




隨著大型語言模型(LLM)越來越普及,背後的 AI 技術也越來越成熟。過去,晶片的焦點在於模型訓練(Pre-Training),需要強大的運算力來「教導」AI。但現在,AI 的重心逐漸轉向「推理」(Inference,也就是模型實際應用、回答問題或生成內容的階段)。
Inference 需求的大幅提升,讓積極推出 Inference 應用 ASIC 的 CSP 動態備受關注,而過往稱霸模型訓練的 Nvidia 也沒忽略這個趨勢的轉變,推出了 Nvidia Rubin CPX 應戰。
拆解 Inference 流程
Inference 可以分為預填 (Prefill)、解碼 (Decode) 二階段。目前,市面上的 LLM 多是基於 Transformer 模型所構建,此模型又由多層相同結構的模組堆疊而成,每一層都包含自注意力機制 (Self-Attention,SA) 與前饋神經網路 (Feedforward Neural Network,FFN)。
在 Inference 應用中,每層模組中的 Self-Attention 模組會先考慮所有 input 生成 Query (Q)(依據input提出的查詢)、Key (K)(過去生成的所有舊 token)、Value (V)(依據 QK 相關性所提取的舊 token) 三種向量構成的矩陣,進行縮放點積注意力 (Scaled Dot-Product Attention,SDPA) 處理後,最終向量再通過 FFN 生成下一層 input。
而 Key-Value(KV) Cache 即為其中使用的一種重要技術,透過在特定的記憶體空間內存放每次計算出的 K、V 向量,就不需要在每次生成 token 時重複計算過去所有的舊 token,避免昂貴的重複計算,並提升計算效率。
Prefill 即為預先一次性計算完所有 K、V 向量並存入 KV Cache 的過程,Decode 則為使用每一個新token 和 KV Cache 中所有 K 向量匹配並生成下一個 token 的過程。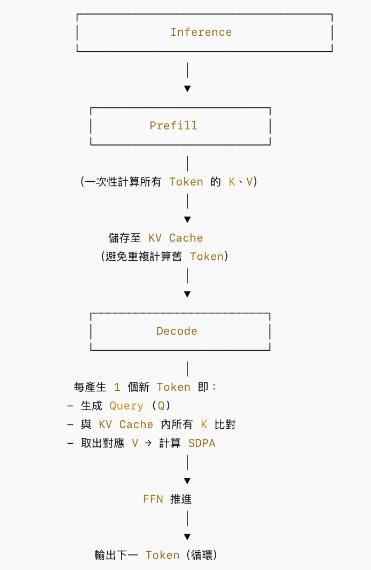
Inference 對算力和儲存帶來需求的改變
由此可知,Prefill、Decode 二階段分別對晶片的要求大不相同。Prefill 階段的目標是最小化第一個 token 的輸出時間 (Time-To-First-Token,TTFT),需要可以進行高度並行的大矩陣計算,然而對大記憶體容量、低延遲的要求並不如 Decode 嚴格;Decode 階段的目標則是最小化每個 token 的平均生成時間 (Time-Per-Output-Token,TPOT),需要高頻寬、低延遲的記憶體。
目前市場上的AI晶片(多數是GPU),通常採用「一體適用」的設計,也就是用同一顆晶片來跑完Prefill和Decode兩個階段。
這種做法造成了資源浪費:
- 在 Prefill 階段,晶片運算力全開,但記憶體(頻寬)利用率不足。
- 在 Decode 階段,記憶體需求爆增,但運算力卻有很多閒置。
因此,專用的 Prefill 和 Decode 硬體 (Specialized Prefill and Decode hardware,SPAD) 的概念應運而生,也就是針對 Prefill、Decode 二階段的需求設計專用的 AI 硬體,以提升 Inference 效率。
Prefill 晶片應使用更大型的脈動陣列 (Systolic Array),但記憶體僅需暫存 KV Cache,因此可以搭配更具成本效益的 GDDR 或 LPDDR 記憶體;Decode 晶片則應降低算力,並搭配高容量、高頻寬的記憶體,如 HBM、HBF。二者之間再使用 Scale-Out 高速互連來傳遞 KV Cache。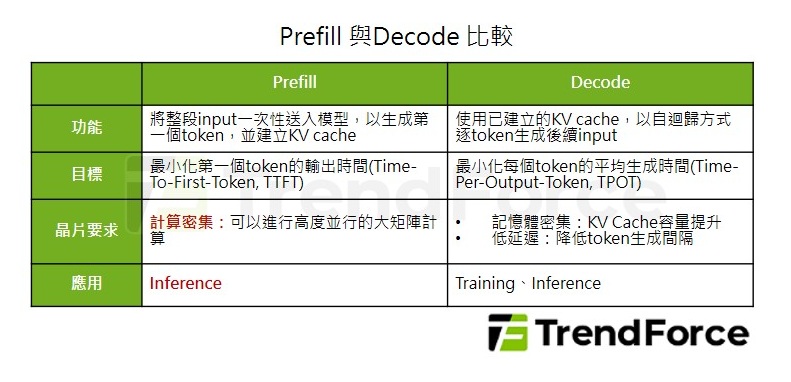
GPU 陣營已積極針對 Prefill 推出專用晶片
為因應日益增長的 Inference 需求,各家廠商於 2025 年陸續推出針對 Inference Prefill 階段所設計的晶片。目前已公布的 Prefill 晶片主要有 Nvidia Rubin CPX、華為 Ascend 950PR、Intel Crescent Island,及 Qualcomm AI200。除了華為 Ascend 950PR 屬於 ASIC 以外,目前推出的 Prefill 晶片皆為 GPU,各大 CSP 仍未推出 Prefill 專用 ASIC。
Google 與 Meta 為 ASIC 陣營耕耘 Inference 最積極廠商
至於在 ASIC 方面,過去各大 CSP 積極開發自研 ASIC,考量的是成本效益與高能效比。自研 ASIC 儘管前期開發成本高,但大規模量產後單顆成本可降至約單顆 GPU 成本的三分之一。此外,CSP 了解自身的模型與需求,可以針對特定應用設計專用 ASIC,在特定領域的能效比優於通用 GPU。
目前積極推出 Inference 應用 ASIC 的 CSP 主要有 Google 的 TPU v7 (Ironwood/Ghostfish),已於今年第三季量產、Meta 的 MTIA 2,同樣已於今年第三季量產。
然而,除了中國以外,各大 CSP 目前皆未推出分別為 Prefill、Decode 專用的 ASIC。而在市場逐漸從 Training 轉向 Inference 應用的背景下,Prefill、Decode 硬體分離的架構愈趨重要,與CSP保持低成本、高能效比的研發路線相符,各大 CSP 未來可能跟進開發 Prefill、Decode 專用 ASIC,預期未來 AI 晶片規格主要在記憶體、SerDes 方面分化。
(首圖來源:科技新報)





