



生成式 AI 背後的數學運算極為複雜,而且在記憶體頻寬與容量方面存在嚴重瓶頸,因此許多公司不斷祭出解決方案,期盼能解決 HBM 記憶體容量不足問題。
華為資料儲存產品副總裁躍峰指出,目前 AI 推理面臨三大問題:「推不動」(輸入內容太長超出處理範圍)、「推得慢」(回應速度太慢)、「推得貴」(運算成本太高)。
一般來說,記憶體伺服器會利用新型高速介面協議 CXL 延伸系統主記憶體,將更多外部記憶體接進來,使得數 TB 的 DDR 主記憶體匯集起來,形成速度相對快、容量較大的快取,並搭配頻寬極高、讀寫很快、但容量相對有限的 HBM,用於 AI 工作負載。

(Source:智東西)
根據華為提到的記憶體需求,主要分成 HBM、DRAM 與 SSD。其中,HBM 主要儲存實時記憶數據,容量約 10GB~百 GB 級,主要是極熱數據與即時對話;DRAM 做為短期記憶數據,容量約百 GB~TB 級,主要是熱數據與多輪對話;SSD 長期記憶數據與外部知識,容量約 TB 級到 PB 級,主要是熱溫數據,如歷史對話、RAG 知識庫、語料庫。
KV 快取是什麼?
在分享各家記憶體解決方案前,先了解「KV 快取」(KV Cache)是什麼?
在 AI 推理階段,會用到一種類似人腦的「注意力機制」,包括記住查詢中重要的部分(Key)以及上下文中重要部分(Value),以便回答提示。
如果每處理一個新的 token(新詞),模型必須針對先前處理過的所有 token 重新計算每個詞的重要性(Key 與 Value),以更新注意力權重。換言之,這好比學生每讀一個新句子都要重新回顧整篇文章,過程會相當耗時。
也因此,大語言模型(LLM)被加入一種稱為「KV 快取」(KV Cache)的機制,能將先前的重要資訊(Key 與 Value)儲存在記憶體中,免去每次重新計算的成本,從而將 token 處理與生成速度提升數個數量級。
如果以剛剛學生讀句子為例,KV 快取則類似筆記的概念,能將重要資訊記錄下來,當有新的 token 時,不需要再重新回顧,直接從筆記裡的資訊即可計算新的注意力權重。
做為 AI 模型的短期記憶,優勢在哪?
根據美光官網介紹,KV 快取是「AI 模型的短期記憶」,它能讓模型記住之前的問題中已經處理過的內容,如此一來,每次用戶重啟之前的討論或提出新問題時,就不必從頭開始重新計算。
有了 KV 快取,AI 能隨時了解用戶說過的、推理過的、提供過的內容,並為這些更長、更深入的討論提供更快、更縝密的答案。
KV 快取可帶來多種優勢,如近乎即時的回應能力、可提供長格式語境,另可透過在儲存裝置中持續儲存 KV 快取以重複使用,減少每次 LLM 查詢所需的運算量,進而更有效率地利用 GPU。此外,還可以提供眾多並行使用者的雲端服務,使每個使用者的每次查詢連線到正確的引用,並保持運行順暢。
然而,當上下文越長,需要的快取就越大,即使是中等規模的模型,KV 快取也會迅速膨脹到每個會話多 GB,因此針對 KV 快取的解決方案,成為各家關注的焦點之一。
針對 KV 快取需求大、記憶體不足,各家如何解?
