



人工智慧(AI)模型規模呈等比級數增長,算力基礎設施成為競爭核心。GPU(圖形處理器)一直是 AI 運算霸主,但 Google TPU(張量處理器)憑著專用架構,開始挑戰 GPU 地位。本文將分析兩者核心差異,並探討 TPU 是否有全面取代 GPU 的潛力。
TPU 與 GPU 最大差異:專才與通才
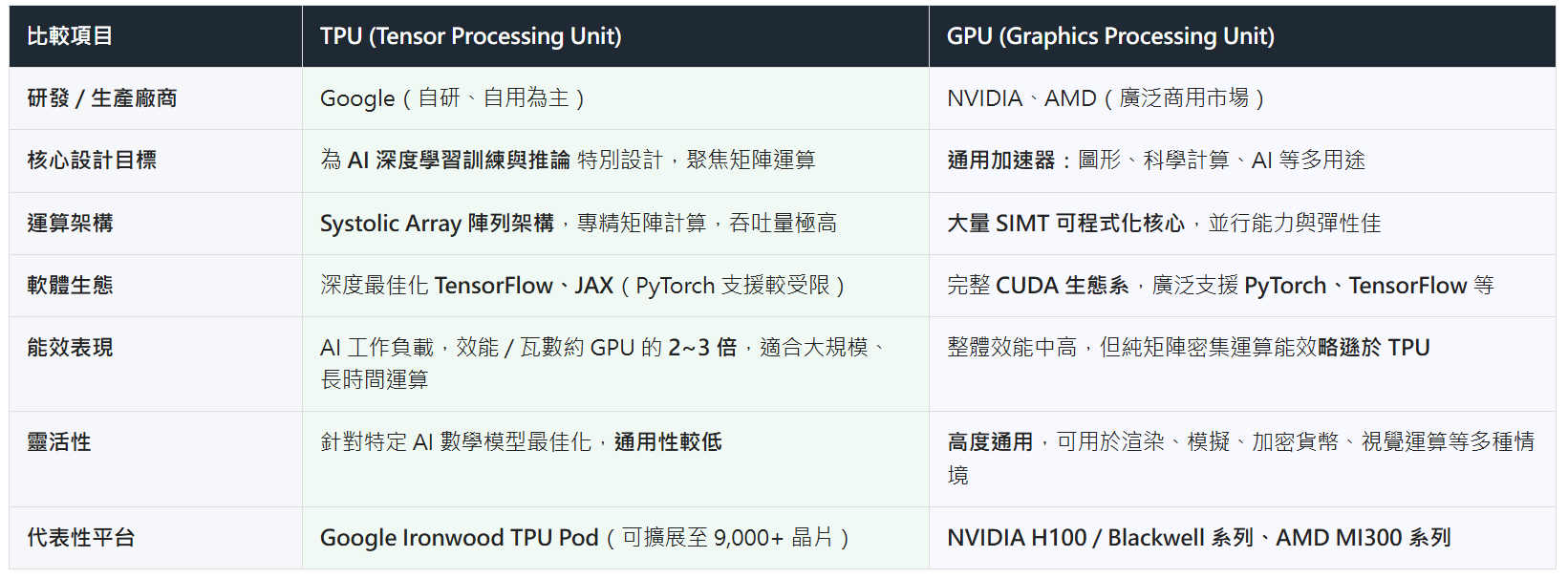
TPU 與 GPU 最本質差異在設計邏輯。
TPU(專才):Google TPU 是為了「矩陣運算」而生。深度學習核心(如神經網路訓練與推斷)高度依賴矩陣乘法,TPU 採獨特陣列架構(Systolic Array),讓數據在晶片內如波浪流動,大幅減少記憶體存取次數,使 TPU 處理特定 AI 任務時,展現極高效率。
GPU(通才):NVIDIA 和 AMD 生產的 GPU,最初專為圖形渲染設計,有大量可程式化核心,「並行運算」雖然也證明非常適合 AI,但架構必須保留處理圖形、物理模擬等通用任務邏輯,因此純粹 AI 矩陣運算還包括許多 AI 不必要的電路。
效能與成本:Ironwood 的啟示
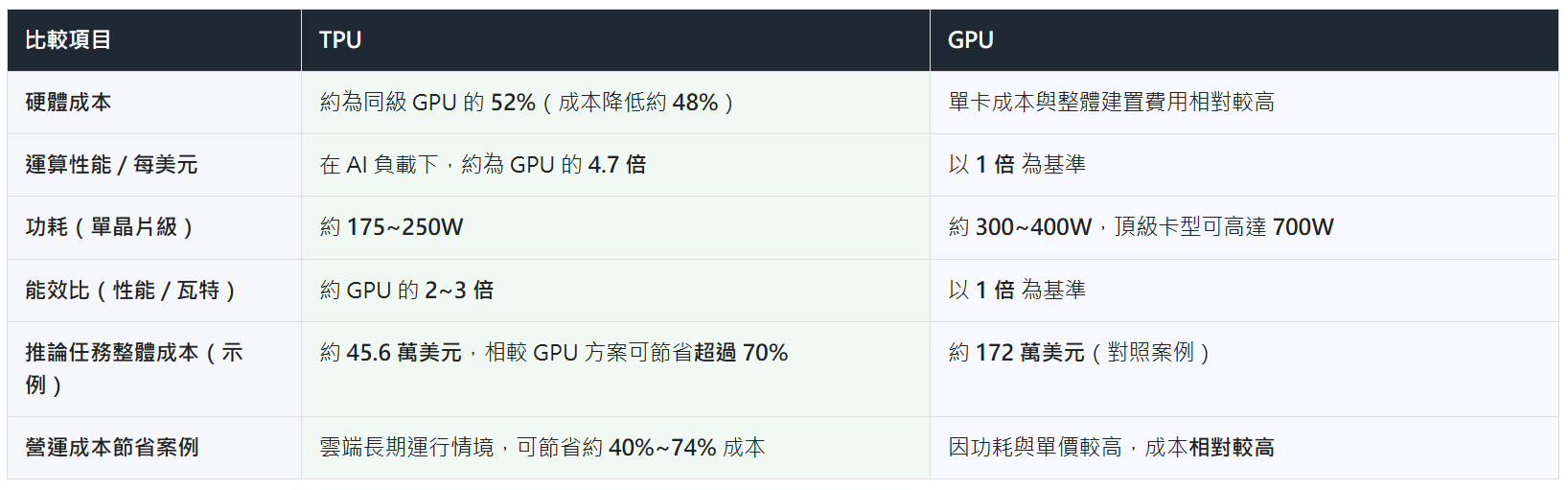
最新數據顯示,TPU 大規模運算時展現驚人能效優勢。以 Google 最新 Ironwood TPU 平台為例:
- 規模化:橫向擴展至 9,000 多顆晶片,提供逾 40 兆次算力(此指特定精確度的集群總算力)。
- 能效比:批量大型模型運算,每瓦效能(Performance per Watt)比 GPU 高兩至三倍。
這代表對 Meta 或 Google 等需 24 小時不間斷訓練超大模型的企業而言,採用 TPU 不僅速度快,長期電費和散熱成本也遠低於 GPU 集群。
關鍵:TPU 能否全面取代 GPU?
既然 TPU 在 AI 領域如此強大,是否會讓 GPU 走入歷史?答案是:目前不能,且短期內不會。原因主要有三點:
A. 生態系統鎖定(Lock-in)與靈活性
