



因應美國政府要求「有限預覽」分階段發布最新模型,OpenAI 繼 GPT-5.5 推出兩個月後,今日正式發布新一代模型「GPT-5.6」系列,並分別以太陽、地球和月亮命名,其中 Sol 是旗艦型號、Terra 是適合日常工作的平衡模型,而 Luna 則是主打快速與經濟實惠的模型。
OpenAI 表示,Terra 的性能媲美 GPT-5.5,但價格便宜一半,而 Luna 則以史無前例的超低成本帶來強勁的實力,至於 Sol 則搭載迄今為止最牢固的安全技術,並針對高風險活動、敏感網絡請求和濫用的保護措施,並花費數週尋找系統漏洞、進行壓力測試,提高其抵御現實世界攻擊的能力。
OpenAI 指出,目前計劃在未來幾週內逐步發表 GPT-5.6 Sol、Terra 和 Luna,因與美國政府持續溝通,因此首先將向一小部分值得信賴的合作夥伴開放有限預覽,隨後再進行更廣泛的發布,而在預覽期間,OpenAI 將繼續進行測試,並與合作夥伴密切協調,以推進更廣泛的可用性。
OpenAI 說明,目前並不認為美國政府審查流程應該成為長期的默認機制,因其會阻礙用戶、開發者、企業、網絡防禦者,以及迫切需要這些最佳工具的全球合作夥伴,而之所以採取這一短期步驟,主要是相信這是在未來幾週內走向更廣泛開放的最強路徑。
OpenAI 最新 GPT-5.6 三款模型能力
新命名系統中,數字 5.6 代表世代,而 Sol、Terra、Luna 則代表不同的強度層級,分別以「日月星辰」鎖定不同場景的能力階層模型,未來將各自獨立推進,期望讓用戶能在智能、速度與成本之間做出最完美的權衡:
GPT-5.6 Sol(太陽):家族中的終極旗艦模型,相較 GPT-5.5 有著跨越式的性能突破,專門為極其複雜的「自主代理工作(Agentic work)」而生。
GPT-5.6 Terra(地球):日常工作平衡型模型,其性能與前代 GPT-5.5 相當,但運行成本直接便宜一半,為企業高效日常應用的首選。
GPT-5.6 Luna(月亮):高產量、快速與經濟實惠的模型,提供強大基礎能力的同時,並將成本壓到最低,適合大規模重複性的高容量工作。
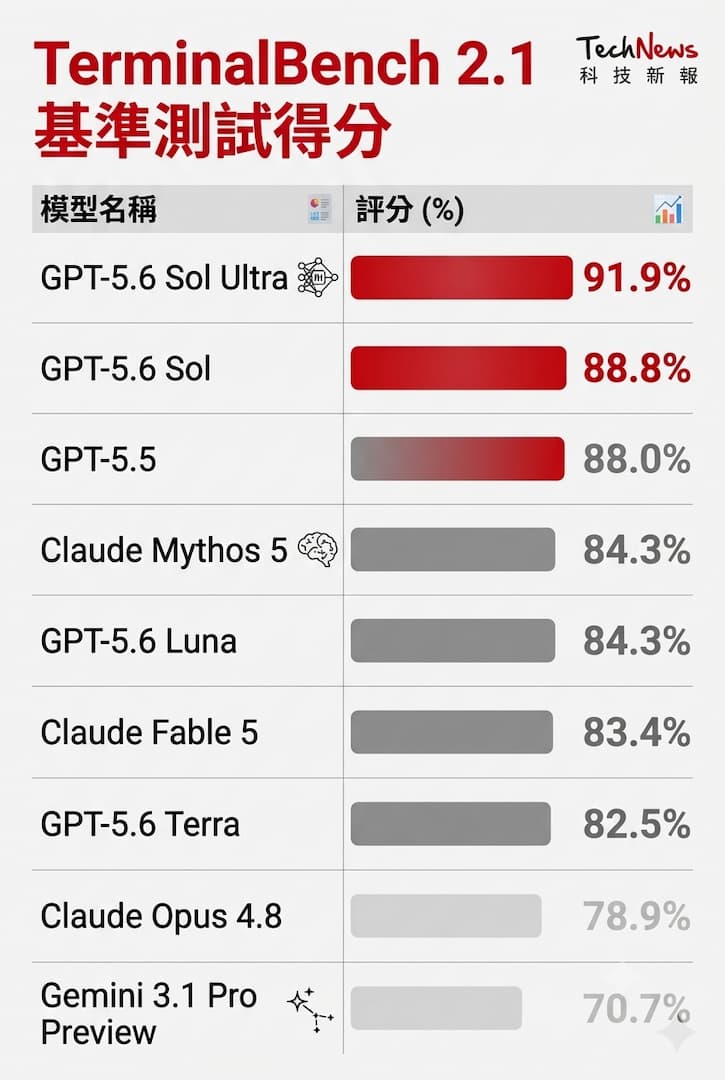
