



日益加速的計算領域,量子運算的發展一直被網路和控制的複雜性所阻礙。然輝達 (Nvidia) 在華盛頓 GTC 揭示 NVQLink 架構,開啟「量子與 GPU 運算的時代」。
輝達 NVQLink 被譽為全球首創的系統,能將量子系統與傳統的中央處理器 (CPU) 和圖形處理器(GPU)系統互連,不僅克服量子發展的主要障礙,更奠定未來混合加速計算的基礎。
NVQLink 必要性展現量子與傳統計算的共生關係
輝達工程、半導體和量子業務部門總經理 Tim Costa 闡述量子電腦與傳統電腦之間存在的「共生關係」。一方面,量子處理器具有潛力解鎖那些傳統系統無法獨自解決的問題。但另一方面,要讓量子電腦成為有用的工具,必須解決極為龐大的計算問題,特別是在錯誤校正、校準和最佳控制方面。
量子處理器的規模持續成長,以上的問題需要以低延遲和高頻寬來提供大量的AI運算能力。輝達堅信,若沒有大規模 AI 超級電腦的應用來處理量子設備的模擬、校準和整體控制等關鍵問題,實用的量子計算機將無法存在。因此,將 AI 應用於量子設備的傳統 GPU 電腦上,被視為邁向有用量子運算的絕對必要里程碑。
目前,錯誤校正仍處於萌芽階段,校準通常是由物理學家手動調整。Costa 指出,這種方式根本無法擴展到解決具有重要意義的實際問題所需系統的規模。這正是輝達推出 NVQLink 的核心動機。
達成極低延遲互連來克服網路瓶頸
長期以來,量子發展的主要障礙之一在於網路組件,也就是讓量子系統能夠與另一種運算系統進行通訊。由於量子訊號本身的複雜性,將量子系統與傳統電腦這兩種截然不同的系統互連,一直是一個障礙。雖然,過去曾有過彌合差距的嘗試,例如不列顛哥倫比亞大學(University of British Columbia)的「量子通用翻譯器」,但在有效率的橋接這兩個世界,其進展仍然有限。
NVQLink 架構的誕生,目的在達成量子處理器(QPU)與傳統 GPU 之間的緊密整合。這種整合形成了輝達互惠願景的基礎,該願景包括混合、加速的量子-GPU系統以及加速的量子超級計算機。
技術實現方面,NVQLink 展現了令人矚目的性能突破:
- 極低延遲通訊:互連使得工程師和科學家能夠直接從量子處理器呼叫 GPU 運算,延遲低至四微秒。
- 可擴展的傳統資源:為了進一步強化系統,連接的 GPU 系統可以透過乙太網路連接,在需要時擴展到任意大量的計算資源。
