



Google 自行研發、專為 AI 量身打造的加速器第八代 TPU(Tensor Processing Unit)──TPU 8i 與 TPU 8t,藉 Google Cloud Next 2026 大會首度亮相,Google Cloud 表示將在今年稍晚正式提供給客戶。
TPU 8t:訓練效能引擎
TPU 8t 專為大規模預訓練以及嵌入密集型工作負載進行最佳化,運用經過實證的 3D torus 拓撲,單一 superpod 內可達到 9,600 顆晶片的規模;TPU 8t 的設計還能在數百個 superpod 之間達到最大吞吐量,確保訓練進度如期推進。Google Cloud 進一步解析 TPU 8t 對比前幾代的重要進展:
展現 SparseCore 優勢
TPU 8t 的核心為 SparseCore,專為處理嵌入式查找這類不規則的記憶體存取模式而設計。當 MXU(Matrix Multiply Unit)負責執行矩陣運算時,SparseCore 會承接與資料相依的 all-gather 運算以及其他集體運算,藉此避免這類運算在通用型晶片經常出現的零操作瓶頸。
VPU / MXU 重疊運作與均衡擴展
TPU 8t 的設計目的使已配置的 FLOPs 使用率達到最大化。透過實作更均衡的 VPU(Vector Processing Unit)擴展機制,這個架構將外顯的向量運算時間降至最低。這讓量化、softmax 及 layernorm 等運算能與 MXU 的矩陣乘法更有效地重疊進行,協助晶片保持忙碌,而不會因為等待連續執行的向量任務而閒置。
原生 FP4
TPU 8t 導入原生 FP4(4-bit floating point,4 位元浮點數),以克服記憶體頻寬的瓶頸,將 MXU 吞吐量加倍,即使在較低精度的量化條件下,也能為大型模型維持準確度。透過減少每個參數所需的位元數,這個平台將耗能的資料搬移降到最低,讓更大的模型層能容納在本地硬體緩衝區內,以達成尖峰運算使用率。
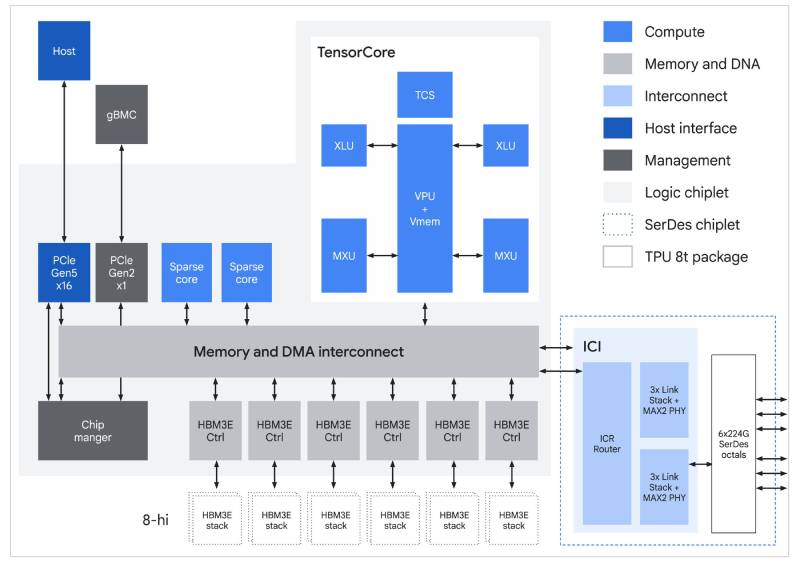
▲ TPU 8t ASIC 架構。
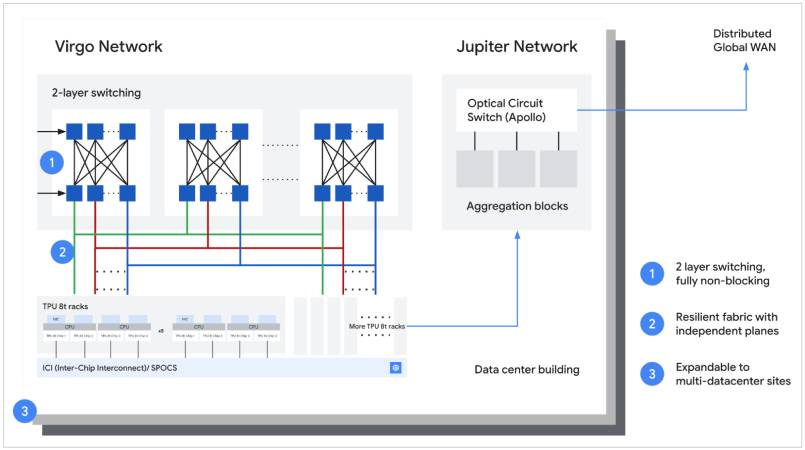
Virgo Network
