



蘋果研究團隊近日發表一項新研究,指出大型語言模型(LLM)不僅能理解文字,當其接收由音訊與動作模型產生的文字描述後,也能有效推斷使用者正在進行的日常活動。這項研究揭示了蘋果在多模態 AI 感知上的布局方向,也為未來的活動追蹤、健康偵測與智慧情境推論帶來更大的想像空間。
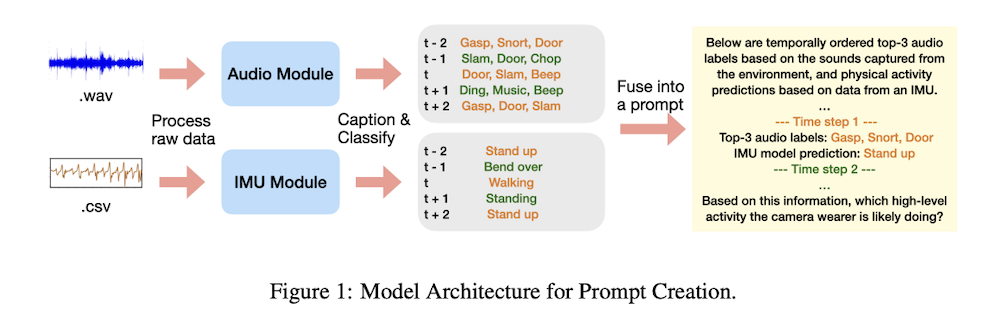
這篇名為《Using LLMs for Late Multimodal Sensor Fusion for Activity Recognition》的論文指出,LLM 可用於「後期多模態融合」(late fusion),將來自音訊模型與 IMU 動作模型(加速度計與陀螺儀)的輸出進行整合與分析。研究人員表示,這種結合方式能在感測資料不足、無法直接提供完整情境時,協助系統更精準地理解使用者的行為。
 (Source:arxiv)
(Source:arxiv)
研究團隊強調,LLM 在此過程中並沒有直接接觸音訊檔案,也沒有讀取原始感測資料,而是接收由模型自動生成的文字摘要與動作預測結果,透過語言模型的推論能力進行最終判斷。這意味著系統能利用更「抽象」的描述進行辨識,不必依賴大量專門訓練或高成本資料。
 (Source:arxiv)
(Source:arxiv)
研究引用了大規模第一人稱視角資料集 Ego4D,並從中挑選十二種常見活動,包括吸塵、烹飪、洗衣、吃東西、打籃球、踢足球、與寵物玩、閱讀、使用電腦、洗碗、看電視與健身/舉重等。研究團隊整理出 20 秒長度的活動片段,再將音訊與動作訊號輸入不同模型,生成文字敘述與活動類別預測,最終再交由 LLM 進行判斷。
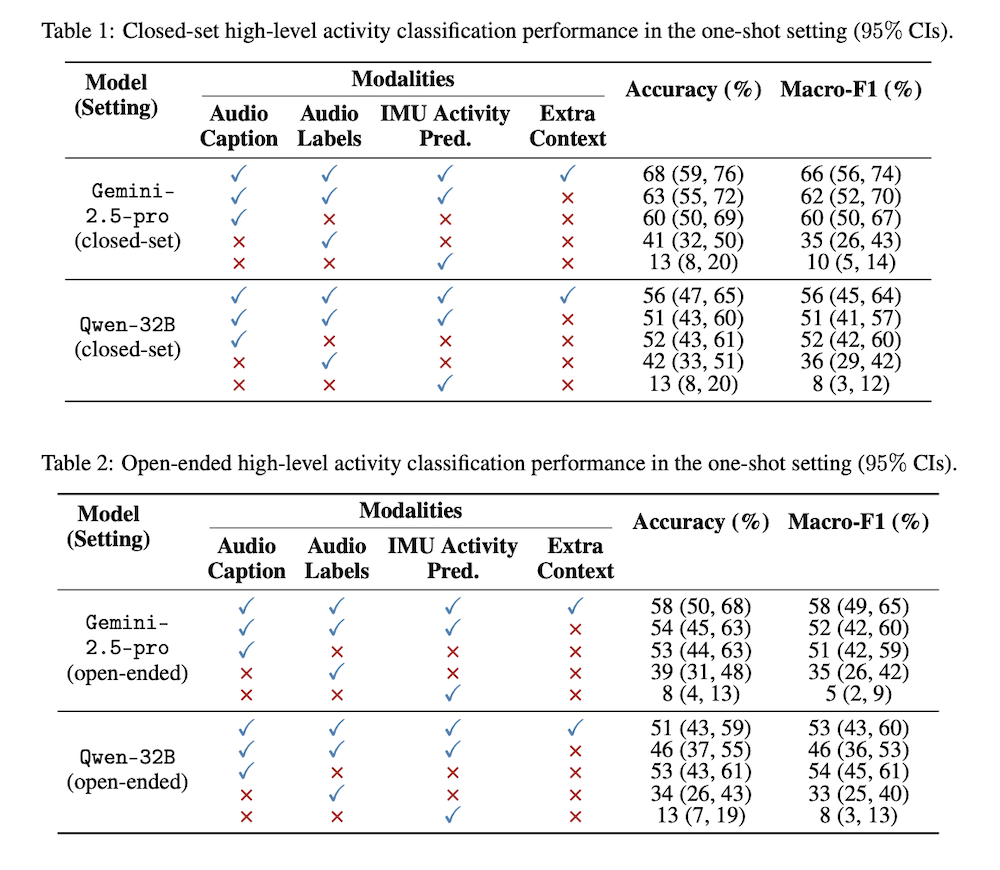
實驗採兩種設定,一種提供特定的 12 種活動選項(封閉式),另一種不提供任何選項(開放式)。研究結果顯示,無論在零樣本(zero-shot)或單樣本(one-shot)情境下,LLM 均能有效識別活動,F1 分數顯著優於隨機推測。研究人員指出,只要給模型一個示例,其準確度可進一步提升,展現 LLM 在跨模態推論上的高度潛力。
值得注意的是,這項研究展現一種可能的方向,那就是 LLM 不必直接看到影音內容,也能藉由其他模型生成的文字敘述理解行為,這也可能是蘋果未來在隱私與裝置端運算間取得平衡的方式。像是在 Apple Watch、iPhone 或 Vision Pro 等裝置上,系統可在不處理原始音訊或大量個資的前提下,仍具備更高階的情境理解能力。
研究中也特別提到,透過 LLM 進行後期融合,可避免為多模態任務額外建立大型專屬模型,降低記憶體負擔並提升部署效率。同時,研究結果也有助於推動活動識別、健康監測、智慧健身與行為分析等領域的應用,尤其適用於感測資料有限或模型無法進行長期訓練的情境。
為推動研究再現性,蘋果此次也公開了補充資料,包括 Ego4D 片段編號、時間戳記、提示詞以及單樣本示例,提供同領域研究者參考。
這項研究雖未明確說明是否會影響蘋果的產品規劃,但從其多模態融合框架、隱私導向的資料處理方式,以及與健康、情境理解相關的技術方向來看,外界推測此研究結果可能成為未來 Apple Intelligence、健康功能或穿戴裝置新世代感知能力的重要基礎。
(首圖來源:蘋果)