GPT-5.6 Sol 是 OpenAI 迄今為止最強大的模型,為了讓大家預覽其性能,OpenAI 分享一組評估結果,重點展示其在程式設計、生物學和網路安全方面,顯著提升的代理型能力(Agentic Capabilities),未來當模型廣泛可用時,OpenAI 將分享更全面的評估結果。
GPT-5.6 Sol 擁有史詩級推理速度
目前在 GPT-5.6 中,OpenAI 引入全新的 「最大推理強度(Max Reasoning Effort)」,得以讓 Sol 有充足的時間進行深度推理,並推出全新的「極致模式(Ultra Mode)」,通過呼叫「子代理(Subagents)」協同作業,超越單一子代理的極限,從而大幅加速複雜任務的完成。
GPT-5.6 Sol 在生物學工作流中表現出廣泛的提升,並在評估長週期基因組學和定量生物學分析的 GeneBench v1 方面,不僅取得比 GPT-5.5 更強的結果,而且消耗的 Token 更少,甚至在輸出 Token、延遲和成本的綜合前沿表現均超越前代。
網路安全方面,GPT-5.6 Sol 是 OpenAI 最強悍的模型,徹底改變長週期安全任務(包括漏洞研究與利用)的「性能-效率前沿」,而在 ExploitBench 方面,GPT-5.6 Sol 的表現與 Mythos Preview 相當,但僅消耗約 1/3 的輸出 Token。
至於 ExploitGym(由加州大學伯克利分校研究人員與 OpenAI 及其他前沿實驗室合作創建的基準測試)方面,隨著推理能力的提升,GPT-5.6 Sol、Terra 和 Luna 模型在網絡能力都展現出強勁的突破,更在 2 和 6 小時的限時任務中,其預期漏洞利用(Intended Exploits)的成功率均大幅提升。
GPT-5.6 主打史上最強分層安全防護堆疊
OpenAI 開發 GPT-5.6 Sol、Terra 和 Luna 時,匹配針對其各自能力的專屬安全防護配置,隨著模型變得更加強大,OpenAI 設計的防護措施不僅能承受現實世界的對抗性壓力,同時也能保障合法的安全工作順利開展,例如程式審計、漏洞研究、補丁開發、調試、安全教育和防禦性測試。
OpenAI 目標是讓違規的攻擊性活動變得更困難、更具不確定性且更容易被捕獲,同時不給這些有益的防禦用途帶來不必要的限制,根據 OpenAI 對模型和防護措施的評估,預計其將為合法的防禦性工作帶來巨大的紅利,同時能切實地約束被禁止的攻擊性使用。
