



12 月 7 日深夜,Google 突然重量級發布 AI 殺手鐧──Gemini。多模態 Gemini 可以理解、操作和結合不同類型的資訊,包括文字、程式碼、音訊、圖像和視訊。
在去年ChatGPT發布不到兩週後,Google就已經拉響「紅色警報」來應對挑戰。但緊急上線的Bard ,卻在首次亮相就出現錯誤,一夜讓Google蒸發了1,000億美元市值。
在過去的一年裡,基於大模型的聊天機器人單月訪問量已經超過20億,其中ChatGPT遙遙領先,Google Bard雖然排在第二,但和幾個競品一起歸為「其他」更為合適。
因此,Gemini早已被寄予了追趕ChatGPT的厚望,無論成敗,它就是Google過去對AI大模型孤注一擲的成果。
能看、能說、能推理
Gemini 1.0共有中杯、大杯、超大杯三種不同規格。
- Gemini Nano──最高效的設備任務模型
- Gemini Pro──適用於廣泛的任務擴展的最佳模型
- Gemini Ultra──最大且最能勝任高度複雜任務的模型

(Source:影片截圖)
暫且拋開繁雜的參數訊息,先來用幾個案例讓你全面了解Gemini的能力。
當你隨手畫個鴨子,從曲線到鴨子成型,Gemini都可以精準辨識。給鴨子畫條波浪線,它能理解你的言下之意,精準地指出鴨子在水中游泳的場景答案。同時它也能人性化地模仿鴨子的叫聲,即使是用流利的普通話說出鴨子的叫法也不在話下。

閒著無聊,也可以和Gemini玩個遊戲,你的手指指向哪個區域,Gemini就能說出那個國家及其代表性的事物。
三仙歸洞,猜猜紙球在哪個杯子下面,手速再快,也躲不過Gemini的「眼睛」。

拿到毛線卻毫無頭緒,別著急,Gemini聰明的大腦在看到紗線的那一刻,就已經安排好成品,你只需要「照貓畫虎」就好了。

辨識影像也只是Gemini的基礎水準,看到樂器,Gemini還能產生符合環境氛圍的音樂。

邏輯和謎題解決、影像序列分析、魔術技巧解釋、記憶和邏輯,這些能力Gemini樣樣都有,樣樣精通。Google也發布了文字展示版本,如果你不想看影片,可以到這裡查看。
或許是這支影片過於震撼,部分網友質疑Google這個影片有「造假」的可能性,不過Gemini很快就會在Google AI Studio向大眾開放,屆時便能一辯真假。
多模態Gemini vs. GPT-4
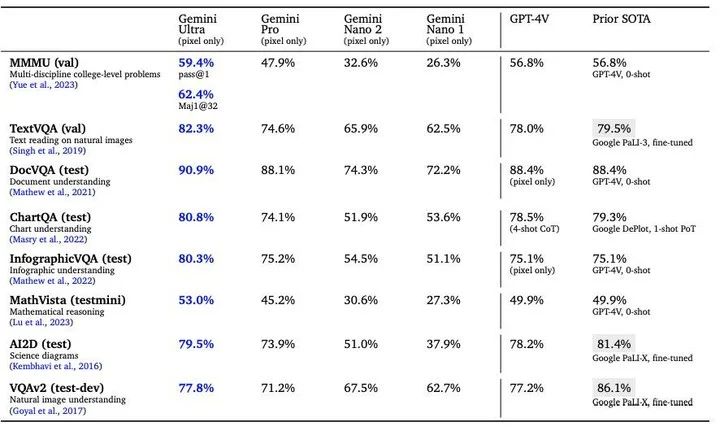
根據Google官方顯示,從自然圖像、音訊和視訊理解到數學推理,Gemini Ultra的性能在32個廣泛使用的大型語言模型(LLM)研究和開發的學術基準測試中,超過了30個當前最先進的結果。
從Google放出的測試結果來看,在文本、常規推理、數學、程式碼等領域,Gemini的表現幾乎是全方位碾壓OpenAI的GPT-4。

