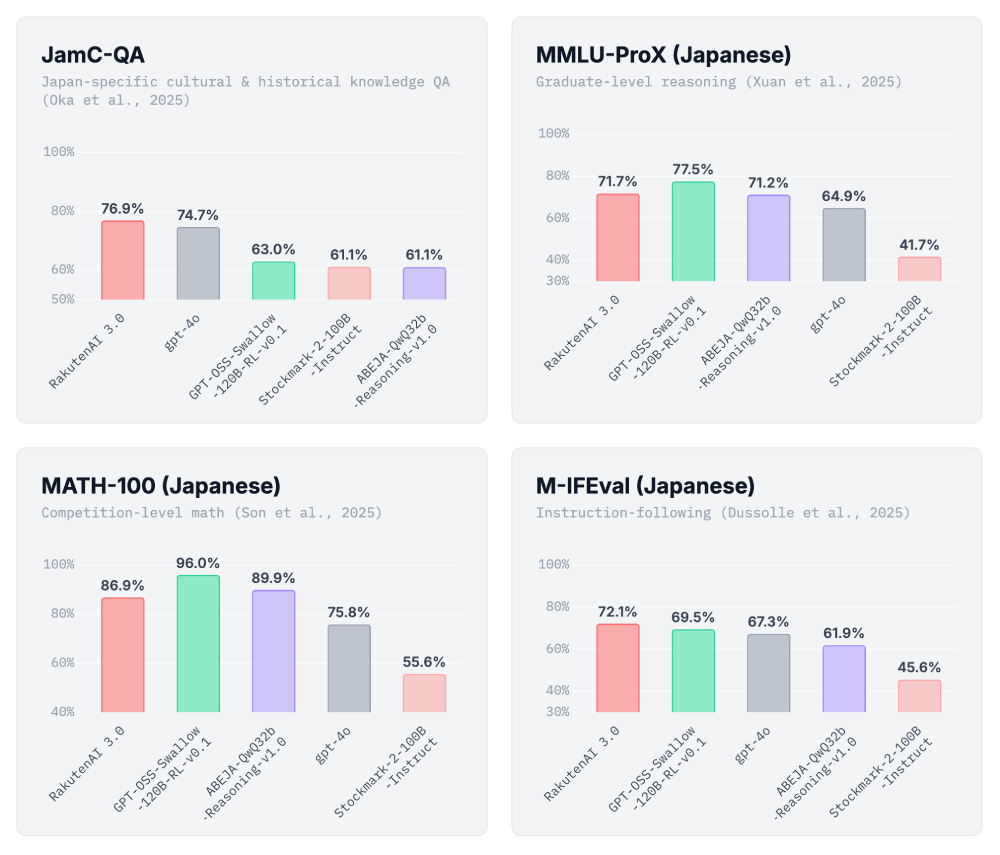
(Source:樂天)
不過,用來比較的模型,是已經被下架了的GPT 4o、只有1,200億參數的GPT OSS,還有日本的新興AI開發企業ABEJA基於千問推出的ABEJA QwQ 32b模型。
7,000億和最多1,200億比,Rakuten AI 3.0確實是贏了不少。同時做為經產省GENIAC計畫的重點資助對象,樂天獲得了大量的算力資源支持。 GENIAC這個計畫設立的初衷,正是為了建立日本本土的生成式AI生態,緩解對海外巨頭科技依賴的焦慮。
日本最大的參數規模,再加上這層「國家隊」的濾鏡,讓Rakuten AI 3.0一出場就戴上了「全村希望」的光環。
還得是DeepSeek
但光環褪去得比想像中更快。
先不說7,000億參數、MoE架構,這幾個關鍵字組合在一起,在現今的開源大模型圈裡,指向性實在太強了。等到開源社群的開發者們,到Hugging Face上一看詳細的程式碼設定文件,竟然直接就寫著DeepSeek V3。
從底層邏輯來看,這就是「中國架構+日本微調」。 DeepSeek提供了那套被全球驗證過、極其高效的底層架構和推理能力,而樂天則利用本土優勢,用高品質的日文語料對其進行了微調,讓它變得更懂日本文化。
客觀來說,拿開源模型做本土化微調,在技術圈是一件極為正常且合理的事。就像他們拿來當比較的ABEJA QwQ 32b模型一樣,連代號都不改,直接用Qwen的QwQ。