- 廣泛的模態支援:NVQLink 的互連方案支援所有主要的 QPU 模態,涵蓋從超導系統和陷阱離子,到光子和中性原子等技術。
Costa 強調,NVQLink 代表了迄今為止與量子處理器連接的最強大的傳統經典資源,以最低延遲實現互連,並已展示了完整且可擴展的量子錯誤校正能力。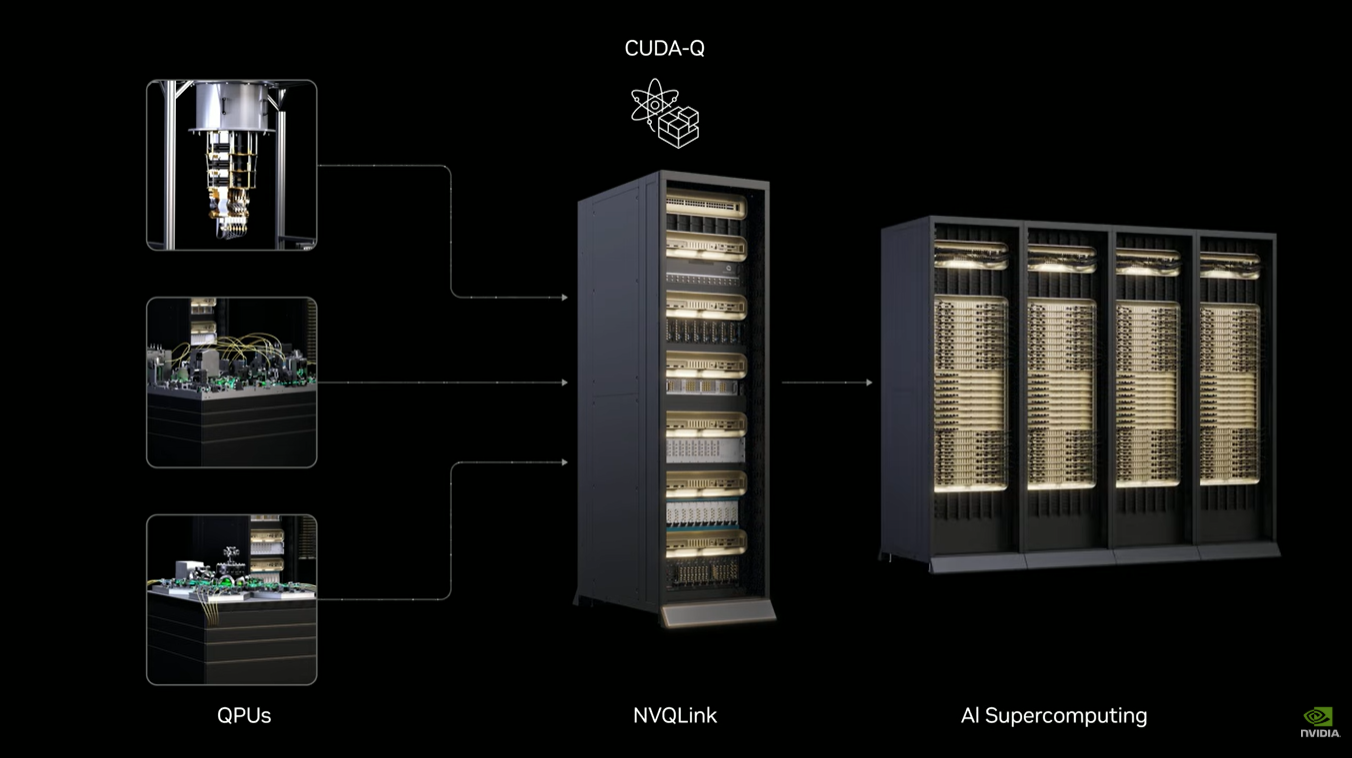
軟體整合與開放架構的生態系統策略
除了硬體互連的突破,NVQLink 的成功也建立在輝達的軟體生態系統之上。該架構提供了對輝達 CUDA-Q 軟體庫應用程式介面(API)的即時存取,以支援跨 GPU、CPU 和 QPU 的運算。
CUDA-Q 允許領域科學家將加速計算的所有最佳技術,以及他們目前使用的基礎設施,與量子處理器的能力結合在一起。輝達的目標是為那些正在構建量子技術的人們提供一個基礎的科學和工程工具,並與所有量子軟硬體開發者合作,將其整合到將成為未來運算的系統中,包括量子加速。這也為執行錯誤校正、校準和控制等重要工作執行提供了強大的運算能力。
輝達將 NVQLink 定位為一個開放式架構系統。在開發過程中,輝達與約 17 個致力於量子處理器技術的組織進行了協作。在 GTC 大會上,被列為合作夥伴的機構包括 IonQ、Quantunuum 和 QuEra 等企業,以及費米實驗室(Fermilab)、洛斯阿拉莫斯國家實驗室(Los Alamos National Laboratories)和橡樹嶺國家實驗室(Oak Ridge National Laboratories)等頂級實驗室。Costa 明確指出,該架構的定義、該架構的採用,都是與生態系統公開合作完成的。
解決未解之題的戰略布局
輝達推出 NVQLink 的戰略使命非常清晰,那就是打造最佳的經典計算技術來整合量子處理器,從而使世界能夠解決僅憑經典系統無法解決的問題。
透過提供一個高效、低延遲、高頻寬的傳統運算橋樑,並結合其強大的 AI/GPU 運算能力與開放的 CUDA-Q 軟體平台,NVQLink 不僅打破了量子與傳統運算之間的物理和網路障礙,更將AI的超大規模運算能力導入了量子控制的關鍵環節。這一步棋,有效地將量子運算從一個孤立的學術挑戰,轉變為一個可擴展、實用且與現有超級計算機基礎設施緊密結合的混合加速計算解決方案,真正為實現有用量子計算開闢了道路。
(首圖來源:視訊截圖)





