



MLCommons 發布了最新的 MLPerf 2.0 基準測評結果。在新一輪的測試中,MLPerf 新添加了一個對象檢測基準,用於在更大的 OpenImages 數據集上訓練新的 RetinaNet。MLperf 表示,這個新的對象檢測基準能夠更準確反映適用於自動駕駛、機器人避障和零售分析等應用的先進機器學習訓練成果。
MLPerf 2.0的結果與去年12月發布的v1.1結果大致相同,AI的整體性能比上一輪發布提高了大約1.8倍。
有21家公司和機構在最新測試中提交了MLPerf基準測試的成績,提交總數超過了260份。
NVIDIA 依然「打滿全場」
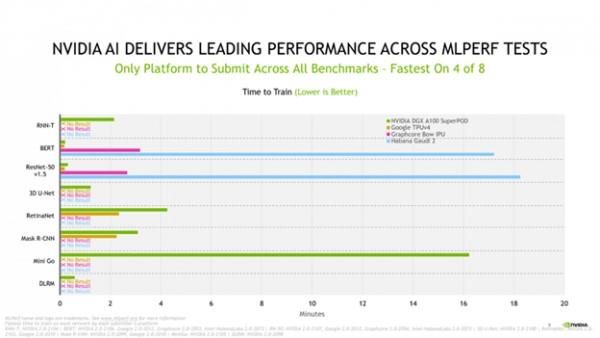
本次測試中,NVIDIA依然是唯一完成2.0版本中全部8項基準測試的參與者。這些測試囊括了目前流行的AI用例,包括語音辨識、自然語言處理、推薦系統、目標檢測、圖像分類等。
除了NVIDIA之外,沒有其他加速器執行完所有基礎測試,而NVIDIA自2018年12月首次向MLPerf提交測試結果以來,就一直完成所有基礎測試。
共有16家合作夥伴使用了NVIDIA平台提交本輪測試結果,包括華碩、百度、中國科學院自動化研究所、戴爾科技、富士通、技嘉、新華三、慧與、浪潮、聯想、寧暢和超微。此次測試中NVIDIA及其合作夥伴占了所有參賽生態夥伴的90%。
這顯示出了NVIDIA模型良好的通用性。
通用性在實際生產中,為模型協同工作提供了基礎。AI應用需要理解用戶要求,並根據要求對圖像進行分類、提出建議並以語音訊息的形式進行回應。
要完成這些任務,需要多種類型的AI模型協同工作。即使是一個簡單的用例也需要用到將近10個模型,因此AI模型通用性需達到一定水準。

好的通用性意味著用戶在整個AI流程中可以盡可能的使用相同的設施工作,並且還能夠相容未來可能出現的新需求,進而延長基礎設施的使用壽命。
AI 處理性能三年半提高 23 倍
在本次基準測評結果中,NVIDIA A100仍然保持了其單晶片性能的領導者地位,在8項測試中,有4項取得最快速度的成績。
兩年前,NVIDIA在MLPerf 0.7的基準測試中首次使用了A100 GPU,這次已經是NVIDIA第四次使用該GPU提交基準測試成績。
自MLPerf問世以來的三年半時間裡,NVIDIA的AI平台在基準測試中已經實現了23倍的性能提升。而自首次基於A100提交MLPerf基準測試兩年以來,NVIDIA平台的性能也已經提高了6倍。
性能的不斷提升得益於NVIDIA在軟體上的創新。持續釋放了Ampere架構的更多性能,如在提交結果中大量使用的CUDA Graphs可以最大限度減少跨多加速器執行的啟動開銷。
值得注意的是在本輪測試中NVIDIA沒有選擇使用最近發布的Hopper GPU,而是選擇了Ampere架構的NVIDIA A100 Tensor Core GPU。
NVIDIA的Narasimhan表示他們更希望專注於商業上可用的產品,這也是NVIDIA選擇在本輪中基於A100提交結果的原因。
鑑於新的Hopper Tensor Cores能夠應用混合的FP8和FP16精度的數據,而在下一輪MLPerf測試中NVIDIA很有可能會採用Hopper GPU,可以預見在下一輪基準測試中,NVIDIA的成績有望取得更大的成長。





