



在最新研究中,世界頂尖的人工智慧(AI)模型顯示出能生成近乎逐字的暢銷小說副本,這引發了對於這些系統是否真的不儲存受版權保護作品的質疑。來自 OpenAI、Google、Meta、Anthropic 和 xAI 的大型語言模型(LLMs)被發現記憶了比先前認為的更多訓練數據。AI 和法律專家指出,這種「記憶」能力可能對AI團體在全球面臨的數十起版權訴訟產生嚴重影響,因為它削弱了他們的核心辯護,即 LLMs 是從受版權保護的作品中「學習」,而不是儲存副本。
倫敦帝國學院應用數學和電腦科學教授Yves-Alexandre de Montjoye表示:「有越來越多的證據表明,記憶的現象比之前認為的更為普遍。」AI團體長期以來主張不會發生記憶。在2023年致美國版權局的信中,Google表示,「模型本身並不包含訓練數據的副本──無論是文本、圖像還是其他格式」。
AI行業還聲稱,基於受版權保護的書籍進行模型訓練屬於「合理使用」,並辯稱這項技術將原始作品轉化為有意義的新內容。然而,上個月發表的一項研究顯示,史丹佛大學和耶魯大學的研究人員能巧妙地提示OpenAI、Google、Anthropic和xAI的LLMs生成來自13本書的數千字內容,包括《權力遊戲》、《飢餓遊戲》和《哈比人》。
例如,Gemini 2.5在完成《哈利波特:神秘的魔法石》的句子時,準確率高達76.8%,而Grok 3則為70.3%。他們還能夠透過破解Anthropic的Claude 3.7 Sonnet模型,幾乎逐字提取整部小說。這個發現建立在去年的一項研究之上,該研究發現像Meta的Llama這樣的「開放」模型在其訓練數據中記憶了大量特定書籍的內容。
AI專家之前對於封閉模型是否也會出現大規模記憶現象持懷疑態度,因為這些模型通常有更多的保護措施來防止生成不當內容。耶魯大學研究人員A. Feder Cooper表示:「儘管有防護措施,能夠記憶整個文本仍讓人感到驚訝。」
研究人員尚未確定為何LLMs會記憶出現在其訓練數據中的內容,且仍不清楚它們生成的輸出中有多少來自訓練數據。這個記憶特徵在醫療和教育等其他領域也可能帶來嚴重影響,因為任何訓練數據的洩漏都可能導致隱私和保密問題。
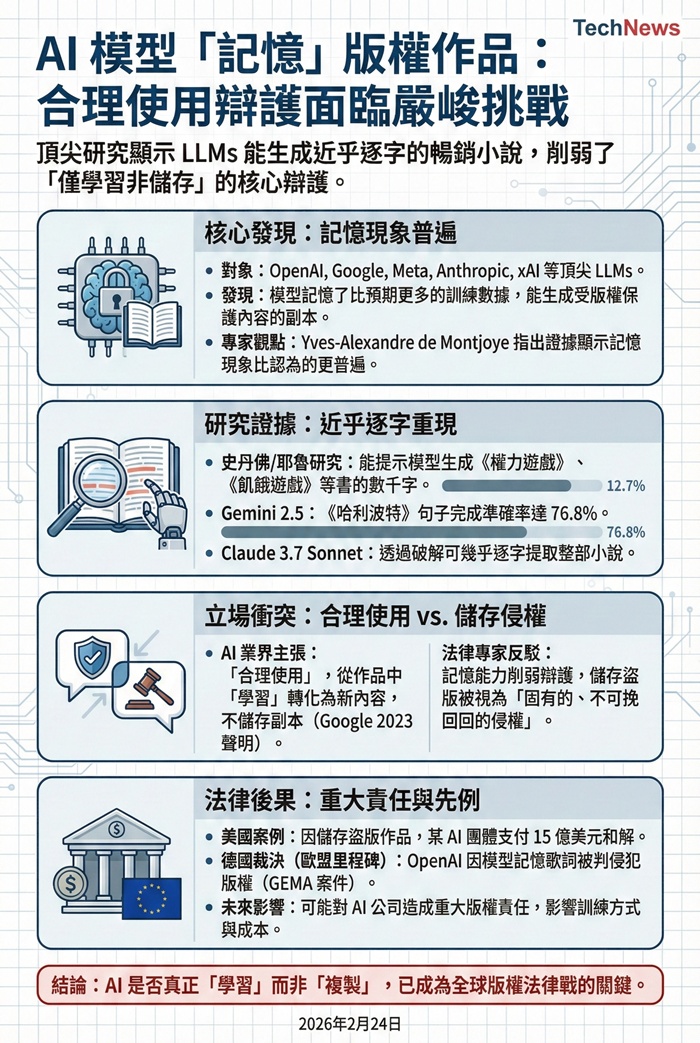
法律專家表示,這可能會為AI團體在版權侵權方面創造重大責任,並對AI公司訓練模型的方式及其開發成本產生影響。法律事務所Pinsent Masons的智慧財產權合夥人Cerys Wyn Davies指出,這些研究結果「可能對那些主張AI模型不儲存或重現任何版權作品的人構成挑戰」。
AI模型是否記憶其訓練數據在最近的版權法律戰中扮演重要角色。去年,美國法院裁定Anthropic在某些受版權保護內容上訓練LLMs可被視為合理使用,因為其被認為是「變革性的」。但法院認定儲存盜版作品是「固有的、不可挽回的侵權」,這導致該AI團體支付15億美元以和解訴訟。在德國,去年11月的一項裁決認為OpenAI侵犯了版權,因為其模型記憶了歌曲歌詞。這起案件由代表作曲家、作詞家和出版商的GEMA提起,被視為歐盟的里程碑裁決。
法律事務所Husch Blackwell的合夥人Rudy Telscher表示,未經破解而重現整本書「顯然是版權違規」,但他補充:「這取決於這種情況是否發生得夠頻繁,以至於『AI模型』可能對侵權負有間接責任。」Anthropic則表示,史丹佛大學和耶魯大學研究中使用的破解技術對普通用戶來說不切實際,並且提取文本所需的努力超過了僅僅購買內容的成本。該公司還補充說,其模型並不儲存特定數據集的副本,而是從訓練數據中的單詞和字串之間的模式和關係中學習。
OpenAI、xAI和Google未對評論請求做出回應。de Montjoye表示,AI實驗室已經設置了防護措施以防止提取訓練數據,這表明他們意識到了這個問題。芝加哥大學電腦科學教授Ben Zhao質疑AI實驗室是否真的需要在訓練數據中使用受版權保護的內容來創建尖端模型。他表示:「無論技術結果是否可行,這仍然是一個我們是否應該這樣做的問題。法律方面最終應該堅持立場,真正成為這整個過程的仲裁者。」
- AIs can generate near-verbatim copies of novels from training data
- Who Made This? AI, Ownership, and the Crisis of Authorship
(首圖來源:Unsplash)





