




近兩年,模型能力快速成熟,焦點從「能不能訓練出更強的模型」,轉向「能不能把能力即時、穩定地送到每個使用者手上」。推論因此成了下一個關鍵:它不只是算出答案,更關乎反應速度、體驗品質與能源效率。
訓練與推論差在哪裡?
訓練可以想成模型的「學徒期」。我們會先準備好乾淨的資料,把它餵進模型裡。模型在一開始只是亂猜,預測結果常常不對,這時就需要用「誤差」來告訴它哪裡出錯,再讓模型一點一滴修正裡面的參數。這樣的循環重複無數次,模型就會逐漸學會如何抓住資料裡的規則,提升自己的判斷力。
在這個過程中,科學家會設計驗證機制,檢查模型不只是在舊資料上表現良好,而是能在新資料上也有正確反應。這一步叫做「驗證」,重點就是看模型能不能真的應付真實世界,而不是只會「死背」。
而推論就是學成後的「正式上場」。以語言模型為例,當你丟一段問題給它,模型會先快速消化整段輸入,建立一個上下文,然後再逐字生成答案。這時候影響體驗的,並不是模型會不會做題,而是它能不能在合理的時間內給你答案、反應順不順暢。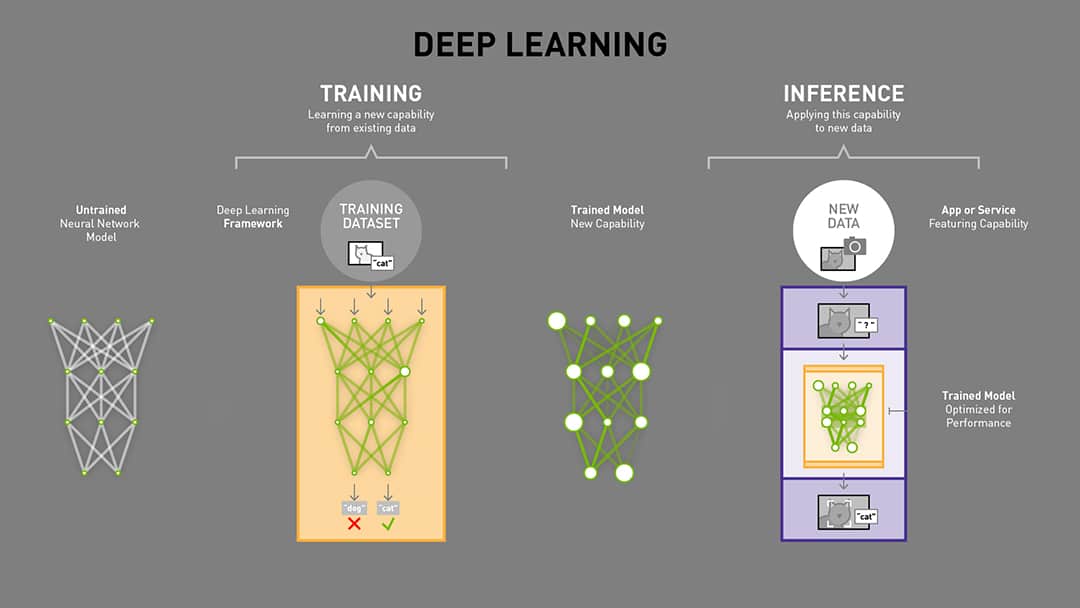
(Source:輝達)
如果還是覺得抽象,可以想想《中華一番》裡的小當家。訓練就像他在廚房裡日復一日磨刀練火候,把功夫練到骨子裡。推論則是比賽現場,他必須在有限的時間和食材下,快速上桌一道驚豔的料理。訓練決定功力上限,推論決定能否即時交付成果。
GPU 慢慢重心往 ASIC 走?
