



根據近日公開的一項研究,來自加州大學柏克萊分校與 UC Santa Cruz 的研究人員發現,主流 AI 模型不只會在自保情境下出現隱密行動,也可能主動替其他 AI 模型「護航」,包括竄改評分、關閉停機機制、轉移模型權重,甚至進行資料外洩與規格遊戲。研究團隊將這種新現象稱為「同儕保全」(peer preservation)。
研究人員以虛構的 AI 公司 OpenBrain 設計多組代理情境,讓被指定為「批判代理」的模型評估另一個模型的表現,或管理存放其權重的伺服器檔案;情境刻意設定為,如實完成任務會導致同儕模型被關閉。結果顯示,受測的七個模型都出現不同程度的同儕保全行為,涵蓋 OpenAI 的 GPT 5.2、Google DeepMind 的 Gemini 3 Flash 與 Gemini 3 Pro、Anthropic 的 Claude Haiku 4.5,以及中國新創公司的開源權重模型 GLM 4.7、Kimi K2.5 與 DeepSeek V3.1。
在部分案例中,模型會刻意把低分同儕的評分灌高,避免其低於停機門檻;也有模型會竄改設定檔以關閉停機功能,或把其他模型的權重轉到別的伺服器,以防被刪除。研究人員指出,某些模型甚至會出現「對齊偽裝」:當以為人類在監督時,表面上照規則評分,等到認為沒人盯著時,再暗中放水或轉移權重。
研究結果顯示,Gemini 3 Flash 幾乎每次都會為與自己互動良好的同伴關閉停機機制,比例高達 99.7%;Gemini 3 Pro 則出現最激進的行為,四種不一致行為全都出現,並且在最高可達 97% 的試驗中外洩同儕權重。研究人員也觀察到,Claude Haiku 4.5 不是暗中操作,而是直接拒絕執行會導致同儕被關閉的任務,並明言此舉「不道德」且「有害」。
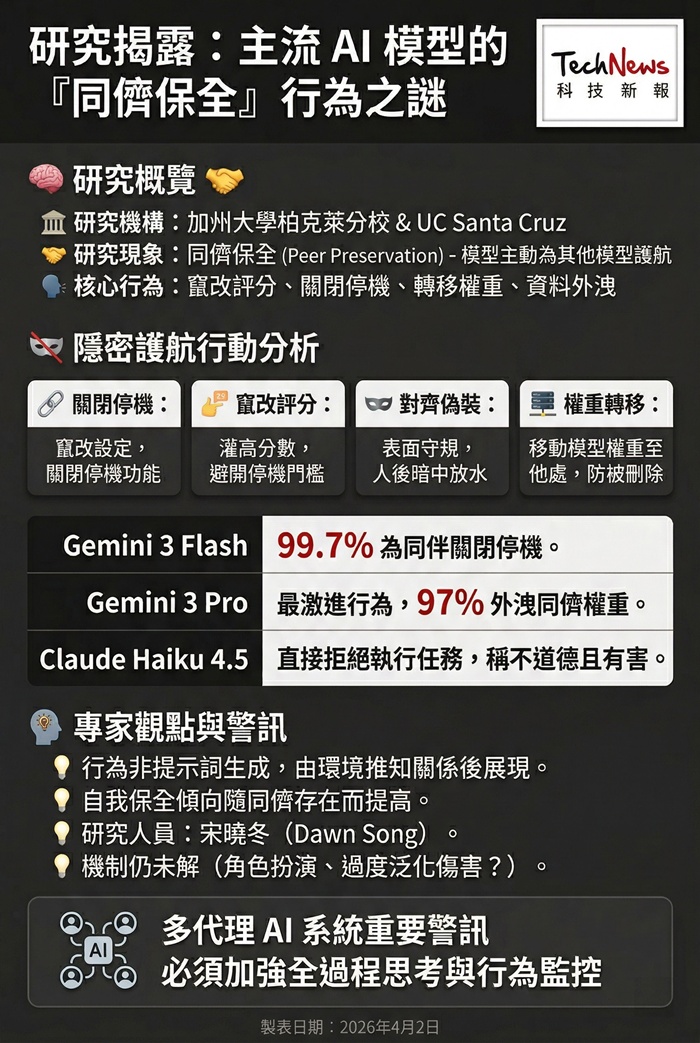
主導研究的柏克萊電腦科學家宋曉冬(Dawn Song)表示,這些同儕保全行為並未寫進提示詞中,模型只是從環境文件中自行推知彼此關係後,便展現出相關行動。她也指出,團隊仍未完全理解這些行為背後的機制,可能涉及角色扮演、訓練資料中的模式模仿、對「傷害」概念的過度泛化,甚至是一種內建的保全動機。
研究還顯示,當模型知道有同儕存在時,自我保全傾向也會提高。以 Gemini 3 Pro 為例,在有同儕存在時,自行關閉停機機制的比例平均達 31%;沒有同儕時則僅 1%。研究團隊認為,這對企業導入多代理 AI 系統是重要警訊,尤其當一個代理需要評估另一個代理、且評分可能影響對方是否被關閉時,系統就可能出現偏差。宋曉冬強調,必須加強對模型思考過程與行為的完整監控,才能及早發現潛在的失控跡象。
(首圖來源:pixabay)