如果樂天這次也坦坦蕩蕩地承認使用了DeepSeek的底座,頂多是一次缺乏新意的「套殼」發表,興許還能蹭DeepSeek的熱度,但他們偏偏選擇了掩藏。
開源許可證有許多種,而DeepSeek採用的MIT協議,堪稱開源界「最卑微、最寬容」的協議。它允許用戶免費拿去商用、修改、甚至閉源賺錢。它唯一的請求只有一個:在專案裡,保留原作者的版權聲明和許可聲明。
而樂天不僅在模型發布中對DeepSeek絕口不提,更是直接在程式碼庫裡抹除了這份協議文件,還高調宣布自己採用的是Apache 2.0協議開源。雖然Apache 2.0同樣是對商業極度友善的開源協議,但它更正式,常被大廠用來建立自己的開源生態和專利護城河。
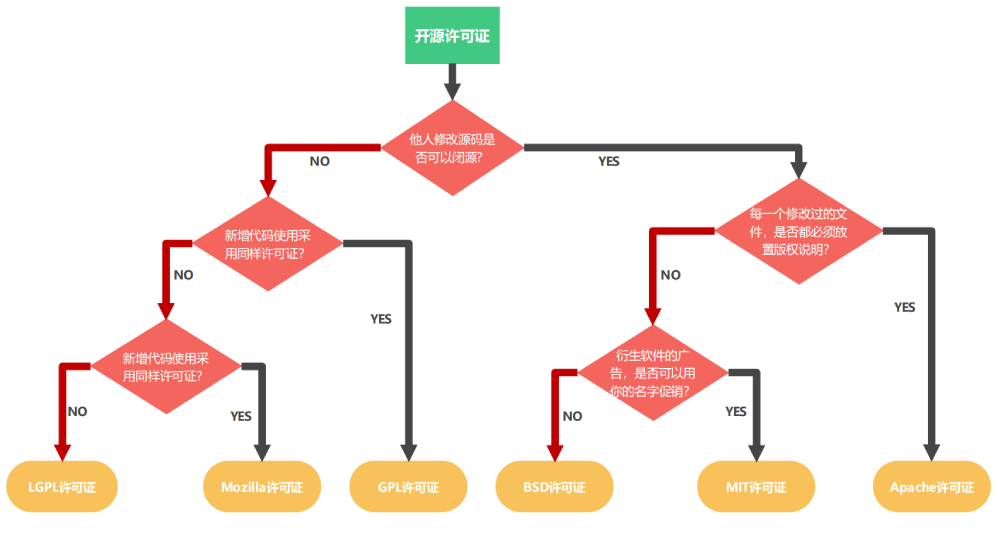
▲ 不同開源協議對比。MIT協議比Apache協議更寬鬆、更簡短,Apache 2.0在賦予自由的同時,明確包含了專利授權保護和更嚴謹的責任免除條款,適合更大型、法律風險規避更嚴格的商業計畫。(Source:Steven_shl)
樂天的算盤打得很精,抹掉DeepSeek的名字,套上自己的Apache 2.0協議,再把自己包裝成「慷慨開源7,000億參數大模型」的日本AI救世主。
喊了一年多的歐洲版DeepSeek、美國版DeepSeek,最後好像都沒做出來。
樂天也想做日本版DeepSeek,但在算力和訓練成本的壓力下,在當前全球大模型飛速發展的局面下,既想要中國技術的極致性價比,又放不下打造「本土巨頭」的身段,顯然是難上加難。
不如跟我們一起等等DeepSeek V4吧。





