



OpenAI 表示,GPT-5.2 的訓練採用輝達 Blackwell GPU(GB200-NVL72),並與 Azure 大規模部署的 H100、H200 搭配運行,強化模型在推理與專業任務上的整體效能。
根據輝達在 8 月的 Facebook 發文,GPT-5 雖同樣使用 Hopper 架構(H100/H200)進行訓練,但並未採用 GB200-NVL72 叢集,而是僅於部署端使用相關系統。相較之下,GPT-5.2 將 Blackwell 納入訓練流程,被外界視為 OpenAI 針對近期 Google Gemini 3.0 推出後,加速模型更新的重要調整。
NVIDIA 官方數據顯示,GB200 NVL72 在 512 GPU 規模下,可提供較 H100 高達 3.2 倍的訓練效能,並帶來 1.9 倍的訓練成本效益(performance per dollar);若以 Blackwell Ultra(GB300)作為平台上限,其訓練速度較 Hopper 可達 4.2 倍。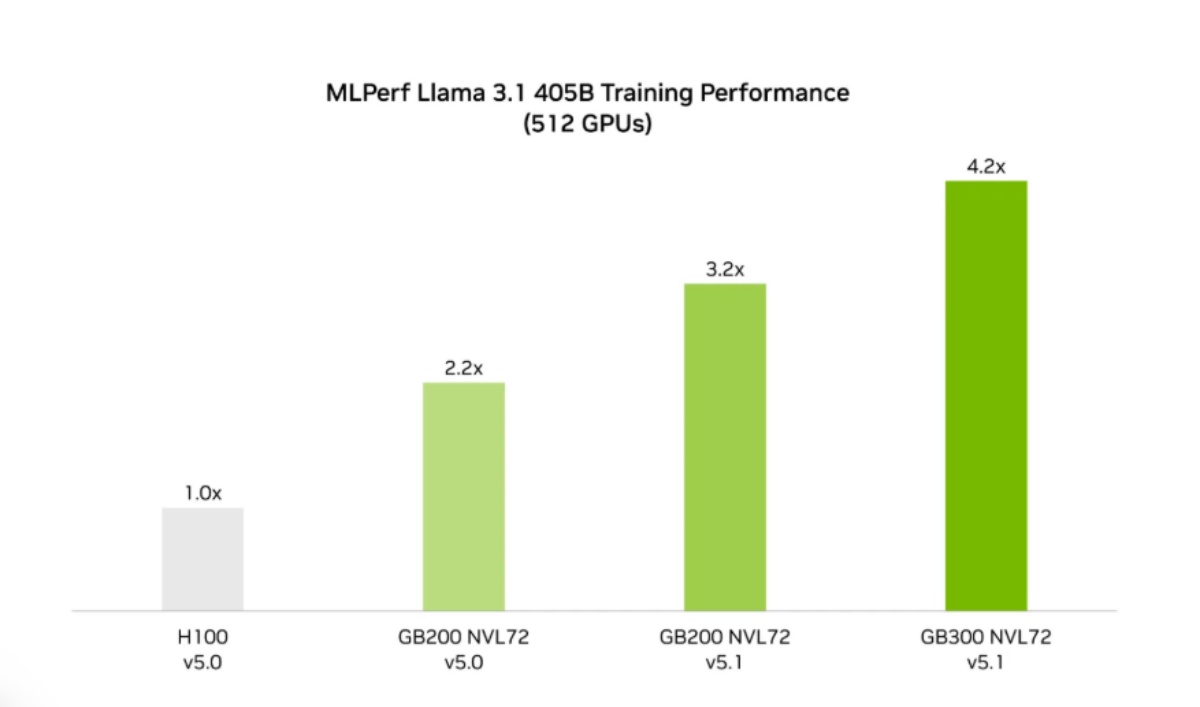
(Source:輝達)
透過 NVFP4 精度模式與第五代 NVLink/NVSwitch 設計,Blackwell 能在單一系統中以高頻寬連結 72 顆 GPU,使其在超大型模型運算中具備更高的效率密度,適合應對近年快速擴張的 LLM 訓練需求。
GPT-5.2 將陸續向用戶開放,實際體驗與模型效果仍有賴市場後續觀察。另外,隨著 Blackwell Ultra(GB300)開始出貨並由主要雲端服務商部署,市場普遍預期未來 GPT 系列模型將逐步導入更高階的 Ultra 平台,以縮短訓練週期並提升能源效率。
- GPT-5.2, Blackwell & Blackwell Ultra Continue To Blaze Ahead With Better Performance & Value
- As AI Grows More Complex, Model Builders Rely on NVIDIA
- OpenAI
(首圖來源:Unsplash)





