



工程師兼 YouTuber 傑夫·蓋林(Jeff Geerling)利用蘋果(Apple)提供的四部 M3 Ultra Mac Studio,透過 macOS 26.2 新功能 RDMA over Thunderbolt 5 打造 AI 叢集。AI 叢集統記憶體總量達 1.5TB,成本約 40,000 美元(約台幣 126 萬元),Jeff 證實只要透過低延遲方式連接多部 Apple 電腦,即可大幅提升大型 AI 模型效能。
硬體配置同實機部署
Jeff 這次從 Apple 借來兩部 Mac Studio 配備 32 核心 CPU、512GB 統一記憶體與 8TB 儲存空間,另兩部則用 256GB 統一記憶體與 4TB 儲存空間。每部內建電源供應,方便機架佈線管理。Jeff Geerling 用 DeskPi TL1 迷你機架容納四機,機架側面開放設計讓背面電源開關易於操作。

效能基準測試
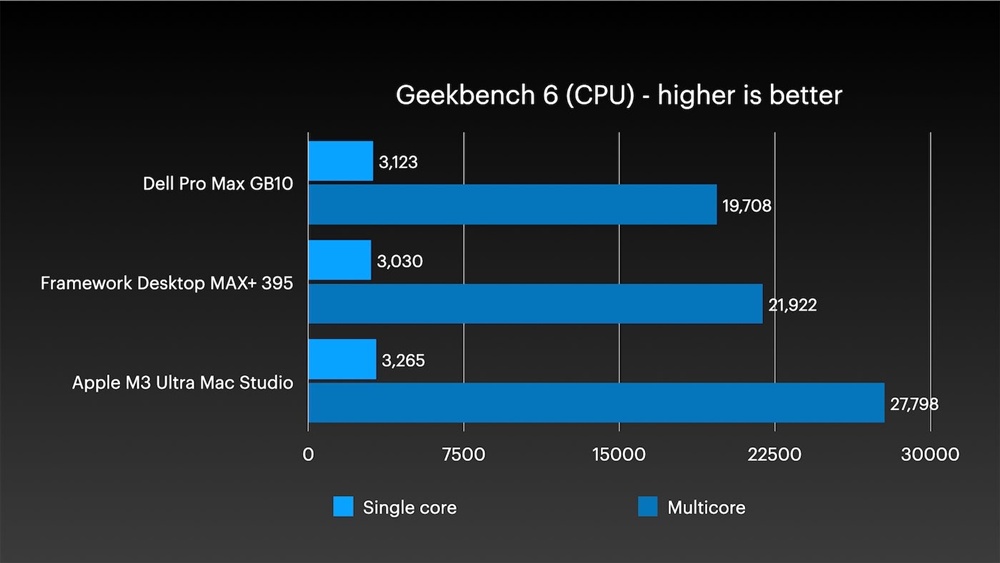
M3 Ultra Mac Studio 在 Geekbench 6 多核測試中勝過 Dell Pro Max with GB10 與 Framework Desktop,雙精度浮點數更達 1TFLOPS 以上,閒置功耗低於 10W。
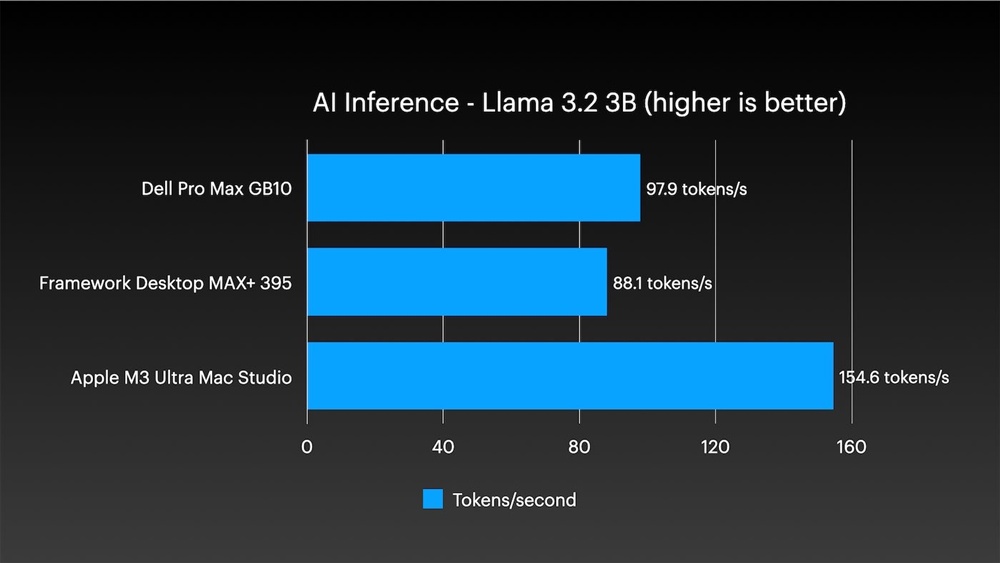
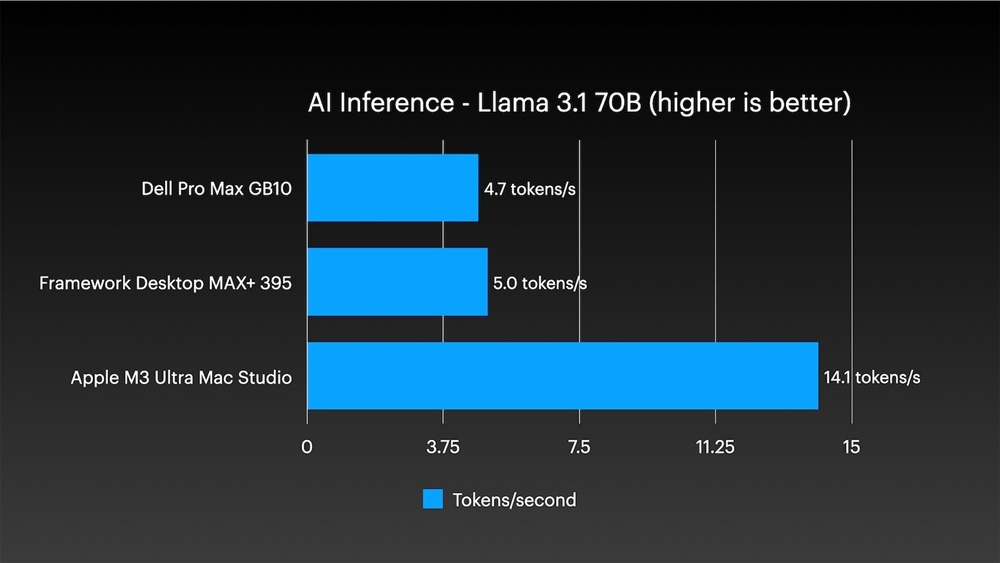
AI 推論方面,單機跑 Llama 3.2 3B 達每秒 154.6 個 token,大型 Llama 3.1 70B 維持每秒 14.1 個 token,兩個測試性能都遠超對手。
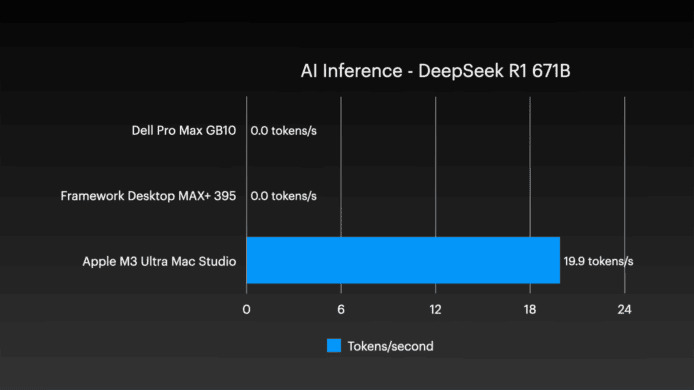