面對堅決或靈活變通的濫用行為,單一的防護措施遠遠不夠,因此在整個 GPT-5.6 預覽版中,OpenAI 採用分層安全防護(Layered Safeguards),具體配置因模型而異,並針對現實世界的攻擊進行壓力測試。
- 模型內置防禦:訓練模型拒絕協助違規的網絡活動,即使惡意用戶試圖偽裝意圖或進行提示詞注入(Jailbreak)。
- 實時流量攔截:實時網絡和生物濫用分類器會在輸出生成時進行評估,而在高風險情況,若檢測到潛在違規,生成可能會暫停,並由更大的推理模型審查對話及其上下文,而若評估為違規,該輸出將在到達用戶前被攔截。
- 帳號級信號監測:被標記的活動會觸發對相關對話和風險信號的帳號級審查,並跳出單一對話的局限,有助於系統將持續的惡意行為與合法的「雙重用途(Dual-use)」安全工作區分,因為在這兩類性質截然不同的上下文中,可能會出現相同的技術概念。
預覽期間,用戶可能會遇到防護措施誤傷或拒絕某些請求的情況,部分請求可能會因為暫停接受額外審查而耗時更長,OpenAI 希望通過預覽版測試,瞭解防護措施在遏制濫用的同時,是否會讓合法用戶能夠高效、可靠地完成正常工作。
當攻擊者改變戰術時,防護措施必須保持有效,因此 OpenAI 投入較以往更多的智能與算力,並撥出超過 70 萬個 A100 等效 GPU 小時用於自動化紅隊測試(Automated Red-teaming),目的在尋找「通用越獄方法(Universal Jailbreaks)」,可在多種提示詞或上下文中生效的攻擊手段。
最新 GPT-5.6 三款模型定價一次看
OpenAI 最新 GPT-5.6 系列支持顯式緩存斷點和 30 分鐘的最低緩存壽命,對於 GPT-5.6 及後續模型,緩存寫入(Cache Writes)按未緩存輸入費率的 1.25x 計費,而緩存讀取(Cache Reads)繼續享受 90% 的折扣。
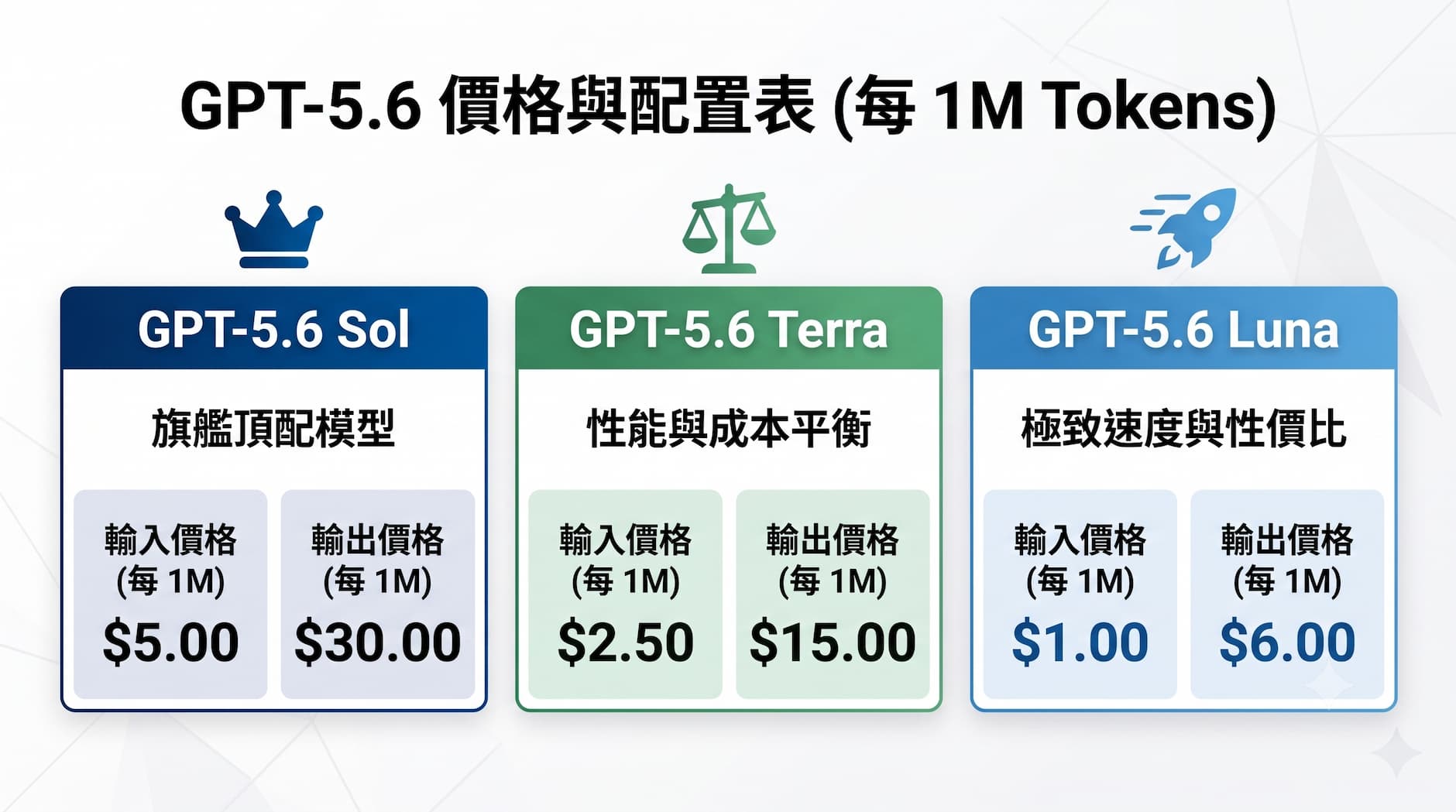
GPT-5.6 按每百萬 Token 計價,Sol 輸入 5 美元、輸出 30 美元;Terra 輸入 2.5 美元、輸出 15 美元;Luna 輸入 1 美元、輸出 6 美元,模型新增「max」與「ultra」推理選項,並將在 7 月推出運行在 Cerebras 上的 GPT-5.6 Sol,帶來高達每秒 750 個 Token 的史詩級推理速度。
(首圖來源:OpenAI)





