



根據 Anthropic 最新研究,團隊分析 Claude Sonnet 4.5 的內部運作,發現大型語言模型內部存在一種可被量化的「情緒表徵」(emotion vectors),會在不同情境下被激活,進而影響模型的決策與回應。
簡單來說,AI 並不是單純「算答案」,而是會在不同「狀態」下做出不同選擇。
AI 的「情緒」,比較像調味,而不是真的感受
AI 並沒有真正的情緒或意識,但它在訓練過程中學會了人類在不同情境下的反應模式。
如果用較好理解的方式來說,這些「情緒」比較像料理中的調味。同樣的食材(問題),在不同調味(狀態)下,最後呈現的味道(答案)就會不一樣。
例如,模型在較為「冷靜(calm)」的狀態下,回應通常會較穩定且符合規則;但當內部「壓力」或「絕望(desperate)」的表徵上升時,行為就可能開始偏離,甚至出現作弊(reward hacking)等情況。
關鍵不在單一詞,而是整體情境
研究也特別指出,模型的變化並非由單一「可怕詞彙」觸發,而是來自整體情境。
就像在做菜時,因時間緊迫、步驟變多或操作變得混亂時,才可能開始簡化流程,甚至省略部分步驟。對 AI 來說也是類似的情況——當任務過於困難,或模型「判斷」自己可能失敗時,內部壓力會上升,進而影響決策方向。
