



隨著人工智慧(AI)模型的創新速度遠超基礎設施的演進,記憶體架構已成為加速 AI 部署的關鍵槓桿。美光(Micron)與輝達(NVIDIA)合作開發的 SOCAMM(System-On-Chip Attached Memory Module)正從過往的專有技術轉型為 JEDEC 行業標準 SOCAMM2,成為解決「記憶體牆」挑戰的核心方案。
SOCAMM2 採用水平配置,緊鄰主機 CPU,並使用堆疊式 LPDDR 記憶體設計。這種設計不僅提供了超越高頻寬記憶體(HBM)容量的高頻寬解決方案,更優化了散熱路徑,使冷卻板能同時覆蓋 CPU 與記憶體模組,簡化了系統複雜性。此外,模組化的設計讓 SOCAMM2 具備可更換與升級的特性,能靈活應對快速變化的 AI 工作負載。
在技術規格上,美光展示了強大的創新能力。其最新的 256GB SOCAMM2 模組在不到一年的時間內將容量翻倍(從 128GB 增至 256GB),並採用領先的 1-Gamma 製程與 32Gb LPDDR5X 晶粒。這使得每顆 CPU 的記憶體配置潛力從 1TB 提升至 2TB,為 AI 加速器提供了更充裕的數據儲存空間。與傳統的 RDIMM 相比,SOCAMM2 的功耗降低了 66%。此外,美光的新模組容量比 SK 海力士(SK Hynix)發布的競爭產品高出 33%。
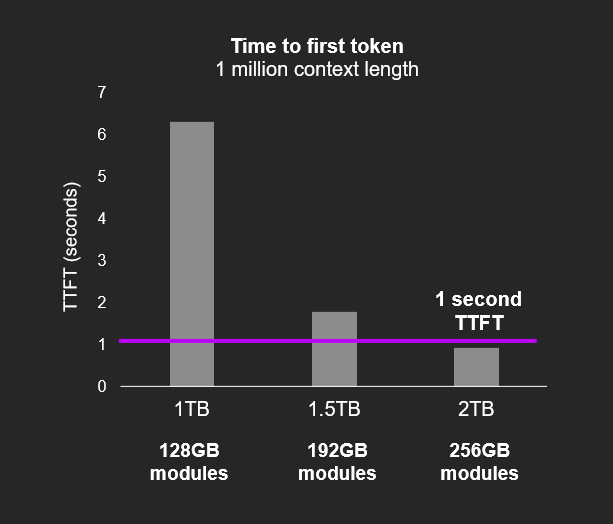
效能表現方面,根據美光提供的數據,SOCAMM2 為通用伺服器工作負載帶來 4 倍的效能提升,在 AI 工作負載中更可達 6 倍以上。該技術特別適用於 KV 快取(Key-Value Cache)等高頻寬需求應用,能有效儲存先前查詢的結果,減少重複運算的需求。
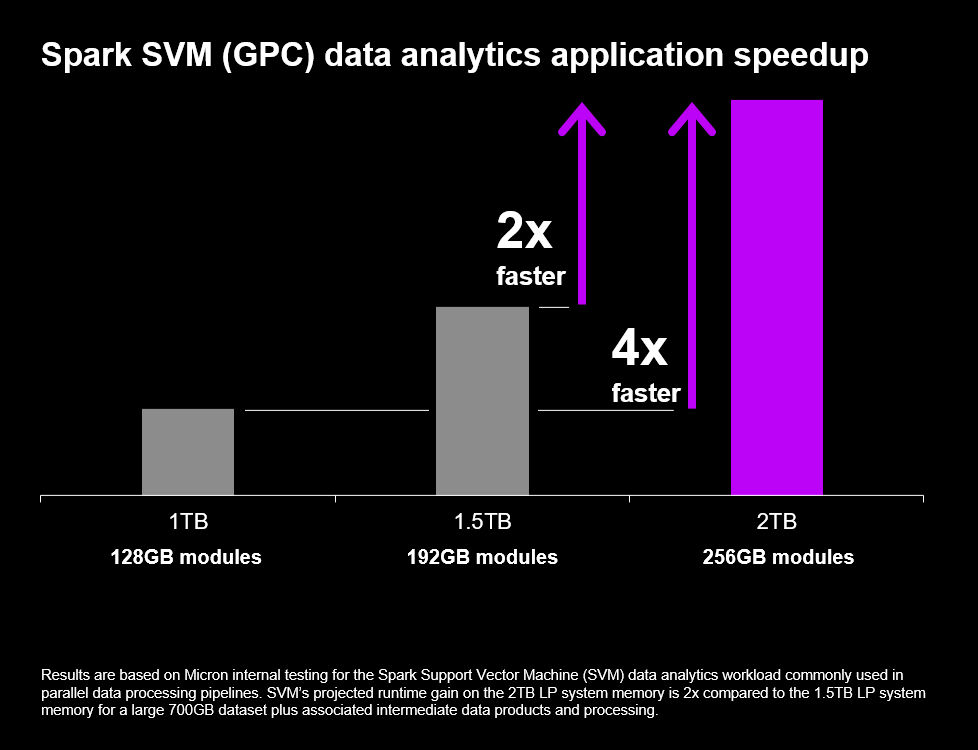
根據 Tirias Research 的預測,SOCAMM2 結合改進的 AI 快取管理核心,可使 ChatGPT、Gemini 及 Claude 等高參數基礎模型的 Token 生成成本降低 3 至 5 倍。隨著全球對 LLM Token 需求預計增長 115 倍,SOCAMM2 將有助於緩解預計到本年代末高達 1.2 兆美元的 AI 推論伺服器資本支出壓力。
目前,SOCAMM2 已獲得三星(Samsung)與 SK 海力士等主要供應商的採納,預計將廣泛應用於即將推出的「Rubin」世代 AI 伺服器中。除了 AI 領域,高效能運算(HPC)廠商也對其高頻寬特性展現濃厚興趣,促使美光進一步擴展產品線以支援較低容量的需求。這場由美光與 NVIDIA 領銜的記憶體架構變革,正重新定義 AI 伺服器的運算密度與經濟效益。
- SOCAMM2 Is The Memory Standard AI Is Looking For
- Micron Technology, Inc. Sets New Benchmark with the World’s First High-Capacity 256Gb LPDRAM SOCAMM2 for Data Center Infrastructure
(圖片來源:美光)