由於美國出口限制,中國很難獲得 HBM 等關鍵資源,因此華為近期開發一款名為「統一快取管理器」(Unified Cache Manager,簡稱 UCM)的新軟體工具,無需使用 HBM 即可加速大型語言模型(LLM)的訓練與推理。
UCM 是做為一款以「KV 快取」(KV Cache)為中心的推理加速套件,融合多類型緩存加速演算法工具,分級管理推理過程中產生的 KV 快取記憶數據,擴大推理上下文視窗,實現高吞吐、低時延的推理體驗,並降低每Token 推理成本。
該軟體根據不同記憶體類型的延遲特性,以及各類 AI 應用的延遲需求,將 AI 資料分配在 HBM、標準 DRAM 與 SSD 之間。

(Source:智東西)
其中,UCM 分為三部分,最上層是透過「連接生態」(Connector),靈活對接業界的多樣引擎與多元算力,如華為昇騰、NVIDIA 等;再來透過中層「記憶管理」(Accelerator),透過 KV 快取動態多級管理,將演算法拆成適合快速運算的方式,使運算更高效;最後是「存儲協同」(Adapter),與專業共享儲存相結合的存取介面卡,以更高效的方式讀寫存儲資料,減少等待時間。
經大量測試驗證,UCM 可將首 token 時延最高降低 90%,系統吞吐最大提升 22 倍,實現 10 倍級上下文窗口擴展。
NVIDIA 支持新創 Enfabrica 推出「EMFASYS」
由 NVIDIA 支持的晶片新創公司 Enfabrica,近期正式推出一套「EMFASYS」軟體搭配「ACF-S」晶片的系統,目標也是在於降低資料中心高昂的記憶體成本。
外媒 The Next Platform 認為,若能加速用於 AI 推理核心的 KV 快取,有望成為 Enfabrica 與同業等待已久的「殺手級應用」。報導稱,目前記憶體是一大瓶頸,而擁有一個能以主機主記憶體速度運行、足以存放 KV 向量與embeddings 的超大共享記憶體池,正是讓推理運行更快、更便宜的方法之一。
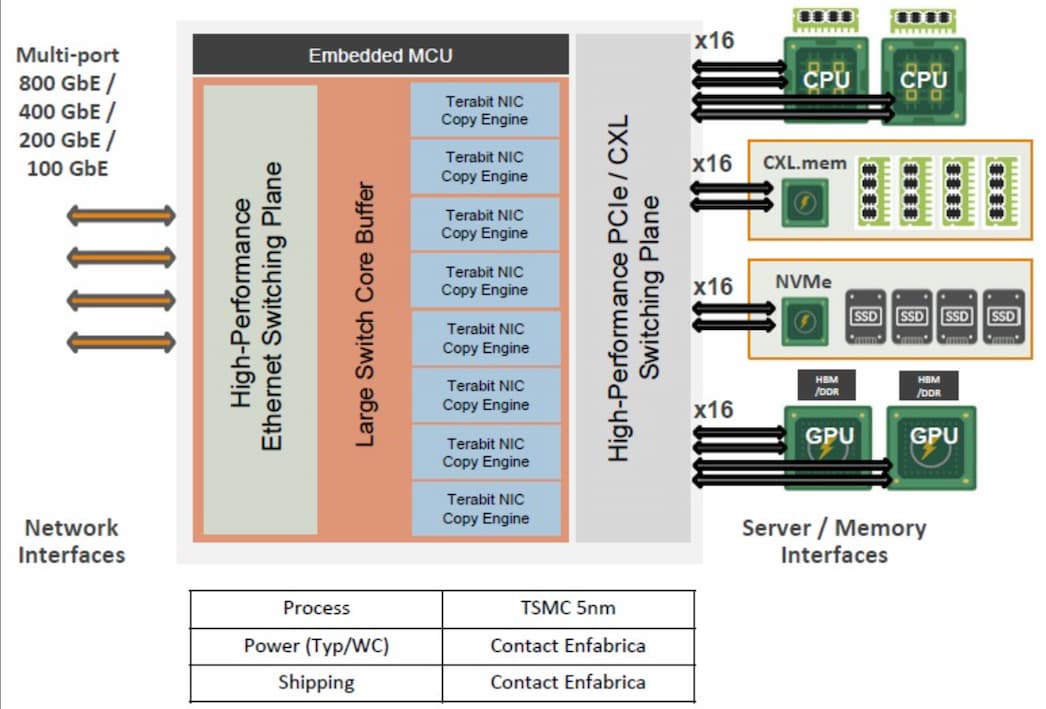
ACF-S 晶片(又稱為 SuperNIC)本質上是一顆融合乙太網路(Ethernet)與 PCI-Express/CXL 的交換晶片。
(Source:The Next Platform)