GPU 有極其成熟的軟體護城河(如 NVIDIA CUDA)。研究員可用 GPU 輕鬆切換不同框架(PyTorch、TensorFlow、Caffe 等),並能微調程式碼。反觀 TPU 高度依賴 TensorFlow 和 JAX,雖然近年 PyTorch 支援度有提升,但自由度仍低於 GPU。對需頻繁修改模型架構的學術研究者來說,GPU 更友善。
B. 通用性限制
並非所有的運算都是深度學習。科學模擬(如氣象預測、分子動力學)、工程運算、即時圖形渲染及現場除錯(On-site Debugging)等,依然需要 GPU 的通用架構。這些非矩陣運算任務 TPU 表現並不理想。
C. 取得門檻
GPU 是商品,企業可購買硬體自建伺服器;TPU 只能經 Google Cloud 租賃服務(雖然有 Edge TPU 等小型硬體,但訓練級晶片主要在雲端),都限制希望數據儲存在本端(On-premise)的企業採用 TPU。
為何只有 Google 可用 TPU 訓練 AI,其他企業不行?
儘管市場常有「TPU 僅適合推論」說法,但 Google 完全由 TPU 驅動的 Gemini 系列(從 1.0 到最新 3.0)證實具備頂級「訓練」力。但之所以成為 Google 難複製的獨門祕技,關鍵就在「經濟風險」與「垂直整合」。
而一般企業投資專用晶片(ASIC)是不合理的賭博。AI 演算法日新月異,訓練需要極高靈活性,一旦演算法改變,特定邏輯「硬化」的 ASIC 可能瞬間淪為昂貴的廢物(沉沒資產)。故 GPU 通用性是規避風險的唯一解決方案。
Google 能打破局面,是因建立封閉的「垂直整合生態」。Google 同時掌控 TPU 硬體與 Gemini 演算法,兩者同步演進、相互最佳化,形成「封閉生態鏈」,讓 Google 自家資料中心就能消化科技進步風險,其他巨頭如 Meta 不可能為了適應 Google 硬體架構犧牲自身靈活性。故用 TPU 大規模訓練,是只有具系統整合特權的玩家才能駕馭的戰略遊戲。
結論與展望
目前 AI 晶片市場呈「雙軌並行」趨勢。大型科技巨頭如 Google 與 Meta 訓練超大模型和大量推斷時,會優先採用 TPU 以降低成本和能耗;但研發階段、多樣化研究用途及非 AI 高速運算,GPU 依然不可或缺。
(本文由 Unwire HK 授權轉載;首圖來源:Google)