為支援 TPU 8t 的龐大資料需求,Google Cloud 推出 Virgo Network。這個新的網路架構讓 TPU 8t 訓練在 DCN(data center network,資料中心網路)頻寬最高提升 4 倍。Virgo Network 是一個專為現代 AI 工作負載的極端需求而設計的 Scale-Out 結構,建構在高基數交換機之上,並採用扁平、雙層、無阻塞的拓撲架構。相較於傳統的 DCN,這種架構透過減少網路層級顯著降低延遲,它採用多平面設計,並搭配獨立的控制網域來連結 TPU 8t,TPU 8t 的機架也透過 Jupiter 南北向網路結構連接,以存取運算與儲存服務。
相較於 Ironwood TPU,TPU 8t 在 ICI(inter-chip interconnect,晶片間互連)提供 2 倍的擴展頻寬,在 DCN 原始橫向擴展頻寬上更高達 4 倍,因此能大幅降低資料瓶頸。
為進一步加速模型開發,Google Cloud 將分散式訓練擴展到單一叢集外。運用 JAX 與 Pathways,現在能在單一訓練叢集擴展至超過 100 萬顆 TPU。Virgo Network 能將超過 13.4 萬顆 TPU 8t 連結在單一網路結構中,並提供高達每秒 47 Pbps 的無阻塞雙向頻寬。這個網路結構能以近乎線性的擴展表現,提供超過 160 萬 exaFLOPS 的運算能力。
更快速的儲存存取
Google Cloud 在 TPU 8t 導入 TPUDirect RDMA 與 TPU Direct Storage。TPU Direct RDMA 能讓 TPU 的記憶體(指 HBM)與網路介面卡之間直接進行資料傳輸,繞過主機 CPU 與 DRAM,這會降低延遲以及主機系統的瓶頸,提升 TPU 對 TPU 通訊的有效頻寬。同樣地,TPUDirect Storage 也能讓 TPU 與 10T Lustre 等高速託管儲存服務之間直接進行記憶體存取,將大規模資料傳輸的頻寬有效加倍。
透過將 Managed Lustre 10T 與 TPUDirect Storage 結合,把高達數百 PB 的資料集直接傳輸至晶片,TPU 8t 避免因資料吸收瓶頸所導致的訓練延遲。相較於以 Ironwood TPU 進行訓練,TPU 8t 提供快上 10 倍的儲存存取速度。
TPU 8i:推理引擎
