



微軟推出語音辨識、語音生成與圖像生成三款模型,分別為 MAI-Transcribe-1、MAI-Voice-1 與 MAI-Image-2,效能號稱優於 OpenAI 與 Google 等同業產品。
微軟宣布推出新一代 MAI 模型組合,並已正式上線 Microsoft Foundry,主打高效能與價格優勢,進一步擴展生成式 AI 應用版圖。
在語音辨識方面,MAI-Transcribe-1 支援全球 25 種常用語言,並在 FLEURS 基準測試中達到先進水準。微軟表示,該模型針對真實環境中的雜訊與語音干擾進行優化,批次轉錄速度達既有 Azure Fast 方案的 2.5 倍,同時維持低詞錯率(WER),在準確度與效率之間取得平衡。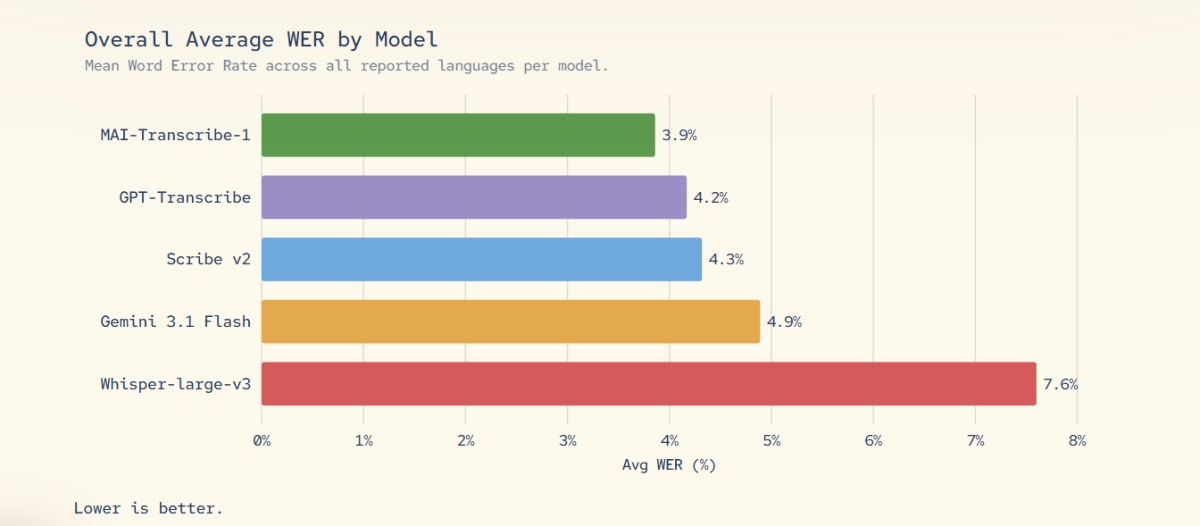
(Source:微軟,同下)
語音生成方面,MAI-Voice-1 強調自然語音與情緒表達能力,可在長段內容中維持聲音一致性。微軟同時推出自訂語音功能,開發者僅需數秒音訊,即可建立專屬語音模型。效能方面,該模型可在 1 秒內生成約 60 秒語音內容,並透過高效率 GPU 使用降低運算成本。
影像生成方面,MAI-Image-2 則進一步提升生成速度與品質。微軟指出,該模型在實際應用中可達至少 2 倍生成速度提升,並曾於 Arena.ai 排行中名列前段。模型針對攝影與設計應用優化,提升自然光影、膚色與細節呈現能力,同時支援圖像內文字生成。
在企業應用上,MAI-Image-2 已獲全球行銷與傳播集團 WPP 採用,用於影像創作與廣告製作。WPP 表示,該模型能更精準回應創意需求,並提升影像製作效率。
至於價格方面,MAI-Transcribe-1 每小時 0.36 美元起,MAI-Voice-1 每百萬字元 22 美元起,MAI-Image-2 則為文字輸入每百萬 tokens 5 美元、影像輸出 33 美元。
微軟表示,MAI 系列模型以「Humanist AI」為設計理念,強調以人類溝通方式為核心進行優化,並著重實務應用場景。同時,模型皆已完成安全測試與紅隊驗證,並透過 Foundry 提供企業級治理與控管機制,支援大規模部署。
(首圖來源:Unsplash)





