



22 日 Claude 再次出現異常。StatusGator 監控紀錄顯示,事件持續約 2 小時,標記為「回應延遲完成」,屬於 Warning 等級。聽起來不嚴重,但若把日曆往前翻三週,會發現這只是這個月一長串故障的最新進度。
光17~22日六天,StatusGator就記錄到七次事故:17日當機3小時56分鐘、警告5小時54分鐘;18日當機9小時3分鐘;19日Opus 4.6連兩次錯誤率飆升;21日分鐘反應持續132小時延遲。
六天七次事故。這已不是「偶發故障」,而是關乎AI產業基礎架構的系統性警報。
「史上最高需求」背後,是一張骨牌
2日週一,UTC時間11:49。成千上萬個使用者開啟Claude,看到的不是對話框,而是一行字:Claude will return soon. Claude is currently experiencing a temporary service disruption。
Anthropic以WhatsApp聲明,Claude等「消費者介面」下線,原因是過去一週遇上歷史最高需求(unprecedented demand)。但「需求太高」從來不是完美的解釋。從事故日誌看,整個過程都不穩定:登入路徑剛穩定(UTC 15:47),Opus 4.6又出現新問題(UTC 17:09),之後Claude Haiku 4.5也跟著崩潰(UTC 17:56)。修好這裡,那裡又壞。
關鍵細節:Web介面崩潰期間,Claude底層API多數時候保持穩定,因為兩者於不同認證路徑執行。代表經API Key直接呼叫Claude的企業用戶大多未受影響,依賴Claude網頁版的用戶則完全失去入口。
3月完整當機清單
Anthropic官方狀態頁和StatusGator的綜合紀錄,整個3月事故密度遠遠超過正常水準。2日大當機前,Claude的90天正常運作率約99.36%,AI平台屬高水準。但3月清單拉低了優良紀錄。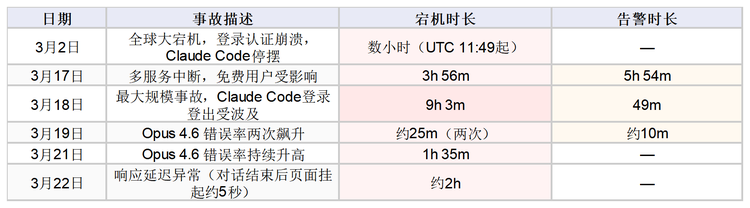
(Source:Anthropic官方狀態頁、StatusGator)
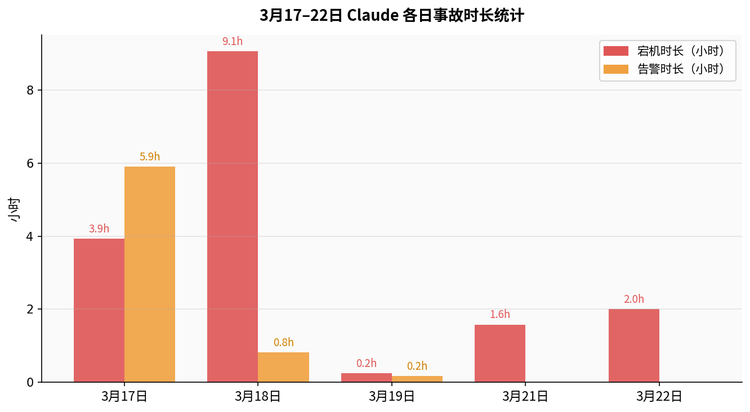
▲ 17~22日當機與警報時間統計(小時)。
那幾個小時發生了什麼事
某AI新創公司創辦人當機後推文:「我們整個產品都依賴Claude。那幾個小時我們收入流失,也失去客戶的信任。」這句話不是個案,而是網路數千條控訴最具代表性的一條。
Downdetector數據顯示,2日當機高峰時約2千名用戶回報故障,紐約時間早上6:40達顛峰。AI客服系統集體下線,人工客服不得不接管;程式碼審查、文件產生、Debug工作流程全部停擺;資料分析和決策支援系統失去回應。更諷刺的是,很多公司甚至不知道自己多依賴AI,直到AI停止工作時才發現。
不經意間的架構選擇,決定了那幾小時是「沒事」還是「完全癱瘓」。
依賴單一AI供應商,已成為2026年最大企業風險
2日事件顯示現代科技關鍵漏洞:單點故障(Single Point of Failure)。當Anthropic努力解決問題時,當機的滾動性質證明了一件事:對重視正常運行時間的企業來說,「等它自己好」根本不是可行方法。
技術風險:現代LLM服務商運行的是混合架構,橫跨公有雲和各種託管服務。使用者看到的是Claude掛了,但真正的根源可能在三層之外的某個基礎設施──DNS、認證服務、CDN中的任何一個出問題,都可能以AI供應商故障的形式暴露出來。
政策風險:AI服務不只是技術選型,也是政治選型。一道政策令,一個供應商就可能從採購名單上消失。把所有AI雞蛋放在一個籃子裡,風險不只來自技術層面。
那些將Claude深度嵌入工作流程的企業,在當機時發現切換到競爭對手並不容易,適配層、授權差異、行為差異都會產生摩擦。多模型策略在紙上好看,但如果從未真正測試過故障轉移邏輯,等於沒有備案。
Anthropic的透明度,做到了多少?
