



Google 研究團隊日前推出 VaultGemma,這是全球首個從頭開始使用差分隱私(Differential Privacy,DP)技術訓練的大型語言模型(LLM),參數規模達 10 億。該模型基於 Google 的 Gemma 2 架構,採用 26 層 Decoder-only Transformer 及多查詢注意力機制,序列長度限制在 1,024 tokens,以平衡效能與計算需求。
差分隱私技術透過在訓練資料中加入經過精密調整的噪聲,確保模型無法記憶或洩露任何單一訓練樣本的敏感訊息,提供數學層級的隱私保障。VaultGemma是首款在全訓練週期實施差分隱私的方法,不同於以往只在微調階段運用DP的做法。
Google團隊針對差分隱私引入的挑戰,提出了創新的「DP縮放法則」,揭示了噪聲量、批次大小與模型性能間的關係,並採用大規模批次訓練以維持模型穩定性,同時開發出降低計算成本的訓練策略。VaultGemma在各項基準測試(如MMLU、Big-Bench)上的表現,與同規模非私有Gemma模型相當,突破了過去私有模型性能大幅下降的瓶頸。
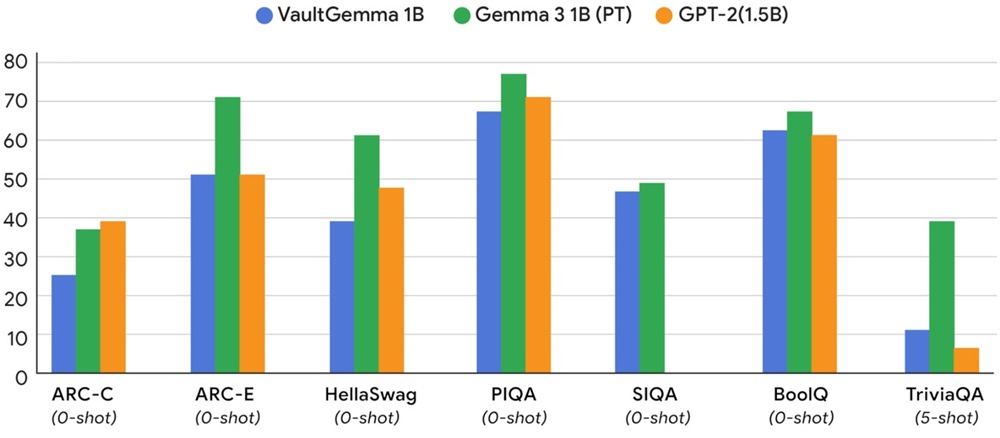
▲ 圖為VaultGemma 1B與其非隱私的對應模型(Gemma3 1B),以及一個較舊的基準模型(GPT-2 1.5B)之間的效能比較。研究結果量化了當前為實現隱私保護所需的資源投入,並證明現代的差分隱私訓練所產出的模型效用,已可媲美大約五年前的非隱私模型。(Source:Google)
此模型可廣泛應用於金融、醫療等重視數據隱私的領域,有效降低AI系統因資料洩漏所造成的風險,並助力建構更安全與負責任的AI生態。
VaultGemma權重已在Hugging Face與Kaggle平台開放下載,採用Gemma模型授權條款,允許用戶修改及分發,但嚴禁用於不當用途。
- Google releases VaultGemma, its first privacy-preserving LLM
- Google launches VaultGemma: privacy AI without compromising performance
- Google AI Releases VaultGemma: The Largest and Most Capable Open Model (1B-parameters) Trained from Scratch with Differential Privacy
- Google Releases VaultGemma LLM With Differential Privacy Under Open Source License
(首圖來源:Google)





