



在熱鬧開幕的 CES 2026 上,GPU 大廠輝達 (NVIDIA) 正式透過執行長黃仁勳的演講,揭露了其新一代 AI 超級運算平台「Rubin」的面紗。根據市場人士的分析,這款平台被視為推動大型語言模型 (LLM) 走向大眾市場的關鍵轉折點,其核心目標在於顯著降低構建與部署先進 AI 系統的門檻與成本,預計將能改變當前 AI 市場的生態。
根據 ZDnet 的報導,過去幾年隨著生成式 AI 的爆發式成長,市場對運算硬體的需求達到了前所未有的高度。因此,輝達在此次發表會中強調,Rubin 平台可視為先前 Blackwell 架構的性能擴展版。
報導指出,根據輝達提供的數據,Rubin 平台展現了驚人的成本效益與運算實力。首先,騎推論成本降幅達 10 倍,這使得在處理大型模型推論時,Rubin 能夠將每個 Token 的成本只有原來的十分之一。其次,GPU 需求減少四倍。尤其,在訓練當前主流的混合專家模型(Mixture-of-Experts,MoE)時,Rubin 所需的顯示卡數量僅為 Blackwell 平台的四分之一,極大地優化了硬體資源的配置。最後,輝達在開發 Rubin 平台時採用了所謂的「極致協同設計」(Extreme codesign)方法,將六種高度整合的晶片,整合進單一超級運算架構中,以打造高效能的 AI 工廠。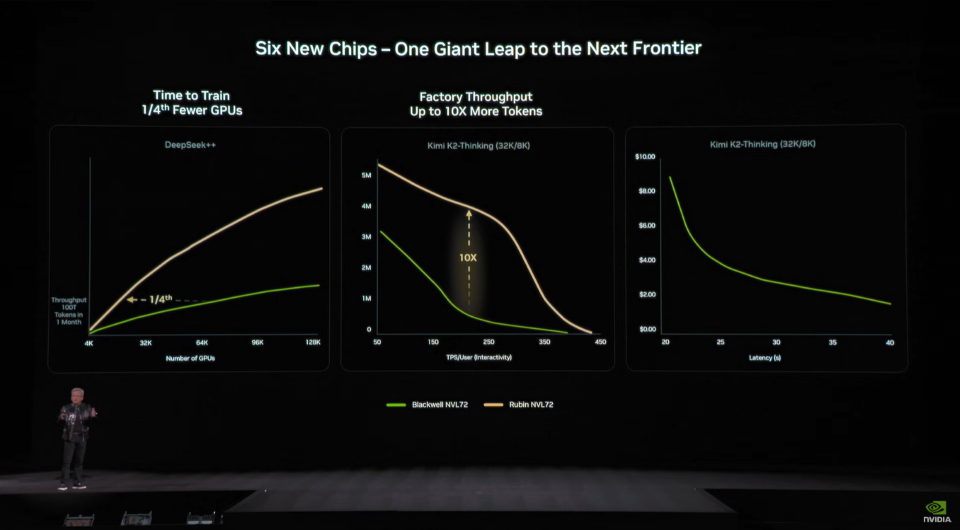
另外,針對 Rubin 平台其核心零組件的效益,其分析也指出,在 Nvidia Vera CPU 方面,是專為大規模 AI 應用設計的高能效處理器,配備 88 個自訂 Olympus 核心,並完全相容 Armv9.2 指令集,透過 NVLink-C2C 提供極速連接。而在 Nvidia Rubin GPU上,搭載第三代變壓器引擎(Transform Engine),能提供高達 50 petaflops 的 NVFP4 運算效能。
另外,透過 Nvidia NVLink 6 Switch來 GPU 之間超高速通訊的關鍵樞紐。而且有Nvidia ConnectX-9 SuperNIC 來負責支撐資料中心的高速網路需求。最後,Bluefield-4 DPU 協助處理非核心運算任務,分擔 CPU 與 GPU 的工作負載,使其專注於 AI 模型運算之外,Spectrum-6 乙太網路交換器則是為 AI 數據中心提供下一代網路基礎設施。
由於輝達在現場展示了具體的配置方案,例如 Nvidia Vera Rubin NVL72。該系統整合了 36 顆 Vera CPU 與 72 顆 Rubin GPU,搭配多組 NVLink 交換器與 DPU,形成一個龐大的運算叢集。對此,市場人士指出,阻礙 LLM 廣泛應用的最大障礙之一便是昂貴的成本。隨著模型體積與複雜度與日俱增,支撐其運行的基礎設施費用已飆升至天文數字。因此,透過 Rubin 平台大幅削減 Token 成本,使大規模 AI 部署變得更具可行性與商業吸引力。
輝達還透露,第一批 Rubin 平台預計將於 2026 年下半年開始交貨給合作夥伴。首波採用名單包括雲端運算大廠 Amazon Web Services (AWS)、Google Cloud 以及 Microsoft (微軟)。因此,雖然 Rubin 平台並非針對普通消費者設計的零售產品,但其對 AI 產業的影響將深遠地滲透至大眾生活。若輝達的這一大膽策略取得成功,Rubin 將不僅僅是硬體的升級,更將開啟一個運算規模可控、AI 應用無處不在的新時代。
(首圖來源:視訊截圖)





