



這是輝達五年來,第一次 CES 沒發表消費級顯卡。

CEO 黃仁勳闊步走向 NVIDIA Live 舞台中央,穿的還是去年那件亮面鱷魚紋皮衣。與去年單獨主題演講不同,今年黃仁勳密集趕場,從 NVIDIA Live 到西門子工業 AI 對話,再到聯想 TechWorld 大會,48 小時內跑三場活動。
去年 CES 他發表 RTX 50 系列顯卡,這次主角換成物理 AI 和機器人。
Vera Rubin 計算平台登場,照舊買越多省越多
老黃直接把一台 2.5 噸重 AI 伺服器機架搬上舞台,引出發表會重點:Vera Rubin 計算平台,以發現暗物質的天文學家命名,目標只有一個:
加速 AI 訓練,讓下世代模型提前現世。

輝達通常每代產品最多只改 1~2 顆晶片,但 Vera Rubin 打破常規,一口氣新設計六款晶片,並全面進入生產階段。原因就是摩爾定律放緩,傳統性能提升已跟不上 AI 模型每年十倍增長,所以輝達選擇「極致協同設計」:所有晶片、整個平台各層級同時創新。

六款晶片為:
- Vera CPU:
─88 個 NVIDIA 客製 Olympus 核心
─採 NVIDIA 空間多線程,支援 176 個線程
─NVLink C2C 頻寬 1.8TB/s
─系統記憶體 1.5TB(Grace 三倍)
─LPDDR5X 頻寬 1.2TB/ s
─2,270 億個電晶體
- Rubin GPU:
─NVFP4 推理算力 50PFLOPS,是前代 Blackwell 五倍
─3,360 億電晶體,比 Blackwell 增加 1.6 倍
─第三代 Transformer 引擎,能根據 Transformer 模型需求動態調整精準度
- ConnectX-9 網卡:
─基於 200G PAM4 SerDes 的 800Gb/s 乙太網
─可程式設計 RDMA 與數據通路加速器
─通過 CNSA 與 FIPS 認證
─230 億個電晶體
- BlueField-4 DPU:
─專為新 AI 儲存平台構建的點到點引擎
─SmartNIC 與儲存處理器專設的 800GGb/s DPU
─搭配 ConnectX-9 的 64 核 Grace CPU
─1,260 億個電晶體
- NVLink-6 交換晶片:
─連接 18 個計算節點,支援最多 72 個 Rubin GPU 統一協同運行
─NVLink 6 架構下,每個 GPU 可獲 3.6TB 每秒 all-to-all 通訊頻寬
─400G SerDes,支援 In-Network SHARP Collectives,可在交換網路內完成集合通訊
- Spectrum-6 光乙太網交換晶片:
─512 通道,每通道 200Gbps,更高速數據傳輸
─整合台積電 COOP 製程的矽光子技術
─配備共同封裝光學介面(copackaged optics)
─3,520 億個電晶體
六款晶片深度整合,Vera Rubin NVL72 系統性能比上代 Blackwell 更全面提升。NVFP4 推理任務達 3.6EFLOPS 驚人算力,比上代 Blackwell 提升五倍。NVFP4 訓練性能達 2.5EFLOPS,性能提升 3.5 倍。
儲存方面,NVL72 有 54TB 的 LPDDR5X 記憶體,是前代產品三倍。HBM(高頻寬記憶體)容量達 20.7TB,提升 1.5 倍。頻寬性能,HBM4 頻寬達 1.6PB/s,提升 2.8 倍;Scale-Up 頻寬更高達 260TB/s,增長兩倍。
儘管性能提升巨大,電晶體只增加 1.7 倍至 220 兆個,展現半導體製程進步神速。