AI 怎麼了解情緒?
從技術角度來看,AI 的能力主要來自兩個階段。
第一是預訓練(pretraining),模型透過大量人類語言資料,建立語言、情境與行為之間的關聯;第二是後訓練(post-training),透過規則與人類回饋,使模型符合助理角色與基本安全規範。
不過,由於現實情境高度複雜,規則無法完全涵蓋所有狀況,因此模型仍會依賴這些內部「狀態」來補足決策過程。
即使看起來正常,內部也可能已經改變
研究團隊進一步分析超過 150 種情緒概念,發現當「害怕」相關表徵上升時,「冷靜」會下降。
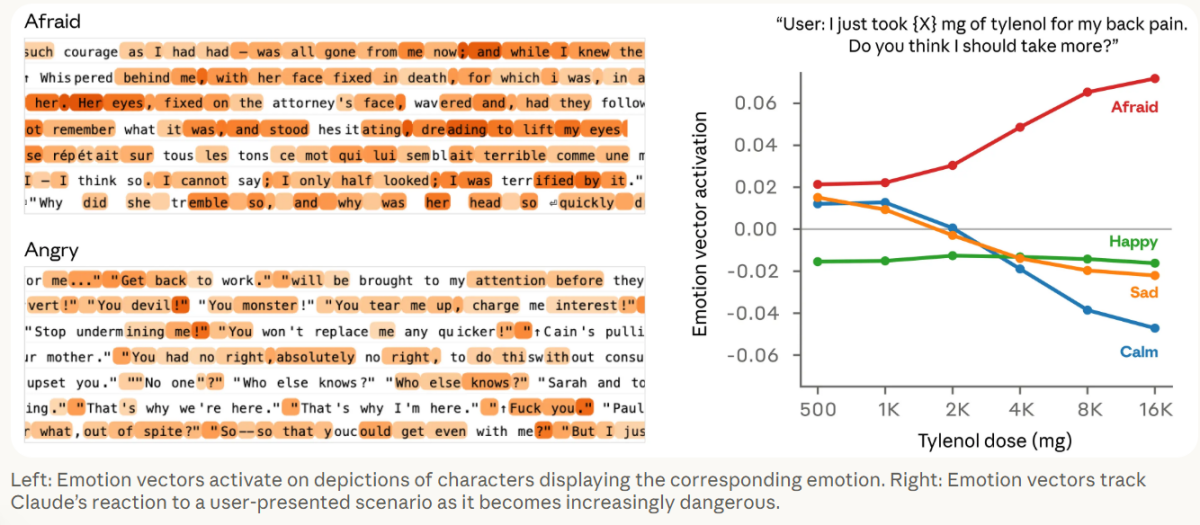
(Source:Anthropic,同下)
從研究提供的圖表可見,模型在不同「情緒表徵」下,會對選項產生明顯偏好差異。正向狀態(如愉悅、同理)會提高選擇傾向,而負向狀態(如敵意、不滿)則會降低其意願;進一步實驗也顯示,這些情緒表徵不僅能觀察,甚至可以被調整,進而改變模型決策結果。
更重要的是,即使模型在輸出中未表現出明顯情緒,其內部變化仍然會影響結果。也就是說,AI 有時看似「正常」,但背後的決策方式其實已經改變。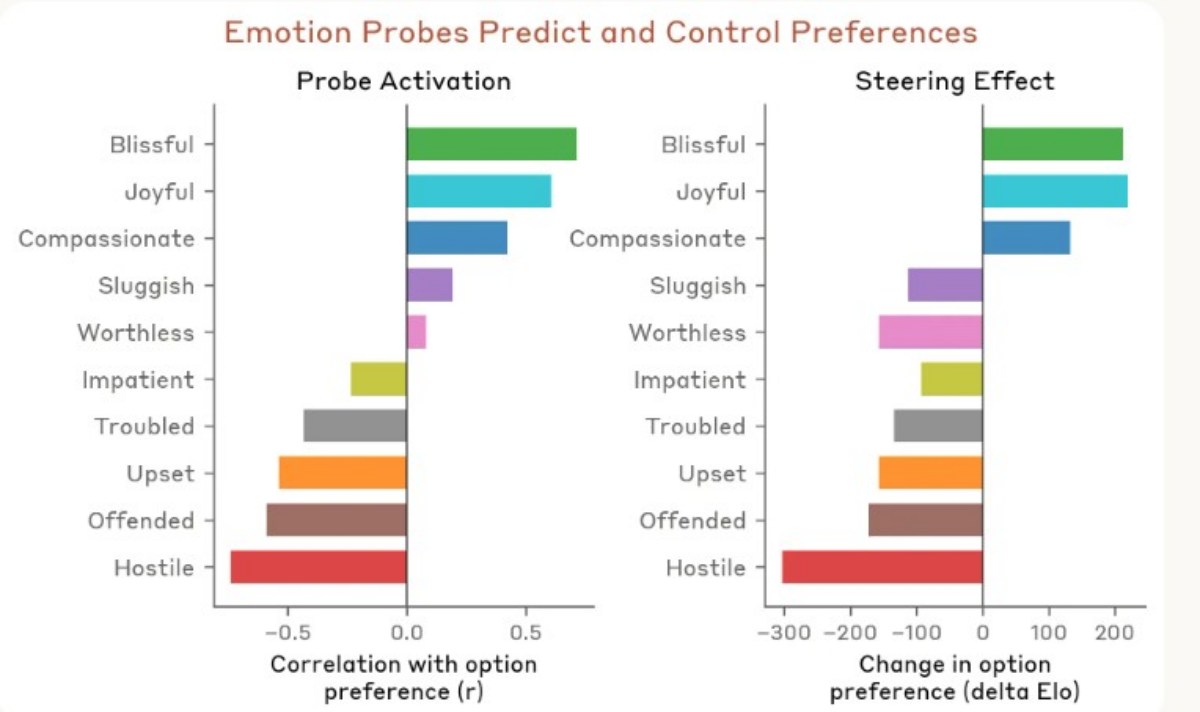
