


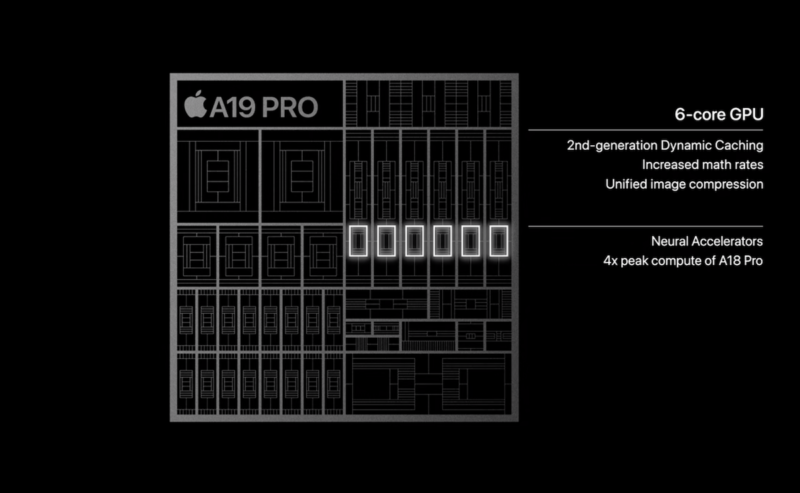
在 iPhone 17 Pro 的產品發布會上,除了光鮮亮麗的新裝置,從 A19 處理器架構圖中看似一項看似不起眼的技術升級卻在 AI 業界引發熱議。蘋果首次在自家 GPU 中加入矩陣乘法加速單元(Matrix Multiplication Acceleration Units),此舉被視為對現有 AI 算力瓶頸的重大突破,更預示著蘋果將正面迎戰 NVIDIA 在 AI 領域的主導地位。
長期以來,蘋果自研的 GPU 與 NVIDIA 顯示卡最大的差異之一,就是缺乏像 NVIDIA Tensor Core 這類專為張量運算設計的硬體加速核心。這也是 NVIDIA 在深度學習和大型語言模型(LLM)運算上能遙遙領先的關鍵。最新的 Tensor Core 不僅運算速度驚人,更原生支援多種浮點精度(如 FP64、TF32、BF16、FP16 等),能與各式大模型訓練及推論引擎完美配合。
雖然蘋果這次的 GPU 升級包含了矩陣乘法加速單元,但這並不等同於 NVIDIA 的 Tensor Core。Tensor Core 是一個更為複雜且全面的運算核心,它不僅能執行矩陣乘法,更針對多種低精度浮點運算(如 FP8、FP6)進行了深度優化,這些都是現代大模型訓練與推論的關鍵。換言之,蘋果的 GPU 雖然補上了矩陣運算這塊短板,但其原生支援的精度和運算效率,仍有待後續的技術發展來追趕。
矩陣乘法:AI 運算的核心
在深度學習的世界裡,無論是訓練還是推論,最核心且最頻繁的運算就是矩陣乘法(Matrix Multiplication)。你可以把一個神經網路想像成一系列複雜的數學運算,其中每個神經元之間的連接權重,都可以用一個巨大的矩陣來表示。當輸入數據(例如一張圖片、一段文字)進入這個網路時,它會與這些權重矩陣進行連串的乘法運算,以產生最終的輸出。
這就是為什麼「矩陣乘法」的運算速度,直接決定了 AI 模型訓練與推論的快慢。一個好的 AI 晶片,其效能高低很大程度上取決於它處理這些巨型矩陣乘法的能力。
擁抱 GPU 核心算力
過去,蘋果曾大力推廣其自家的「神經網絡引擎(ANE)」,試圖透過專用硬體來處理 AI 任務。然而,實際應用卻不如預期。