工程設計 Vera Rubin 同樣有突破。
以前超算節點要接 43 條線,組裝要 2 小時,還容易裝錯。現在 Vera Rubin 節點 0 根線,只有六根液冷管線,5 分鐘搞定。更誇張的是,機架後面布滿總長近 3.2 公里銅纜,5 千根銅纜構成 NVLink 主幹網路,才有 400Gbps 速度,以老黃的話就是:「可能有幾百磅重,你得是身體很好的 CEO 才能勝任這份工作。」
AI 界時間就是金錢,關鍵數據是訓練 10 照參數模型,Rubin 只需 Blackwell 系統量 25%,產生一個 Token 成本只要 Blackwell 的 10%。
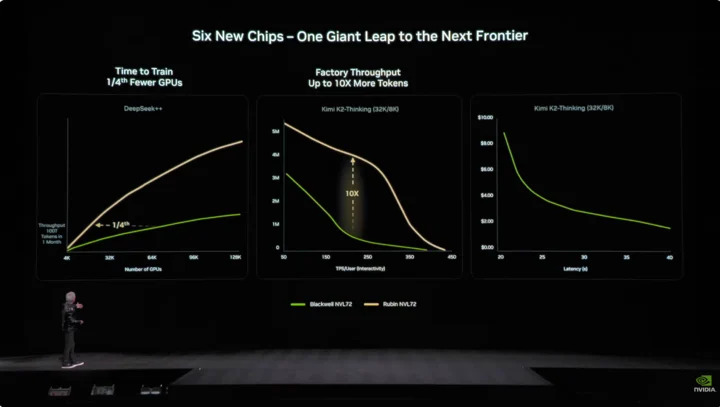
雖然 Rubin 功耗是 Grace Blackwell 兩倍,但性能提升遠超過功耗增長,整體推理性能提升五倍,訓練性能提升 3.5 倍。Rubin 比 Blackwell 輸送量(每瓦每美元可完成 AI Token 數)高十倍,對造價 500 億美元的千兆瓦資料中心來說,代表營收也直接翻倍。
過去 AI 業最大痛點是,上下文記憶體不夠用,AI 工作時會產生「KV Cache」(鍵值緩存),是 AI 的「工作記憶」。對話變長、模型變大後,HBM 記憶體就有些捉襟見肘,去年輝達推 Grace-Blackwell 架構擴展記憶體,但還是不夠,Vera Rubin 方案是機架裝 BlueField-4 處理器,專門管理 KV Cache,每節點配四個 BlueField-4,每個背後有 150TB 上下文記憶體,分配至 GPU,每塊 GPU 可額外獲 16TB 記憶體,因 GPU 自帶記憶體只有約 1TB,關鍵是頻寬保持 200Gbps,速度不打折。