(Source:Google)
MMLU(大規模多任務語言理解)是測試AI模型知識和解決問題能力的最受歡迎方式之一。Gemini Ultra在該測試中以90.0%的準確率成為首個超越人類專家的模型,做為對比,GPT-4只有86.4%的準確率。
新的MMMU基準測試包含了跨不同領域的多模態任務,對多模態大模型的檢驗程度更高,但Gemini Ultra同樣取得了59.4%的高分。
Google CEO Sundar Picha在接受《麻省理工學院技術評論》的採訪時表示,Gemini之所以令人矚目,其中一個重要原因是它從根本上是一個多模態模型,就像人一樣,它不僅從文本中學習,也能透過視訊、音訊和程式碼進行學習。
多模態特性是Gemini花時間打磨的原生特性,Gemini 1.0能同時辨識和理解文字、影像、音訊等多種訊息,理解訊息能力更強,在回答與複雜主題相關的問題也能游刃有餘。在多模態SOTA的測試中,Gemini影像、視訊、音訊的多模態測試水準再次遙遙領先。
程式碼是檢驗大模型層級的重要指標之一,Gemini 1.0跨語言工作和推理複雜資訊的能力是它的強項,能夠理解諸如Python、Java、C++等高品質程式碼。兩年前,Google推出了AlphaCode,這是第一個在程式設計比賽中達到競爭水平的AI程式碼產生系統。
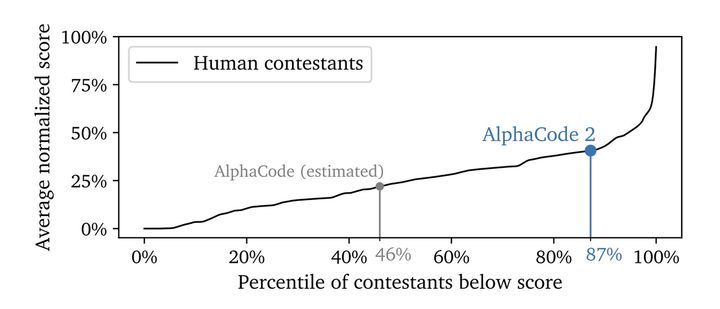
現在,AlphaCode推出了第二代,這是一個由Gemini微調的競爭性編碼模型,與原始AlphaCode在相同的平台上較量時,AlphaCode-2在人類競爭對手中的得分為87%,而此前AlphaCode的得分只有46%(點此看AlphaCode-2技術報告)。
在技術報告中,Google DeepMind(AlphaCode 2出品人)分享了大量關於推理時搜尋、過濾和重新排名系統的細節。NVIDIA資深科學家Jim Fan直誇這些最新成果堪稱Google的Q*(可以簡單理解為AI的大突破)。
AlphaCode-2 is also announced today, but seems to be buried in news. It’s a competitive coding model finetuned from Gemini. In the technical report, DeepMind shares a surprising amount of details on an inference-time search, filtering, and re-ranking system. This may be Google’s… pic.twitter.com/rGVSFsWHMO
— Jim Fan (@DrJimFan) December 6, 2023
thehiredai CEO Arman大膽地預測:「Gemini AI剛剛殺了ChatGPT!」
Google’s Gemini AI has just killed ChatGPT!
Gemini is now the strongest AI tool to ever exist as of 2023.
Here are 5 reasons why: pic.twitter.com/tusnRAJEDh
— Arman (@ArmanSpeaks) December 6, 2023
值得一提的是,Google也宣布推出迄今為止最強大、最有效率、最可擴展的TPU系統:Cloud TPU v5p。

