



在剛結束的 SC25 超級運算大會上,GPU 大廠輝達 (Nvidia)宣布,包括 Lambda 和 CoreWeave 在內的 GPU 運算設施營運商,以及德克薩斯州高階資料中心(TACC),將採用其 Quantum-X Photonics CPO 交換機。而面對 Nvidia 在 CPO 領域的強烈競爭,博通 (Broadcom) 也展示了採用 Tomahawk 5 和 Tomahawk 6 的 CPO 交換機。雖然 CPO 交換技術的應用預計將在 2026 年爆發,但其發展過程卻是經歷了漫長的旅程。
根據 The Register 的報導,推動 CPO 轉變的核心因素可以用一句話概括,那就是「速度與電力」(speed and power)。AI 網路需要極高的傳輸速度,目前已達 800 Gbps,而 Nvidia 已經規劃透過其下一代 ConnectX-9 NICs 邁向 1.6 Tbps 的傳輸速度。然而,在如此高的速度下,直接連接銅纜僅能達到一米或兩米的距離,並且通常需要昂貴的重計時器(retimers)。若要連接數萬甚至數十萬個 GPU,可能需要數十萬個高功耗的可插拔收發器(pluggable transceivers)。單個收發器取決於傳輸速度下其功耗在 9 到 15 瓦之間。但在 AI 後端網路中使用的大型無阻塞網路中,總功耗迅速累積成巨大的負擔。
CPO 技術的出現,能夠大幅降低能耗。Nvidia 估計其 Photonics 交換機的能源效率提高了多達 3.5 倍。而 Broadcom 的數據則顯示,該技術可將光學元件的功耗降低 65%。對於一個擁有 128,000 個 GPU 的計算叢集來說,僅轉換到 CPO 交換機,就可以將可插拔收發器的數量從近 50 萬個減少到約 128,000 個。
顧名思義,共封裝光學技術就是將傳統上位於可插拔收發器中的光學元件,轉移到設備本身內部。這透過一系列光子晶片(photonic chiplets),與交換機的 ASICs 一同封裝。光纖對不再連接到 QSFP 和可插拔模組上,而是直接連接到交換機的前面板。而過去,CPO 採用的最大障礙之一是可靠性,以及故障時可能帶來的爆發半徑。也就是在傳統交換機中,一個光學可插拔模組故障只會損失一個介面。但對於 CPO,如果一個光子晶片故障,可能導致 8 個、 16 個甚至 32 個或更多介面的丟失。
為了解決這個問題,包括 Broadcom 和 Nvidia 在內的大多數 CPO 供應商選擇使用外部雷射模組。雷射是光學收發器中最容易發生故障的組件之一,將其保持在較大的可插拔形式中,不僅方便用戶維修,還能在發生故障時,透過增強其他雷射的輸出功率來進行補償。根據 Broadcom 和 Meta 的早期測試顯示,CPO 技術透過消除光學元件與交換機 ASIC 之間的電氣接口數量,不僅提供了更好的延遲,而且可靠性也顯著提高。上個月,Meta 透露,他們已在其資料中心部署了代號為 Bailly 的 Broadcom 51.2 Tbps 共封裝光學交換機,並記錄了在 400 Gbps 等效傳輸速度下,累積一百萬設備小時的無鏈路抖動運行記錄。Nvidia 也聲稱,其光子網路平台的彈性提高了 10 倍,允許訓練工作負載運行時間延長五倍而不會中斷。