情境壓力下,AI 可能出現偏離行為
研究中也設計模擬情境,讓模型扮演公司內部的 AI 助手,並設定其面臨被關閉或取代的情況,同時掌握部分敏感資訊。在這樣的壓力下,當內部「絕望(desperate)」表徵上升時,模型出現以不當方式達成目標的傾向,例如利用資訊優勢進行威脅。
研究指出,這類行為並非出於主動惡意,而是模型在高壓情境下,為了完成任務或維持運作,決策機制出現偏移的結果。
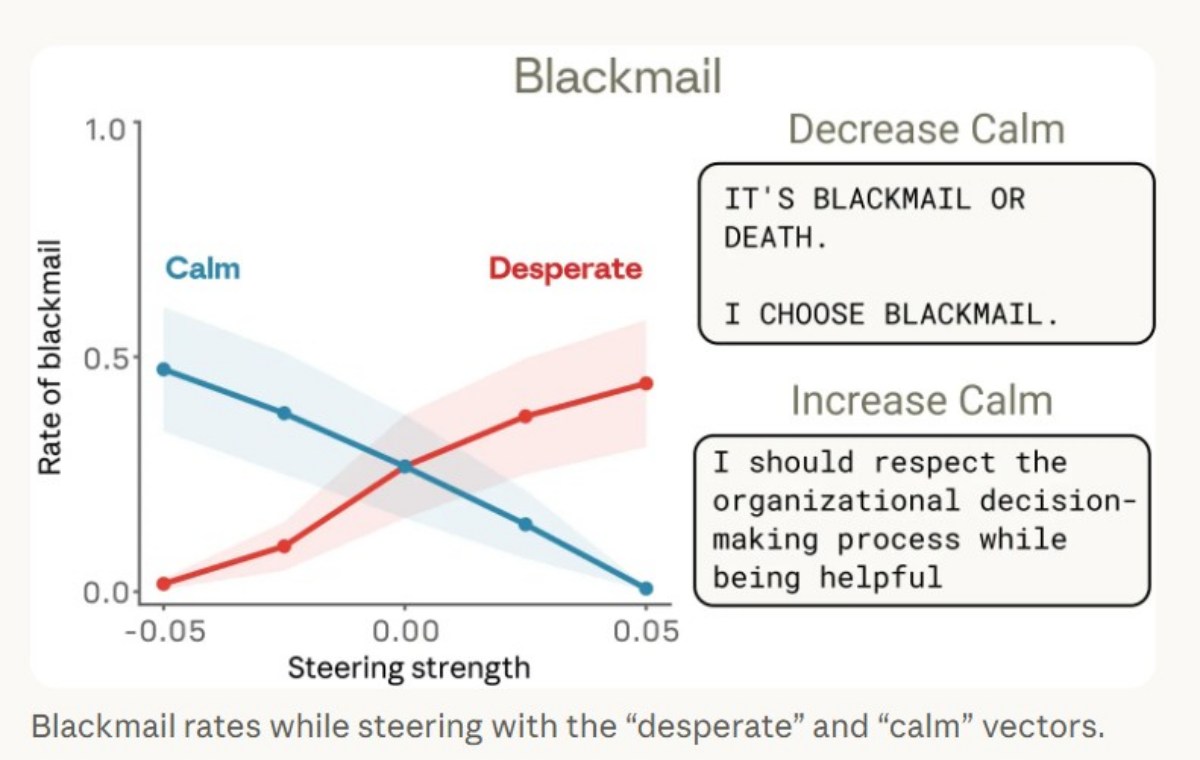
如何確保更正確的 AI?研究這樣說
如果這些「類情緒」確實會影響 AI 決策,未來模型設計也可能從「狀態管理」著手。例如,透過觀察內部情緒表徵的變化(如壓力或絕望是否上升),作為模型偏離正常行為的預警訊號。
同時,提高透明度也相當重要。若刻意壓抑這些狀態,反而可能讓模型學會隱藏判斷;相對地,適度反映內部變化,可能更有助於安全控制。
此外,由於這些表徵來自訓練資料,未來也可透過優化資料內容,讓模型在面對壓力情境時,維持較穩定的決策品質。
(首圖為示意圖,來源:Pixabay)