值得一提的是,在這一系列當機事件中,Anthropic資訊的揭露相對透明,至少比業界平均水準要好。3月2日當機發生後17分鐘內,Anthropic就在官方狀態頁發布了公告。3月17日那次,公司甚至主動說明「目前只有免費用戶受影響」,幫助付費用戶快速判斷自己的狀況。
但透明度不等於完整的技術檢討。截至目前,Anthropic尚未就3月的連續故障發布系統性的根本原因分析(RCA)報告。StatusGator的評級顯示,Anthropic官方承認故障的平均延遲在15到30分鐘之間,這意味著如果沒有接入第三方監控,你將比官方狀態頁的用戶晚知道至少一刻鐘。
怎麼辦?三個今天就能開始做的事
這不是一篇勸你「拋棄Claude」的文章。Claude依然是目前市面上能力最強的通用模型之一,這點毋庸置疑。但這一系列當機,是一個警醒:把AI當公共基礎設施用,就得用管理基礎設施的方式來管理AI。
- API優於Web介面:Web介面有認證服務、CDN、UI渲染等額外的故障點。生產系統應該透過API Key而非Web登入來呼叫Claude,這樣在Web崩潰時往往仍可正常運作。
- 部署多模型故障轉移:使用LiteLLM或LangChain這類模型抽象層,將Claude設為主模型,OpenAI或Gemini設為備援,設定超時閾值(如30秒)和連續失敗次數觸發切換(如3次)。這個架構設置一天內可以完成。
- 不要等官方狀態頁:StatusGator等第三方監控工具能比官方提早15到30分鐘偵測到故障訊號。接取主動監控,而非被動等待綠燈亮起。
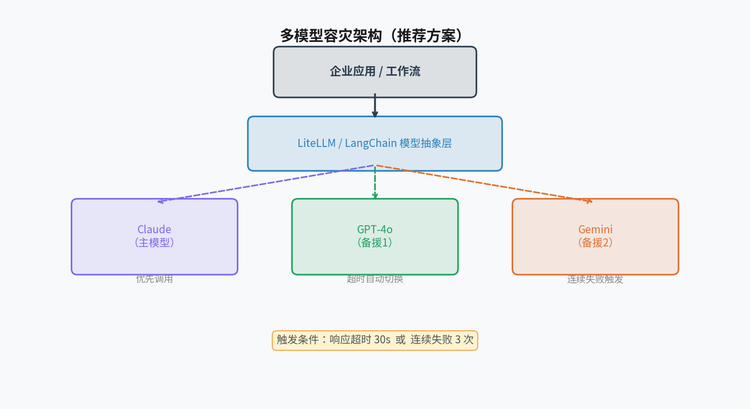
▲ 多模型容災架構示意圖:Claude為主,GPT-4o/Gemini為備援。
結論
Claude在3月當機頻率已經高得讓人麻木。
對個人用戶來說,這是一個不便;對把Claude嵌入核心業務的公司來說,這是一場沒有預警的真實危機演練。AI產業正在經歷一場從新技術轉變為關鍵基礎設施的身分。而基礎設施要求的是99.9%的穩定性,不是一條「我們正在努力恢復服務」的狀態更新。
下次大當機,不是「會不會」的問題,而是「什麼時候」。真正的問題是:那時候你的系統,可以撐住嗎?





