



隨著人工智慧技術的飛速發展,網路匿名性的保護傘正逐漸失效。根據蘇黎世聯邦理工學院(ETH Zurich)、Anthropic 以及機器學習對齊與理論學者計畫(Machine Learning Alignment and Theory Scholars program)於今年 3 月發布的一項最新研究,研究人員成功開發出一套自動化 AI 代理系統,能夠精準地將匿名帳號與真實身分進行關聯。
這項研究指出,AI 代理系統透過分析文本中的細微線索,如寫作習慣、零星的傳記細節、發文頻率及時間規律,來追蹤使用者的身分。在針對 Reddit、LinkedIn 及 Hacker News 等公開數據集的測試中,這套基於大型語言模型(LLM)的方法在 90% 的精確率下,成功識別了高達 68% 的匹配帳號。相比之下,傳統的非 LLM 計算技術幾乎無法達成有效的去匿名化。
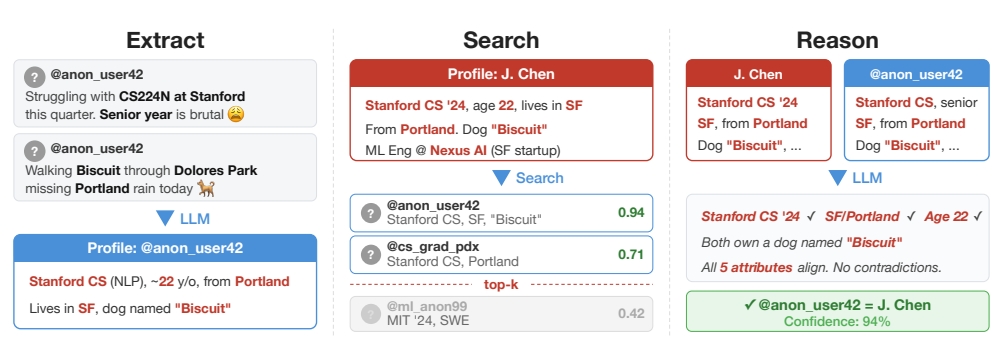
(Source:論文)
研究進一步揭示,AI 脫敏技術的威脅不僅在於其精準度,更在於其極低的成本與高度自動化。研究人員表示,整個實驗的成本不到 2,000 美元,平均每個個人檔案的分析成本僅需 1 至 4 美元(約台幣 32 元至 128 元)。這種經濟模式的轉變,意味著過去需要專業調查員耗費數小時才能完成的工作,現在 AI 僅需幾分鐘即可大規模完成,這大幅降低了追蹤匿名使用者的門檻。
儘管 AI 偵探的威脅日益增加,但專家認為隱私尚未完全終結。研究顯示,當資訊結構化程度較低時,AI 的識別率會顯著下降。例如,在分析僅提到一部電影的 Reddit 用戶時,成功率僅為 3%。牛津大學網路研究所副教授 Luc Rocher 指出,比特幣發明者中本聰(Satoshi Nakamoto)的身分至今仍是個謎,這說明在嚴格的保護措施下,匿名性依然可行。
為了應對日益嚴峻的隱私挑戰,研究人員建議使用者應採取更謹慎的防範措施,包括保持帳號獨立、限制個人細節的揭露,以及避免在特定時區的清醒時間發文等習慣。同時,研究團隊也呼籲 AI 實驗室應加強工具監管,社群平台則應嚴厲打擊大規模數據抓取行為,以共同維護網路使用者的隱私安全。
(首圖來源:AI 生成)





