



中國 DeepSeek(深度求索)釋出「DeepSeek-OCR」,這是一款以大型語言模型為中心的角度研究視覺編碼器作用的模型,目的在於以語言模型壓縮基於圖像的文字文件,讓 AI 處理更長的上下文脈絡不會受到記憶體限制。
DeepSeek 介紹最新 DeepSeek-OCR,主要概念是把文字當成圖像來處理,所需的運算量可比直接處理文字更少。根據 DeepSeek 論文所述,DeepSeek-OCR 可將原始文字內容壓縮 10 倍,同時保留 97% 準確率。
OCR(Optical Character Recognition,光學字元辨識)是將印刷文字、手寫等圖像轉換成機器可讀文字的程序。而 DeepSeek-OCR 的深度解析模式可把財務圖表轉換成結構化資料,生成 Markdown 表格與圖表。DeepSeek-OCR 有 2 個核心部分:負責圖像處理的 DeepEncoder,以及 DeepSeek3B-MoE 為基礎、擁有 5.7 億活躍參數的文字生成器,負責把壓縮後的內容解讀成文字。
DeepEncoder 結合 Meta 的 8,000 萬參數模型 SAM(Segment Anything Model)進行影像分割,與 OpenAI 的 3 億參數模型 CLIP(連結文字與圖像)。兩者之間有一個 16 倍壓縮器,大幅減少圖像詞元(token)數量。以 1024×1024 像素的圖像為例,起初為 4,096 個詞元,經 SAM 處理後,壓縮器會把它降至 256 個詞元,然後傳遞給運算密集的 CLIP。
DeepSeek-OCR 支援不同解析度的圖像,在較低解析度時,每張圖像只需要約 64 個視覺詞元,而在較高解析度可達 400 個詞元。相較之下,傳統 OCR 系統完成同樣任務常常需要數千個詞元。
在 OmniDocBench 測試中,DeepSeek-OCR 僅用 100 個視覺詞元就擊敗 GOT-OCR-2.0,後者使用 256 個詞元,DeepSeek-OCR 也少於 800 個詞元,勝過每頁需要超過 6,000 個詞元的 MinerU 2.0。
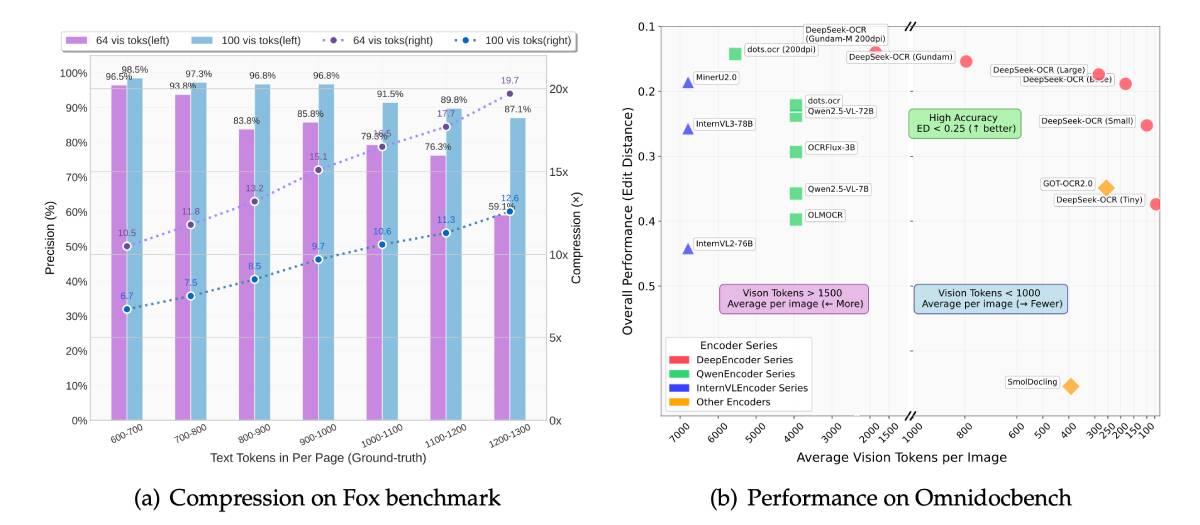
實際上所需詞元數量依文件而異,簡單的簡報約要 64 個詞元,書籍與報告約要 100 個,複雜的報紙則需使用 DeepSeek 的 Gundam 模式,最多需要 800 個。
DeepSeek-OCR 支援各種文件類型,從純文字到圖表、化學式及幾何圖形都能處理,支援約 100 種語言,可以保留原始格式,輸出純文字,並提供通用的圖像描述。背後由 DeepSeek 團隊使用約 3,000 萬頁 PDF(涵蓋約 100 種語言,其中約 2,500 萬頁為中文與英文),以及 1,000 萬張合成圖表、500 萬個化學式及 100 萬個幾何圖形,訓練出 DeepSeek-OCR。
I quite like the new DeepSeek-OCR paper. It’s a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn’t matter.
The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language… https://t.co/AxRXBdoO0F
— Andrej Karpathy (@karpathy) October 20, 2025
▲ OpenAI 共同創辦人卡帕斯(Andrej Karpathy)對 DeepSeek-OCR 提出看法。
(圖片來源:GitHub)