在嘗試運行 DeepSeek R1 671B 超巨大模型時,其他兩個系統都未能正常運行,而 Mac Studio 叢集由於搭載 1.5TB 統一記憶體,所以能輕鬆應付。
RDMA over Thunderbolt 優勢
RDMA over Thunderbolt 架構在這個 AI 叢集中取得明顯優勢。在啟用 RDMA 後,記憶體存取延遲由 TCP 的 300 微秒降至 50 微秒以下,利用 Thunderbolt 連接,四機叢集有如單一巨型記憶體。使用 exo 系統測試 Qwen3 235B,四機達每秒 31.9 個 token,比 llama.cpp TCP 快逾倍;DeepSeek V3.1 更達每秒 32.5 個 token。
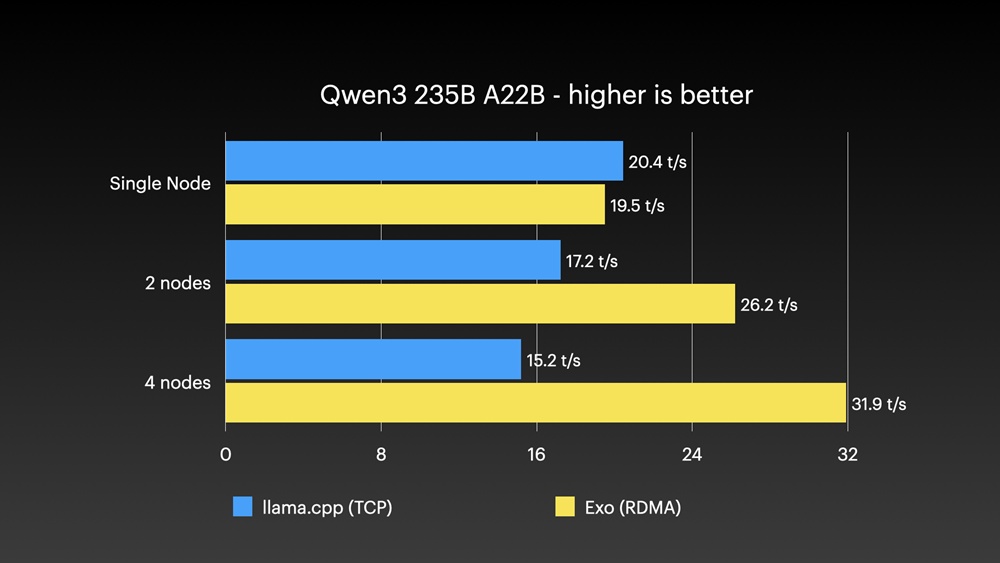