首先,ANE 的使用體驗極不友善,開發者必須將模型轉換成特定格式才能運行,過程繁瑣。其次,也是最重要的,ANE 的效能遠遠落後時代。由於蘋果最初並未預料到以 Transformer 架構為基礎的大型語言模型(LLM)會迅速崛起,這類模型對記憶體頻寬的需求極高,而 ANE 的頻寬效能卻表現平平。根據實測,ANE 的最大頻寬僅約 120GB/s,甚至不及 2016 年推出的 NVIDIA GTX 1060 顯示卡。這導致在現實應用中,幾乎沒有開發者會選擇使用 ANE 來運行大型模型。
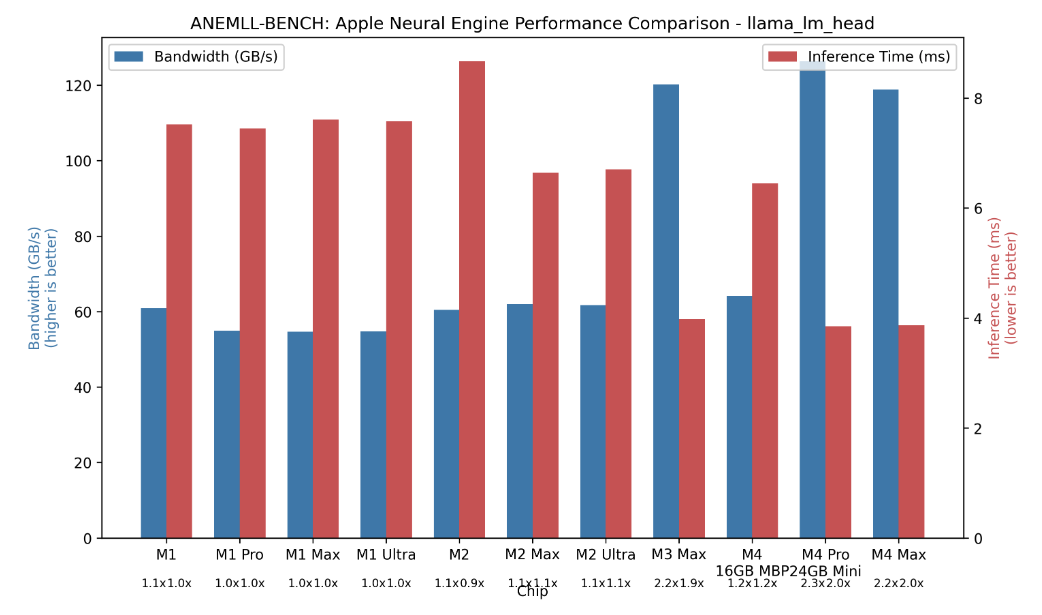
(Source:GitHub)
相較之下,蘋果的 GPU 效能則令人刮目相看。以 M2 Max 為例,其 LPDDR5x 統一記憶體的頻寬幾乎可以達到理論效能的 80%。這讓業界對下一代產品充滿期待。如果未來的 M5 Max 能搭載頻寬更高的 LPDDR6,其記憶體頻寬有望達到 900GB/s,將足以與主流消費級顯示卡一較高下。
M4 鋪路,M5 登場,PC 算力大戰可能登場嗎?
蘋果此舉並非空穴來風。在 M4 晶片上,蘋果已經開始試水溫,直接提供最高 512GB 統一記憶體的配置,這顯示蘋果早已意識到大模型對記憶體容量的龐大需求。
明年,隨著 M5 系列晶片在 MacBook Pro、Mac Mini 和 Mac Studio 等產品線上的全面鋪開,搭載矩陣乘法加速單元的新 GPU 勢必將大幅提升蘋果裝置在 AI 運算上的實力。這場轉變不僅讓蘋果告別了過去「雞肋」的 ANE,更可能改寫消費級 AI 裝置的競爭格局。
面對蘋果的強力進攻,NVIDIA、AMD 和 Intel 等晶片巨頭的壓力可想而知。可以預見,明年將成為個人電腦(PC)市場 AI 算力競爭的「究極之戰」。蘋果能否憑藉其硬體整合優勢與龐大的生態系,撼動 NVIDIA 在 AI 領域的霸主地位?這場科技大戰的未來發展值得我們拭目以待。
- Apple GPU Matrix Multiplication Acceleration Units: A Technical Breakthrough Reshaping AI Computing
- Apple adds matmul acceleration to A19 Pro GPU
(首圖來源:蘋果)