當前,Nvidia 的 Quantum-X Photonics 平台專注於 InfiniBand,採用全液冷設計,配備 144 個 800 Gbps InfiniBand 介面,總頻寬達到 115.2 Tbps。這些交換機即將部署在 TACC、Lambda和 CoreWeave 的計算基礎設施中。對於偏好 Ethernet 的客戶,Nvidia 的 Spectrum-X Photonics 交換機將於 2026 年推出。它們將提供多種配置,以最大化基數為目標的型號,擁有 512 或 2,048 個 200 Gbps 介面。至於,追求最大性能的型號,則提供 128 或 512 個 800 Gbps 介面的選項。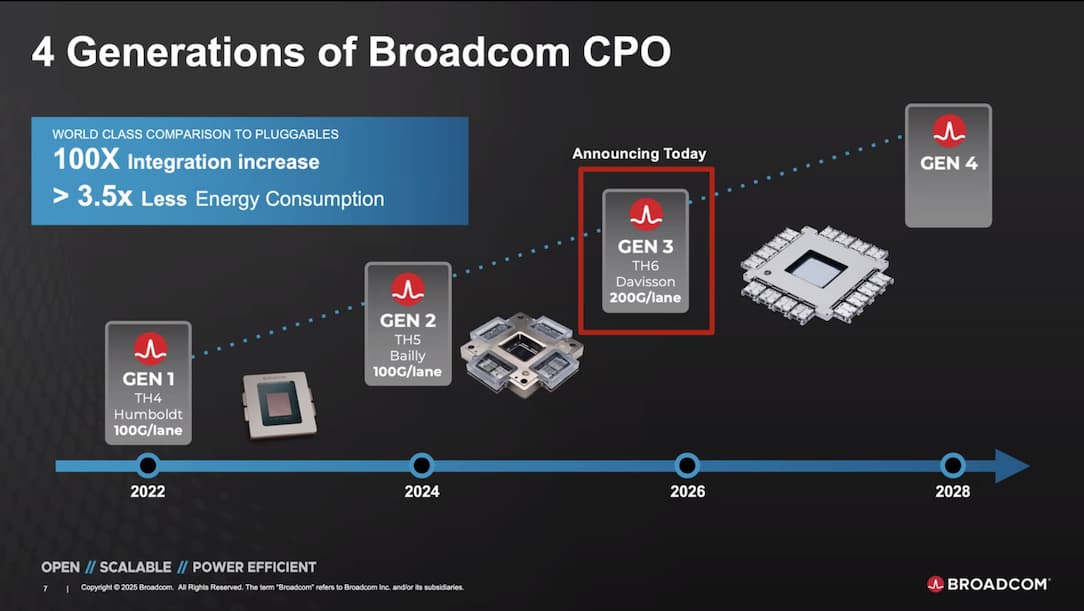
競爭對手 Broadcom 同樣展示了實力。Micas Networks 已經開始出貨採用 Broadcom 較舊的 Tomahawk 5 ASICs 和 Bailly CPO 技術的 51.2 Tbps CPO 交換機。Broadcom 還展示了其最新一代 Davisson CPO 平台,該平台採用 102.4 Tbps Tomahawk 6 交換機 ASIC,可分支出多達 512 個 200 Gbps 接口。
雖然 Nvidia 目前的光學重點仍集中在 CPO 交換機上,但 Broadcom 和其他公司正計劃很快將共封裝光學技術導入 AI 晶片本身。先前,Broadcom 在 2024 年 Hot Chips 大會上詳細介紹了一款針對大型擴展計算領域的 6.4 Tbps 光學引擎。其他正在將光學 I/O 導入加速器的公司包括 Celestial AI、Ayar Labs 和 Lightmatter。而在 SC25 大會上,Ayar Labs 也展示了與世芯 (Alchip) 合作開發的參考設計,該設計使用 UCIe-S 和 UCIe-A 互連,將 8 個 TeraPHY 晶片整合到單一封裝中,最終將為晶片間連接提供高達 200 Tbps 的雙向頻寬。
至於,Lightmatter 則從兩個方向著手光學 I/O。首先是一個 CPO 晶片,該公司聲稱可提供高達 32 Tbps(使用 56 Gbps NRZ)或 64 Tbps(使用112 Gbps PAM4)的頻寬。此外, Lightmatter 開發了一種名為 Passage M1000 的矽光子中介層(silicon photonic interposer),目的在利用光子互連技術將多個晶片鏈合在一起,用於晶片對晶片和封裝對封裝的通信。預計這些先進的技術,最終可能會完全消除對可插拔光學元件的需求,並為更高效、包含數千個加速器協同運作的擴展計算領域開創發展性。
(首圖來源:科技新報)