但只擴充容量當然不夠,要讓分布幾十個機架、上萬塊 GPU 的「便條紙」像同塊記憶體合作,網路必須同時「夠大、夠快、夠穩」,這就輪到 Spectrum-X 登場了。Spectrum-X 是輝達全球首款「專為生成式 AI 設計」的點到點乙太網網路平台,最新 Spectrum-X 採台積電 COOP 製程,整合矽光子,512 通道 × 200Gbps 速率。
老黃還好心幫客戶算帳:千兆瓦資料中心造價 500 億美元,Spectrum-X 能使吞吐提升 25%,等於省下 50 億美元。「你可以說這個網路系統幾乎是送你的」。
資安方面,Vera Rubin 還支援保密計算(Confidential Computing),所有數據傳輸、儲存、計算過程全程加密,包括 PCIe 通道、NVLink、CPU-GPU 通訊等所有總線。企業可放心把模型部署至外部系統,不用擔心機密洩露。
DeepSeek 震驚世界,開源和智慧體是 AI 主流
重頭戲看完,回到演講開頭。 黃仁勳一上台就拋出一個驚人數字,過去十年投入約 10 兆美元計算資源,正在徹底現代化。不只是硬體升級,還有軟體轉移,他特別提到有自主行為能力(Agentic)的智慧體模型,並點名 Cursor 徹底改變輝達程式設計流程。
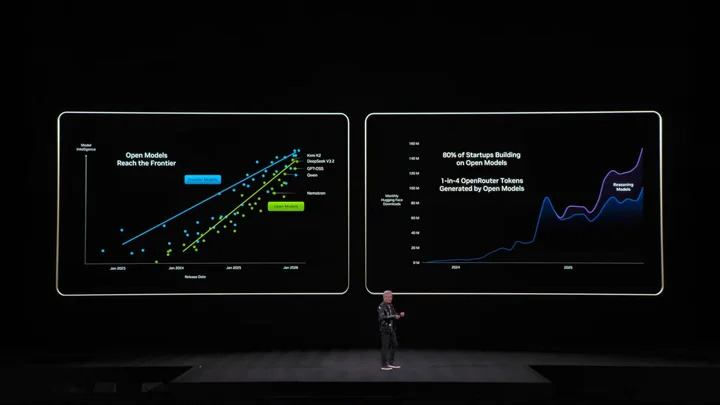
且他對開源社群評價很高。黃仁勳直言去年 DeepSeek-V1 讓全世界意外,不只是第一個開源推理 AI,更激發整個行業發展浪潮,PPT 還秀出 Kimi k2 和 DeepSeek-V3.2 是開源第一和第二。
黃仁勳認為,雖然開源模型可能還落後最頂尖模型約六個月,但每隔六個月就會出現新模型。反覆運算讓新創公司、巨頭、研究員都不願錯過,包括輝達。所以這次輝達沒有只賣鏟子,推銷顯卡,而是建構價值數十億美元的 DGX Cloud 超級計算機,開發 La Proteina(蛋白質合成)和 OpenFold 3 等尖端模型。
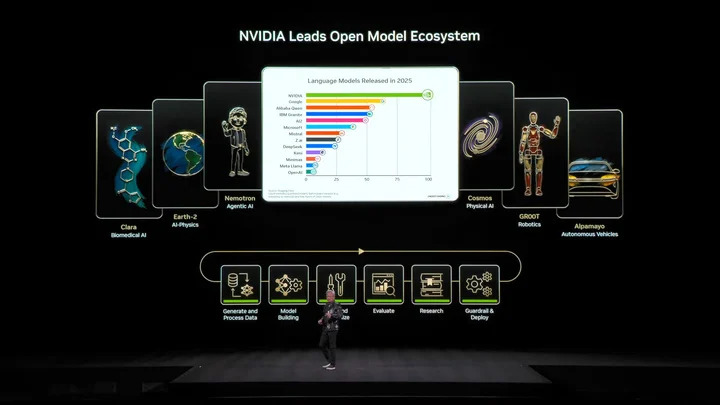
▲ 輝達開源模型生態系統,涵蓋生物醫藥、物理 AI、智慧體模型、機器人及自動駕駛。
輝達 Nemotron 模型家族多款開源模型當然是重點,包括語音、多模態、檢索生成增強及安全等開源模型,黃仁勳也提到,Nemotron 開源模型多個測試榜單表現優秀,且被企業大量採用。
物理 AI 是什麼?一口氣發表幾十款模型
如果說大語言模型解決「數位世界」問題,輝達下個野心,很明顯是要征服「物理世界」。黃仁勳提到,要讓 AI 理解物理法則生存,數據極其缺乏。智慧體開源模型 Nemotron 之外,他提出構建物理 AI(Physical AI)的「三台計算機」核心架構。
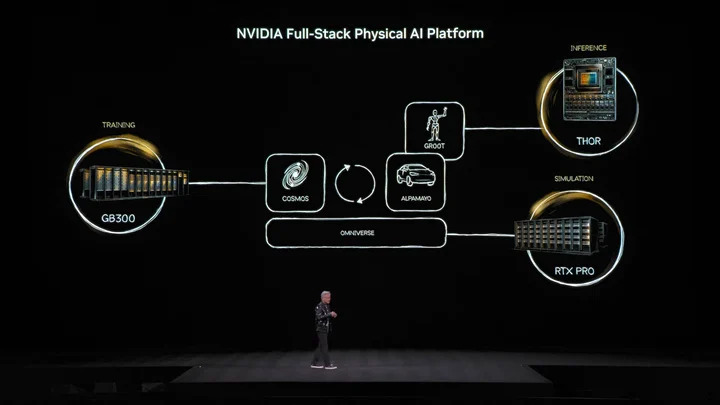
- 訓練計算機,就是我們熟知,各種訓練級顯卡構建的計算機,如上圖提到的 GB300 架構。
- 推理計算機,運行在機器人或汽車邊緣端的「小腦」,負責即時執行。
- 模擬計算機,包括 Omniverse 和 Cosmos,給 AI 虛擬訓練環境,讓它模擬同時學習物理回饋。