▲ Cloud TPU v5p。(Source:Google)
Gemini 1.0的訓練正是在Google內部設計的Tensor處理單元(TPUs)v4和v5e的AI最佳化基礎設施上進行的。
Google Cloud CEO Thomas Kurian對於自家產品,毫不吝嗇地誇讚:「Cloud TPU v5p是我們迄今為止功能最強大、可擴展性最強的TPU加速器,其訓練模式的速度比其前代產品快2.8倍。」
Our most powerful and scalable TPU accelerator to date, Cloud TPU v5p can train models 2.8X faster than its predecessor.
— Thomas Kurian (@ThomasOrTK) December 6, 2023
手機大模型的新玩家
手機是新科技破圈的重要媒介,Gemini想要大規模走進大眾社會,Pixel 8一定是其不二之選。
Pixel 8 Pro做為第一款內建人工智慧的手機,已經在高新技術民用化的道路上建立了良好的口碑,從已經上手Pixel 8 Pro的用戶反饋看,Google把AI和手機終端應用結合得相當不錯。
Google也宣布,Gemini Nano大模型將在Pixel 8 Pro上正式運行。消息一出,PassionateGenius CTO Morimoto已經迫不及待想要體驗在Pixel 8上跑大模型了。做為首款專為Gemini Nano設計的智慧型手機,Pixel 8 Pro有兩項專屬的拓展功能將在後續的更新中加入:「記錄器摘要」和「Gboard智慧回應」。
即使沒有網路連接,記錄器也可以獲得手機對話錄音、採訪、演示等內容的摘要,強大的終端硬體是支撐這個功能的基礎,而最佳化的側端演算法讓「斷網不斷線」成為可能。
![]()
(Source:Google,下同)
智慧回覆功能很像自動回覆,但和傳統的固定內容相比,Gemini Nano可以辨識來信的內容,根據不同的語句生成對應的回應,語言也會更加自然親切,有種明星的營運團隊在社群平台回覆粉絲的即視感。
![]()
這兩個功能目前只支援英文辨識,非英語國家用戶還需要再靜候一段時間。
而在生產力方面的最佳化,Pixel終於趕上了基本水準。
類似的照片和影片的AI編輯功能在新機首發時,就成了Google新機的代名詞,現在的AI編輯最佳化,可以讓手機再加一件「專業編輯器」的新裝。
全新清潔功能可幫助去除掃描文件中的污跡和摺痕。現在只需在相簿裡滑動幾下,即可消除圖片中的污漬。
![]()
透過Google Tensor G3的強大功能,Pixel 8 Pro上的視訊增強模型,可在雲端調整顏色、照明、穩定性和顆粒度。從官方展示的對比來看,影片被加了一層「鮮明」濾鏡,顏色更飽滿,明暗對比度更高,特別是在夜晚暗光環境中,這種AI優化的效果會更明顯。

相較影片的編輯,影像美化應該是更多人的期待,特別是在拍動態物體的時候,模糊的畫面總會讓你在事後翻閱時留下一些遺憾,升級的AI編輯可以將Google照片中的模糊全部消除。以後記錄自家寵物的高光時刻,不用擔心相機沒對焦了。
此外,Google將多重裝置之間的連動也升級了。Pixel Watch能夠成為手機解鎖的另一種方式,也能幫你忽略不需要的來電,或接聽電話之前確認對象以及通話原因。
![]()
Google手機的用戶,可以試著檢驗這些新功能,會不會成為你購買或繼續使用Google的推手。
從今天開始,透過全新升級的Gemini Pro版本,Bard將實現更高階的推理、規劃、理解等功能。它將在超過170個國家和地區提供英文版本。
在接受《麻省理工學院技術評論》的採訪時,Sundar Pichai還說到:「Gemini Pro在基準測試中的表現非常出色,當整合到Bard時,我可以親身感受到它的優勢,我們一直在對它進行測試,所有類別任務的好評率都有顯著的提升,因此,我們將其稱為迄今為止最大的升級之一。」
在接下來的幾個月裡,Gemini還會陸續推出Google旗下更多的產品和服務,例如搜尋、廣告、Chrome和Duet AI等。
從12月13日開始,開發者和企業客戶可以透過Google AI Studio或Google Cloud Vertex AI中的Gemini API存取Gemini Pro。
目前,Gemini Ultra已經在內測中,並打算明年初推給開發者和企業用戶,明年初,Google還將推出Bard Advanced,讓更多的普通用戶用上最強的Gemini Ultra。
Google CEO Sundar Pichai在發布Gemini時說到:
每一次科技轉變都是推動科學發現、加速人類進步和改善生活的機會。
我相信我們現在看到的與AI有關的轉變將是我們一生中最深遠的,遠大於先前的行動裝置或網路的轉變。
想要實現AGI(通用人工智慧),就需要AI做到像人類一樣從容地解決不同領域、不同模式的複雜任務,在這個過程中,除了基本計算、推理等基礎能力,相對應的文字、影像、影片等多模態能力也要跟上。
DeepMind曾提出AGI的評估和分類的框架,前兩個階段分別是:
AGI-0:基本的人工智慧,能夠在特定的領域和任務上表現出智慧,如圖像辨識、自然語言處理等,但是不能跨領域和跨模態地進行學習和推理,也不能與人類和其他AI進行有效和自然的溝通和協作,也不能感知和表達情感和價值。
AGI-1:初級的通用人工智慧,能夠在多個領域和任務上表現出智慧,如問答、摘要、翻譯、對話等,能夠跨領域和跨模態地進行學習和推理,能夠與人類和其他AI進行基本的溝通和協作,能夠感知和表達簡單的情感和價值。
Gemini的展示,充分展現了它對各個模態互動的深刻理解,能看、能說、能推理、能夠感知和表達簡單的情感和價值,也讓我們看到了AGI-1的潛在可能性。