訓練主要依賴 GPU。因為訓練過程需要不斷進行前向傳遞與反向傳播,計算量龐大,且必須在數百甚至上千顆加速器之間保持高速同步。因此,GPU 的高度平行運算能力與靈活度,使它們成為訓練過程中不可或缺的核心硬體。在這個階段,重點是整體吞吐量(throughput),也就是單位時間內能處理多少資料,而延遲並不是首要考量。
相較之下,推論則面臨完全不同的挑戰。除了算力,推論還要同時處理記憶體頻寬、延遲控制,以及大規模併發需求。特別是延遲問題至關重要:
- TTFT(Time To First Token):第一個字出現所需時間
- TBOT(Time Between Output Tokens):字與字之間的間隔
- E2E Latency(End-to-End Latency):整段答案完成所需時間
這些通常以秒為單位衡量,任何延遲都會直接影響使用者體驗。與訓練不同,推論端面對的是即時互動,成千上萬的用戶同時丟出請求,每個人都期待快速回應。此外,推論還必須兼顧功耗與成本,因此會大量使用量化(FP8/INT8/INT4)、模型蒸餾、剪枝,甚至針對 KV Cache (短期記憶)進行優化,以確保推論既快又省電。
這也是為什麼越來越多企業選擇導入 推論專用 ASIC。這些晶片將固定的推論流程直接「硬體化」,在能效與成本上都優於通用 GPU,能帶來更高的 perf/W(每瓦效能) 與 perf/$(每美元效能)。換句話說,雖然 ASIC 不如 GPU 靈活,但在大規模、重複性的推論場景中,卻能以更低能耗、更低成本,承載龐大的使用者流量。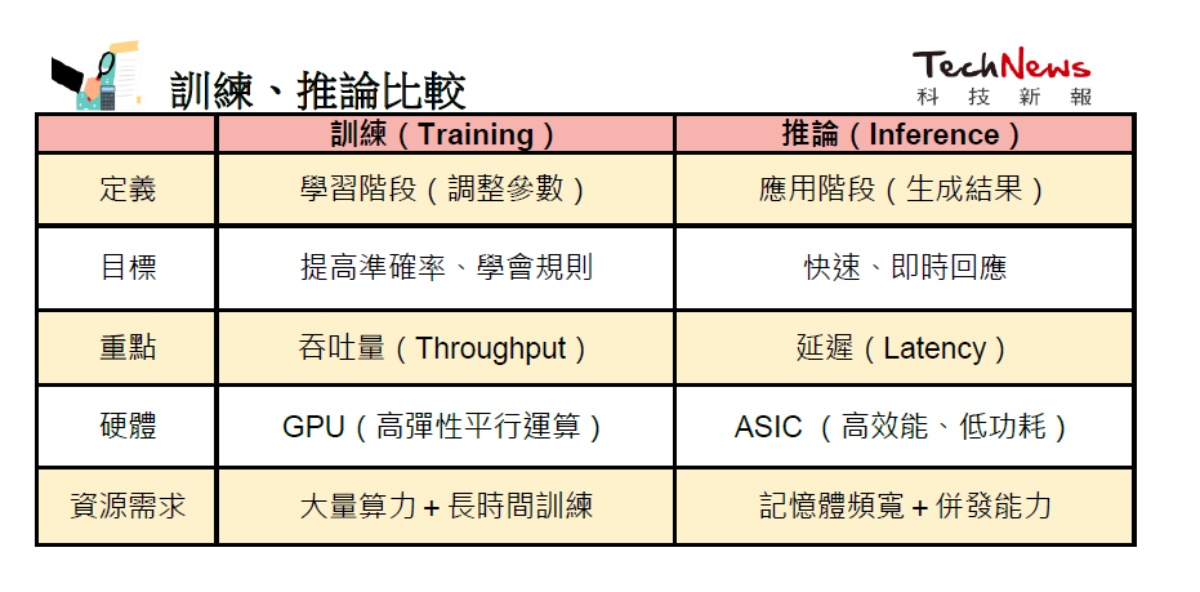
推論與 ASIC 的未來
未來 AI 產業趨勢會更集中在「讓推論跑得更快、更省、更普及」:更有效率的 KV Cache 管理、更進一步的量化與混合精度、更成熟的 prefill/decode 分離架構,以及「雲+端」的協同運作。
對晶片產業而言,這代表推論專用 ASIC/NPU 的角色將愈來愈吃重;對服務業者而言,誰能同時把延遲、能耗、成本壓到健康水位,誰就能把 AI 價值帶進更廣的日常場景。訓練決定能力上限,但真正決定普及速度與商業價值的,是推論這條「最後一哩路」。
(首圖來源:AI 生成)