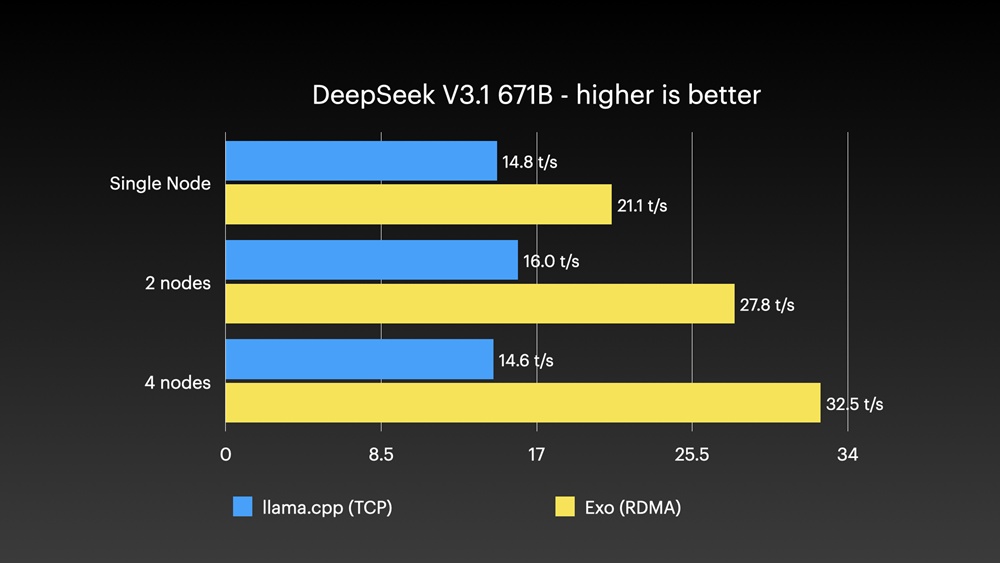
雖然 RDMA 表現出色,但在高負荷時偶現系統崩潰,Jeff Geerling 用 Ansible 工具快速重啟叢集。現時這項技術仍處發展階段,期待日後 Apple 可進一步強化 Thunderbolt 5 支援。
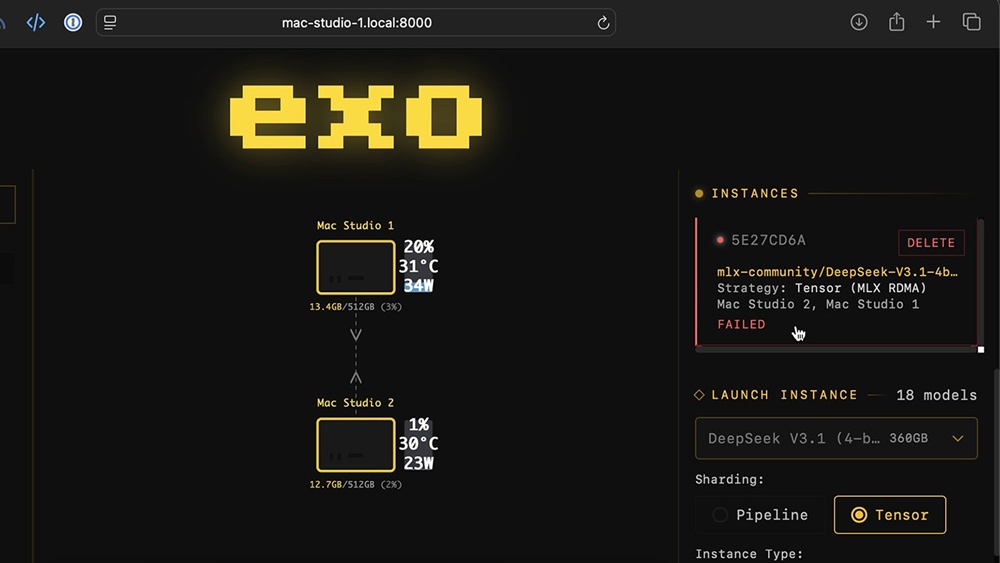
▲ 系統穩定性仍然是 exo 系統面對的問題。
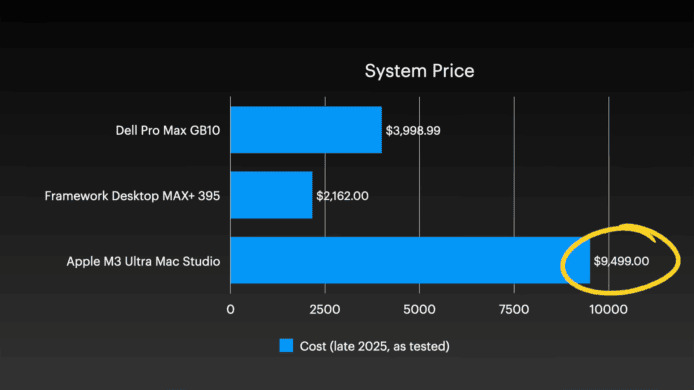
而且比對三個平台的價格,這次由 Mac Studio 組成的 AI 運算叢集平均每部需要 9,499 美元(約台幣 30 萬元),相比起其他兩個平台價錢高一截,也是值得留意的地方。
(本文由 Unwire HK 授權轉載;圖片來源:Jeff Geerling Blog)