Enfabrica 創辦人暨執行長 Rochan Sankar 指出,這套系統的設計核心是自家研發的專用網路晶片,可讓 AI 運算晶片直接連接到裝滿 DDR5 記憶體規格的設備上。雖然 DDR5 傳輸速度不及 HBM,但價格卻便宜得多。
Enfabrica 試圖透過創新架構來降低記憶體成本,該公司利用自研的專用軟體,在 AI 晶片與大量低成本記憶體之間進行數據傳輸,進而在保證資料中心性能的同時,有效控制了成本。
EMFASYS 主要是做為 AI 推理工作負載的獨立記憶體加速器與擴展器,但可能只是 ACF-S 晶片組的應用之一,未來不排除搭載 NVLink Fusion I/O 晶片 的版本,讓高階 NVIDIA GPU 加速器能直接連接到 SuperNIC。
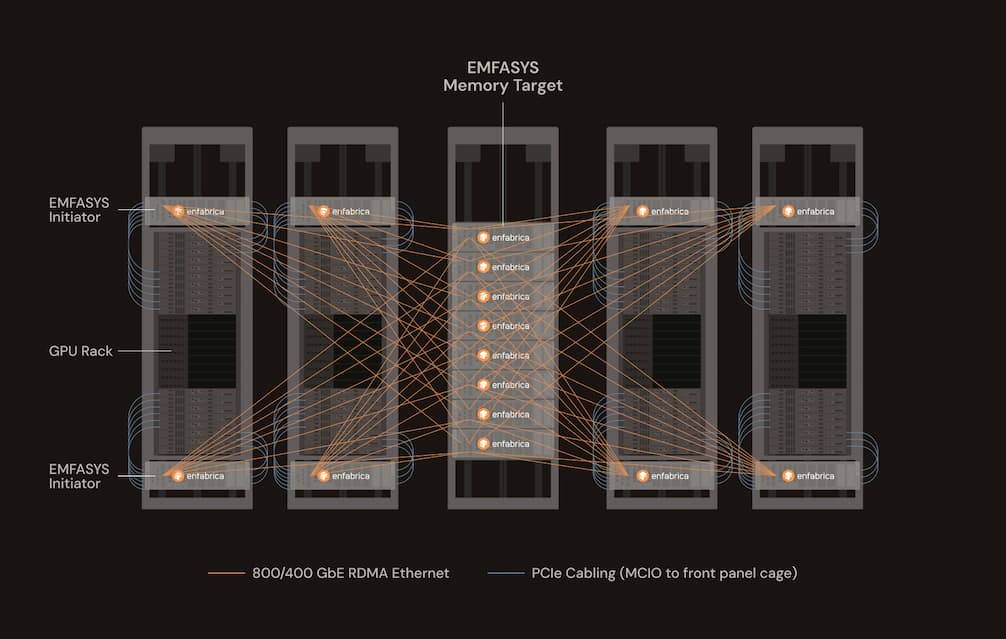
以下則為 EMFASYS 的記憶體系統。這主要是其中一種特別配置的應用,專門用來擴充系統中 GPU 與 XPU 的記憶體容量。
(Source:The Next Platform)
在中間機架中,擺放的是 EMFASYS記憶體伺服器,每個機架共有八台。每台記憶體伺服器內部安裝九顆SuperNIC,每顆 SuperNIC 提供兩個 CXL 記憶體 DIMM 通道,並透過每通道兩條 1TB DIMM,共提供 18TB 的DDR5 主記憶體容量。
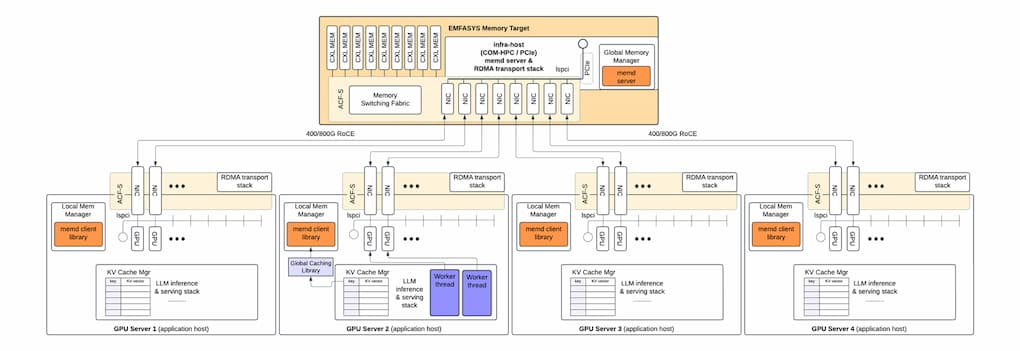
目前 EMFASYS 機器可支援 18 個並行記憶體通道,明年將提升至 28 個通道。下圖則分享 KV 快取是如何連接的。
(Source:The Next Platform)
執行長 Rochan Sankar 指出,「我們基本上是打造一個擁有大量記憶體的傳統雲端儲存目標系統,並且在晶片上設置數十個埠,將交易條帶化分散到所有記憶體上。如果有一個超寬記憶體控制器,能將寫入擴散到所有通道,你的資料就能按照需求最大化地條帶化,並用所有埠同時分攤寫入。舉例來說,傳輸一個 100GB 的檔案,依據使用的連線數與記憶體通道數,所需時間可以非常短」。
- Skimpy HBM Memory Opens Up The Way For AI Inference Memory Godbox
- 美光官網:從流行語到底線:瞭解 AI 中的 KV 快取背後的「原因」
(首圖來源:pixabay)