TPU 8i 專為後訓練(post-training)與高併發推理所設計,搭載 Google Cloud 在晶片上最大的 SRAM(靜態隨機存取記憶體)、全新的 CAE(Collectives Acceleration Engine,集體加速引擎)、以及名為 Boardfly 的服務最佳化網路拓樸。
晶片上最大的 SRAM
相較於 Ironwood TPU,TPU 8i 晶片上的 SRAM 提升為 3 倍,將更大的 KV Cache 完全託管在矽晶上,大幅減少運算核心在長篇幅脈絡解碼時的閒置時間。
CAE 集體加速引擎
為了解決取樣瓶頸,TPU 8i 運用 CAE,能以近乎零延遲的方式整合各核心間的運算結果,專門加速 auto-regressive decoding 以及 CoT(Chain-of-Thought)處理過程中所需的簡化與同步步驟。每顆 TPU 8i 在核心晶粒上配有 2 個 Tensor Core,並在 chiplet 晶粒上配有 CAE,取代 Ironwood TPU 核心晶粒上的 4 個 SparseCore。透過整合專用的 CAE,TPU 8i 進一步將晶片上集體運算的延遲降低 5 倍,延遲越低代表等待時間越少,促成能夠同時執行數百萬個 Agent 所需的龐大吞吐量。
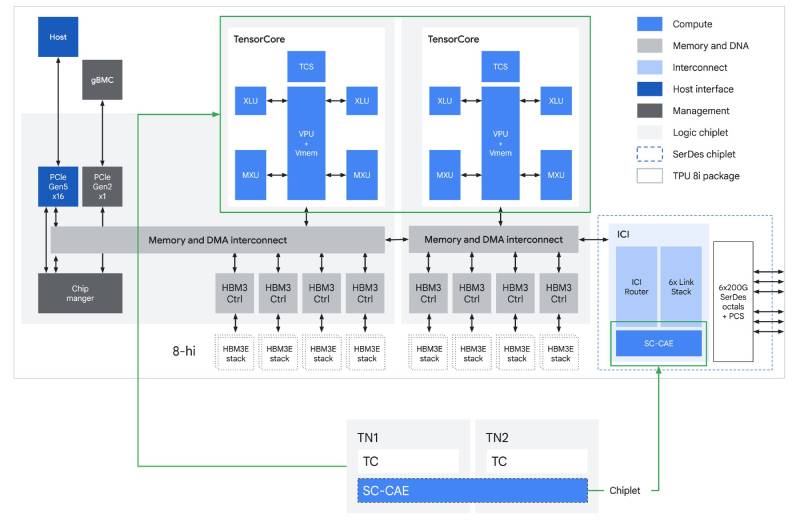
▲ TPU 8i ASIC 架構。
Boardfly ICI 拓撲架構
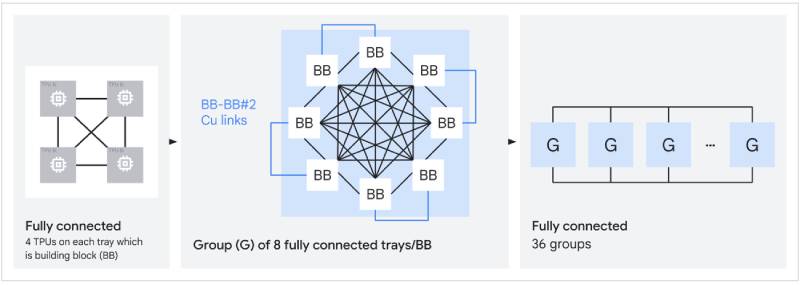
雖然 3D torus 可將數千顆晶片連接在一起協同運作,但大型網狀結構在晶片之間會產生較多跳轉次數,以及較高 all-to-all 延遲。針對 TPU 8i,Google Cloud 變更了晶片之間的連接方式,讓晶片在全連接板上互連,然後再將這些板聚合成群組,最多能將 1,152 顆這類晶片連接在一起,進而縮短網路直徑以及資料封包穿越整個系統所需的跳轉次數。大幅減少跳轉次數下,Boardfly 在延遲上能為通訊密集型工作負載帶來最高 50% 的改善。
綜合來看,在大規模訓練上,TPU 8t 相較於 Ironwood TPU 提供最高 2.7 倍的每美元效能提升,TPU 8i 相較於 Ironwood TPU 則提供最高 80% 的每美元效能提升,尤其是在大型 MoE 模型的低延遲目標方面。兩款晶片的每瓦效能皆有最高可達 2 倍的提升,對於以永續方式擴展下一世代 AI 的規模相當重要。
(圖片來源:Google Cloud Blog)





