



外媒報導,Google 研究團隊於日前正式發表了一項名為「TurboQuant」的全新免訓練(training-free)壓縮演算法。這項革命性的技術能夠將大型語言模型的鍵值快取(KV caches)大幅壓縮至僅剩 3 位元(3 bits),且過程完全不會造成模型準確度的損失。
根據在輝達(Nvidia)H100 GPU 上進行的基準測試結果顯示,採用 4 位元版本的 TurboQuant 在計算注意力對數(attention logits)時,相較於未經量化的 32 位元金鑰,其效能提升了高達 8 倍,同時將 KV 快取記憶體的需求量降低了至少 6 倍。這項突破無疑為當前記憶體資源消耗龐大的 AI 運算領域帶來了顯著的硬體最佳化解方。
報導指出,隨著大型語言模型的應用日益廣泛,模型需要處理的上下文長度不斷擴張,記憶體瓶頸成為了產業界亟待解決的難題。在 AI 模型生成文字的過程中,KV 快取扮演著至關重要的角色。它的主要功能是儲存先前已經計算過的注意力數據(attention data),使得大型語言模型在每一個 token 的生成步驟中,都不需要重新進行繁複的計算。
然而,隨著上下文長度越來越大,這些 KV 快取佔用的記憶體空間也呈現爆炸性的成長,逐漸成為系統主要的記憶體瓶頸所在。為了解決這個問題,業界過去多半採用傳統的向量量化(vector quantization)方法來縮減快取體積。雖然,傳統量化能減少整體大小,但系統必須額外儲存量化常數(quantization constants),這會導致每個數值都產生幾個位元的記憶體消耗。當面對超大型的上下文長度時,這些微小的額外開銷會不斷複合累加,最終嚴重侵蝕掉量化所帶來的記憶體節省效益。
為了徹底消除傳統量化帶來的額外開銷,Google 團隊透過創新的「兩階段處理流程」打造出 TurboQuant 演算法。第一階段導入了一種被稱為 PolarQuant 的技術。 PolarQuant 的核心運作原理,是將數據向量從傳統的 Cartesian coordinates,轉換為 polar coordinates。透過這種轉換,每個向量被巧妙地分離成代表大小的radius,以及代表方向的 angles。由於在極座標下,angles 的分布具有高度的可預測性且非常集中,PolarQuant 因此能夠直接省略傳統量化器所必須執行的、極度消耗運算資源的每區塊正規化(per-block normalization)步驟。這項設計使得模型能夠在達成高品質壓縮的同時,實現零量化常數儲存消耗的驚人成果。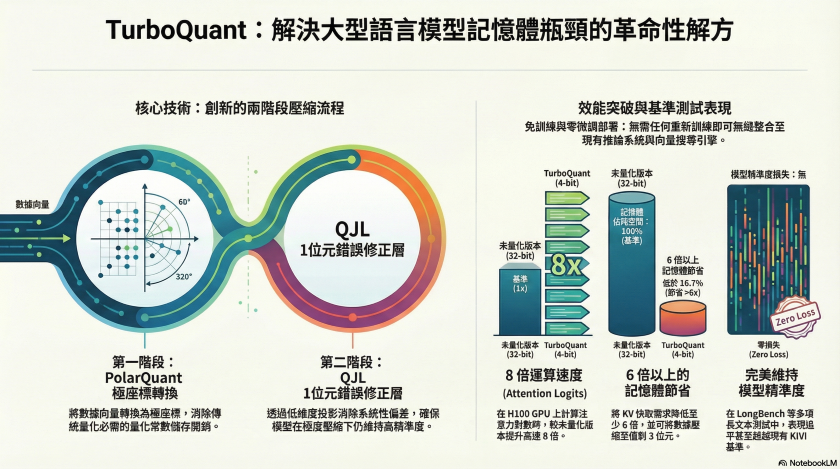
第二階段則是一層 1 位元(1-bit)的錯誤修正層(error correction layer)。此階段採用了名為 Quantized Johnson-Lindenstrauss ( QJL)的演算法。QJL 演算法會將殘餘的量化誤差投影到一個較低維度的空間之中,接著將每個數值進一步縮減至僅剩一個單一符號位元(single sign bit)。此數學轉換幾乎沒有增加任何額外的運算成本,同時還能有效消除在計算注意力分數時所產生的系統性偏差,確保模型的高精準度。
為了驗證實際效能,Google 團隊使用了 Gemma 與 Mistral 等開源模型,在多個業界標準的長文本基準測試中進行全面評估,涵蓋了 LongBench、Needle In A Haystack、ZeroSCROLLS、RULER 以及 L-Eval 等項目。最終,測試結果令人驚豔。在其中在 LongBench 的資訊檢索任務中,TurboQuant 在將 KV 記憶體壓縮至少 6 倍的嚴苛條件下,依然取得了完美的下游分數。而在包含問答、程式碼生成以及文章摘要等多元任務的 LongBench 測試中,TurboQuant 的表現不僅追平,甚至在所有任務上都超越了 KIVI 基準線。
此外,TurboQuant 在向量搜尋領域也展現了強大的實力。在 GloVe 資料集的評測中,即使面對如 Product Quantization 和 RabbiQ 等依賴龐大碼本與特定資料集微調的現有基準技術,TurboQuant 依舊取得了最高的 1@k 召回率(recall ratios)。Google 官方特別強調,TurboQuant 最具商業價值的優勢在於它完全不需要任何訓練或微調(no training or fine-tuning),且在執行時期的資源消耗微乎其微。這些優異特性使得 TurboQuant 能夠非常輕易且無縫地部署於現有的生產級推論系統以及大規模的向量搜尋系統之中。
該技術的詳細研究論文由 Google 研究科學家 Amir Zandieh 與副總裁 Vahab Mirrokni 共同撰寫。相關報導指出,該研究團隊預計將於下個月舉辦的 2026 年國際學習表徵會議(ICLR 2026)上,正式發表這項有望大幅降低 AI 運算門檻的重大研究成果。
(首圖來源:AI 生成)