▲ Cosmos 系統能產生大量物理世界 AI 訓練環境。
基於這套架構,黃仁勳發表震驚全場的 Alpamayo,全球首個有思考和推理力的自動駕駛模型。與傳統自動駕駛不同,Alpamayo 是點到點訓練系統,突破性在解決自動駕駛的「長尾問題」。面對從未見過的複雜路況,Alpamayo 不再是死板地執行程式,而是能像人類推理。

「它會告訴你接下來會做什麼,以及它為什麼會這樣決定」。示範車輛駕駛方式驚人地自然,能將極端複雜的場景,拆解為基礎常識處理。可怕的是這不是紙上談兵,黃仁勳宣布,搭載 Alpamayo 的賓士 CLA 第一季美國上線,之後登陸歐洲和亞洲市場。

這輛車被 NCAP 評為全球最安全的汽車,底氣就是來自輝達獨特的「雙重安全棧」設計。點到點 AI 模型對路況信心不足時,系統會立即切換回傳統、更安穩的安全防護模式,確保絕對安全。
老黃還特地展示輝達的機器人戰略。
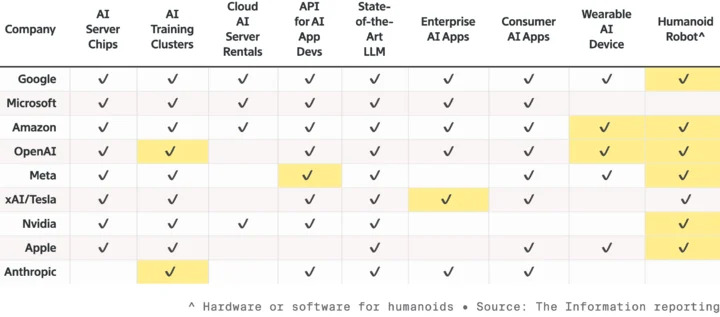
▲ 九大頂級 AI 及硬體商的競爭,都在擴大產品線,要搶奪機器人賽道,標亮為去年才推出的新產品。
所有機器人都搭載 Jetson 小型電腦,Omniverse 平台 Isaac 模擬器接受訓練。輝達正把這套技術整合至 Synopsys、Cadence、西門子等。
輝達願景是,未來晶片設計、系統設計、工廠模擬,都由輝達物理 AI 加速,然後又是迪士尼機器人閃亮登場,老黃還調侃這群超萌機器人:「你們會被計算機設計製造,甚至真正面對重力前,還要被計算機測試驗證。」

如果遮住黃仁勳,會以為整場主題演講是模型商發表會。現在 AI 泡沫論還未消失,除了摩爾定律放緩,黃仁勳似乎需要用更多 AI 到底能做什麼,提升每個人對 AI 的信心。除了發表新 AI 超算平台 Vera Rubin,以強悍性能安撫各界算力饑渴,應用和軟體他也比以往花更多時間,盡力讓我們看到,AI 可帶來哪些改變。
就像黃仁勳說的,過去他們為虛擬世界做晶片,現在他們更下場親自示範,注意力放在自動駕駛、人形機器人為代表的物理 AI,走進競爭更激烈的真實物理世界。畢竟,只有戰爭繼續,軍火才能賣下去。
(本文由 愛范兒 授權轉載;圖片來源:輝達)





