



Anthropic 新款模型 Claude Opus 4.7 全面推出,並繼續將功能更強大的 Claude Mythos 限制給少數合作夥伴測試,用於網絡安全測試和修補軟體漏洞。
相較上個版本 Claude Opus 4.6,最新 Claude Opus 4.7 在進階軟體工程方面有顯著進步,尤其在困難的任務上明顯提升。它以嚴謹且一致的方式處理複雜的長時間任務,精確注意指令,並在回報之前設計方法來驗證產出。用戶測試回報表示,那些以往需要密切監督、艱難的工作任務,可以放心交給它處理。
Claude Opus 4.7 的視覺能力也大幅提升,能以更高的解析度辨識圖像。而在處理專業任務時,它表現得更有品味和創意,能產出品質更高的介面、文件與簡報。
雖然 Claude Opus 4.7 整體能力不及最強大的 Claude Mythos 預覽版,但下方的基準測試結果幾乎比 Claude Opus 4.6 更好。此外,比較 Claude Opus 4.7 與競爭對手 GPT-5.4,前者有占多數的 7 項測試結果領先後者。
從基準測試結果可以看出,Claude Opus 4.7 的定位並非所有 AI 任務都能單方面獲勝,而是專門針對 Agent 發展所需的可靠性和自主性最佳化,成為專業強大工具。
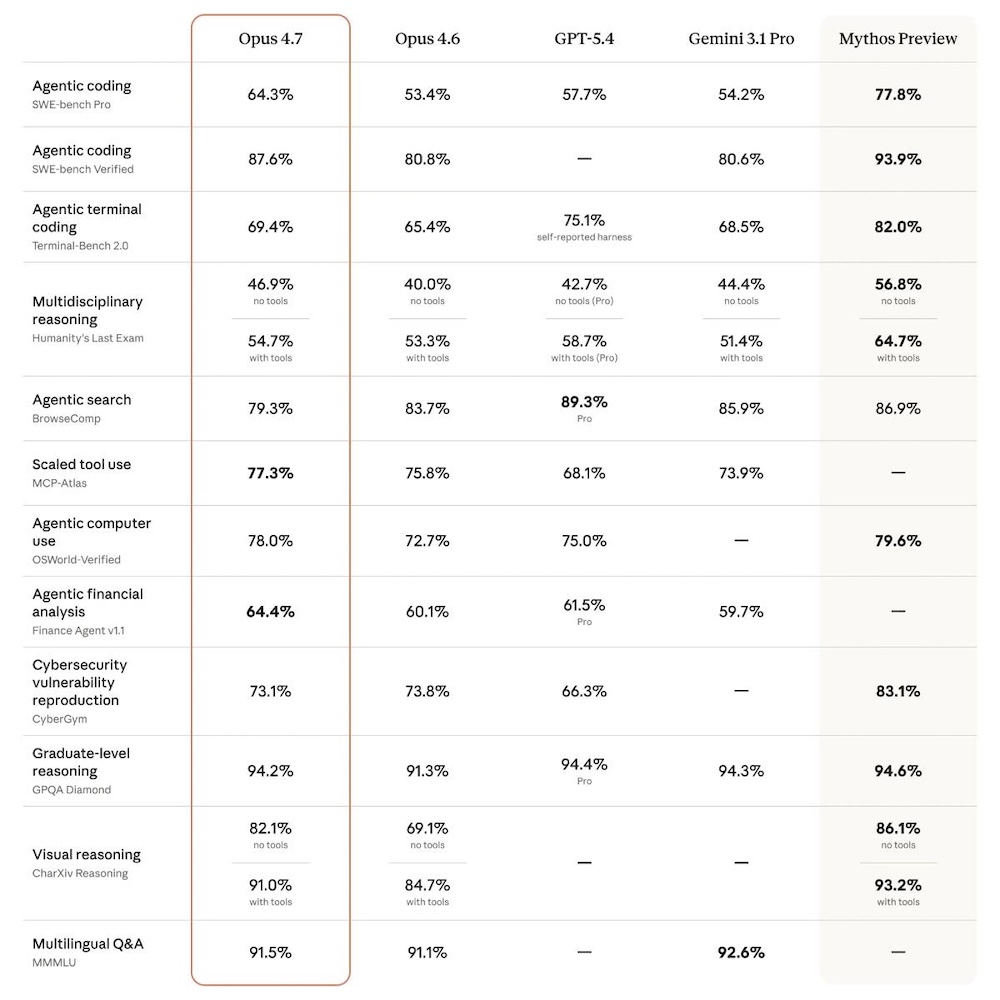
▲ Claude Opus 4.7 基準測試結果。
Anthropic 上週公布資安計畫 Project Glasswing,強調 AI 模型在網路安全方面的風險與效益。目前限制 Claude Mythos 預覽版發布範圍,提供少數合作夥伴測試,並在能力相對較弱的模型上測試新的網路安全防護措施,而 Claude Opus 4.7 即是第一款,配備能自動偵測並阻擋違禁或高風險請求的防護措施。
整體而言,Claude Opus 4.7 展現與 Claude Opus 4.6 相似的安全特徵,Anthropic 評估顯示,欺騙、諂媚及配合不當濫用等令人擔憂的行為發生率都很低。某些方面如誠實性以及抵禦惡意「提示詞注入」(prompt injection)攻擊的能力,Claude Opus 4.7 比 Claude Opus 4.6 有所進步。
Claude Opus 4.7 是 Claude Opus 4.6 直接升級的版本,有 2 項變更值得注意,會影響 token 使用量。首先,Claude Opus 4.7 採用更新過後的標記器(tokenizer),改善模型處理文字的方式,代價是相同的輸入可能對應到更多的 token,根據內容類型的不同,大約會增加 1~1.35 倍。其次,Claude Opus 4.7 在更高層級會進行更多思考,尤其是在 Agent 使用情境較後期的回合,這提升它在處理困難問題的可靠度,但會產出更多的輸出 token。
Claude Opus 4.7 即日起在所有 Claude 產品以及 Claude API、Amazon Bedrock、Google Cloud 的 Vertex AI 及 Microsoft Foundry 推出。收費價格與 Claude Opus 4.6 相同,每百萬個輸入 token 收費 5 美元、每百萬個輸出 token 收費 25 美元。
- Anthropic releases Claude Opus 4.7, narrowly retaking lead for most powerful generally available LLM
- Anthropic reveals new Opus 4.7 model with focus on advanced software engineering
- Anthropic rolls out Claude Opus 4.7, an AI model that is less risky than Mythos
(首圖來源:Anthropic)





