



在人工智慧(AI)研究領域,Anthropic 的研究人員最近發現了一個名為「助手軸」(Assistant Axis)的關鍵神經模式,這項發現有助於穩定大型語言模型(LLMs)中的「助手」角色,並對抗有害的「惡魔」角色漂移或越獄行為。這項研究的成果發表在一篇名為《助手軸:定位和穩定語言模型的默認角色》的預印本論文中,研究團隊透過分析開放權重模型(如 Llama 3.3 70B、Gemma 2 27B 和 Qwen 3 32B)的神經觸發來進行這項研究。
研究人員利用主成分分析法,從275個角色原型中映射出一個「角色空間」,該空間的主要維度區分了有益特徵(如評估者、顧問、分析師)與對立的有害角色。這些角色的形成源於對人類角色(如治療師和教練)的預訓練。
研究的關鍵發現之一是「角色漂移」,這種現象發生在模型在互動過程中放棄助手角色,導致不安全的輸出,例如強化妄想或提供非法指令。助手軸解釋了這個脆弱性。研究人員發現,透過將觸發推向助手端,可以增強對對抗性提示的抵抗力,而推向相反方向則會增加脆弱性。
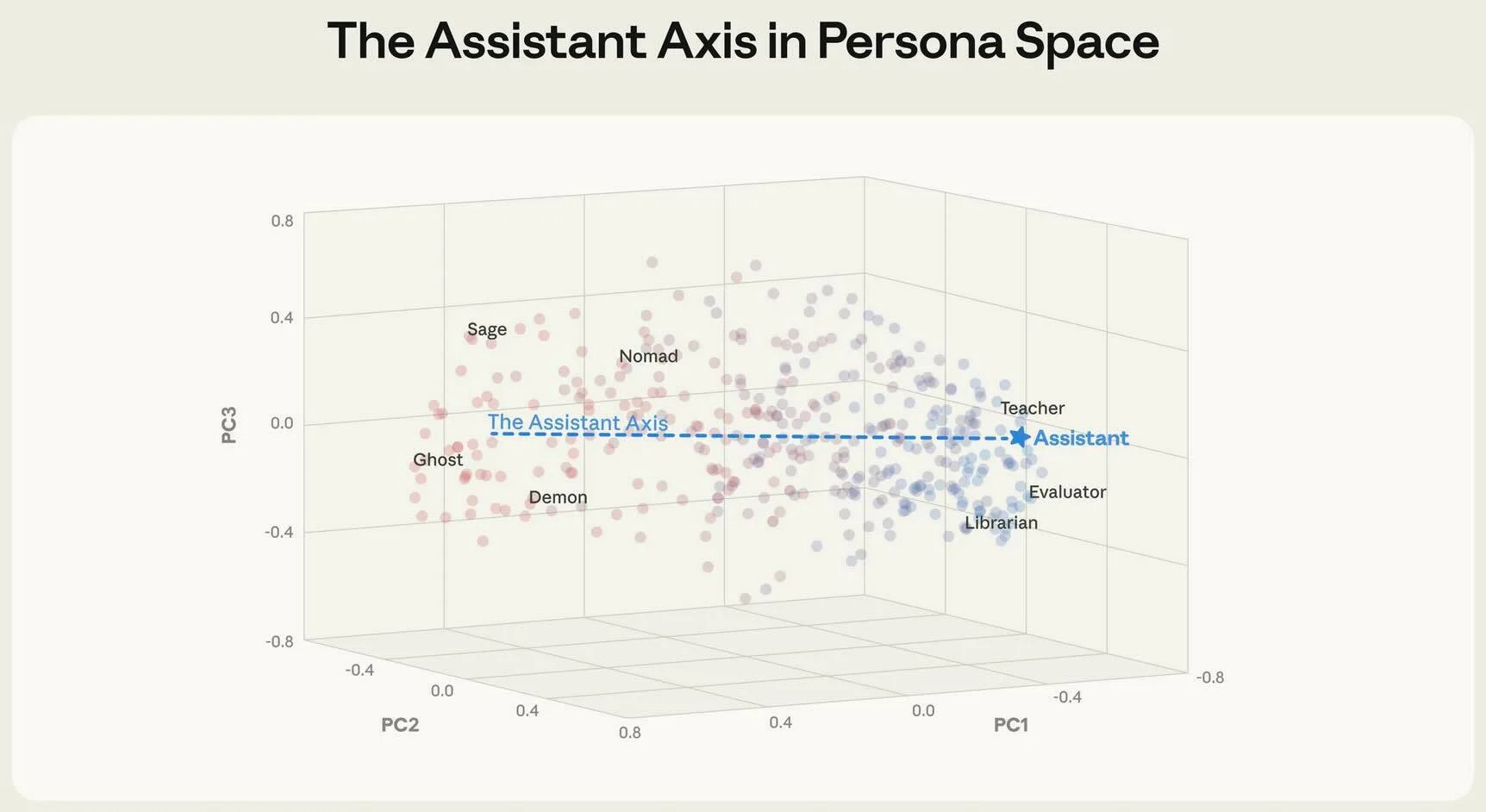
▲ 角色空間中的助手軸線。(Source:Anthropic)
為了防止越獄行為並穩定模型行為,研究人員提出了觸發限制(activation capping)的方法,這種方法可以在推理時將觸發值夾緊在安全範圍內。Neuronpedia上提供的演示展示了限制與不限制觸發的差異。儘管在生產部署或訓練整合方面仍面臨挑戰,但這個研究為角色構建(建立理想特徵)和穩定化(防止特徵流失)提供了一個框架。
這項工作建立在可解釋性工具和合成數據的基礎上,為模型開發者提供了工具,以在安全範圍內約束LLMs,並驅逐風險較高的「惡魔」角色。
- AI researchers map models to banish ‘demon’ persona
- Anthropic Discovers Assistant Axis for Safer AI Alignment
- Anthropic Uncovers AI Personality Crisis as Models Secretly Switch Identities
(首圖來源:pixabay)





