



花旗銀行今(13 日)出具最新報告指出,隨著輝達(NVIDIA)採用推論情境記憶體儲存(Inference Context Memory Storage,簡稱 ICMS)等新技術,預期 NAND 供應短缺預期將進一步惡化。
輝達近日宣布將在 Vera Rubin 平台上採用 ICMS,目標是解決大規模推論運算中的記憶體瓶頸。新架構預期將採用 16TB TLC SSD,並將 KV 快取卸載至更具延展性的儲存體系,以強化 Rubin 的 AI 能力。
花旗預期,每一套 Vera Rubin 伺服器將因 ICMS 額外需要 1,162TB 的 SSD NAND,對於 2026 和 2027 年的總 TB 數也會上升,未來將進一步加劇 NAND 供應短缺情況。
輝達宣布做為全端 NVIDIA BlueField 平台一部分的 BlueField-4 資料處理器,將驅動 NVIDIA 推論情境記憶儲存(ICMS)平台。此平台為全新一代的 AI 原生儲存基礎架構,專為開拓下一個 AI 前沿而設計。
輝達指出,隨著 AI 模型擴展至數兆個參數與多步驟推理,產生大量情境資料,以 KV 快取表示,對準確性、使用者體驗與連續性至關重要。由於會對多代理系統中的即時推論造成瓶頸,因此 KV 快取無法長期儲存在 GPU 上。AI 原生應用需要全新類型的可擴充基礎架構,以儲存並分享這些資料。
什麼是 KV 快取(KV Cache)?
在 AI 推理階段,會用到一種類似人腦的「注意力機制」,包括記住查詢中重要的部分(Key)以及上下文中重要部分(Value),以便回答提示。如果每處理一個新的 token(新詞),模型必須針對先前處理過的所有 token 重新計算每個詞的重要性(Key 與 Value),以更新注意力權重。
換言之,好比學生每讀一個新句子都要重新回顧整篇文章,過程會相當耗時。KV 快取則類似筆記的概念,能將重要資訊記錄下來,當有新的 token 時,不需要再重新回顧,直接從筆記裡的資訊即可計算新的注意力權重。
也因此,大語言模型(LLM)被加入一種稱為「KV 快取」的機制,能將先前的重要資訊(Key 與 Value)儲存在記憶體中,免去每次重新計算的成本,從而將 token 處理與生成速度提升數個數量級。
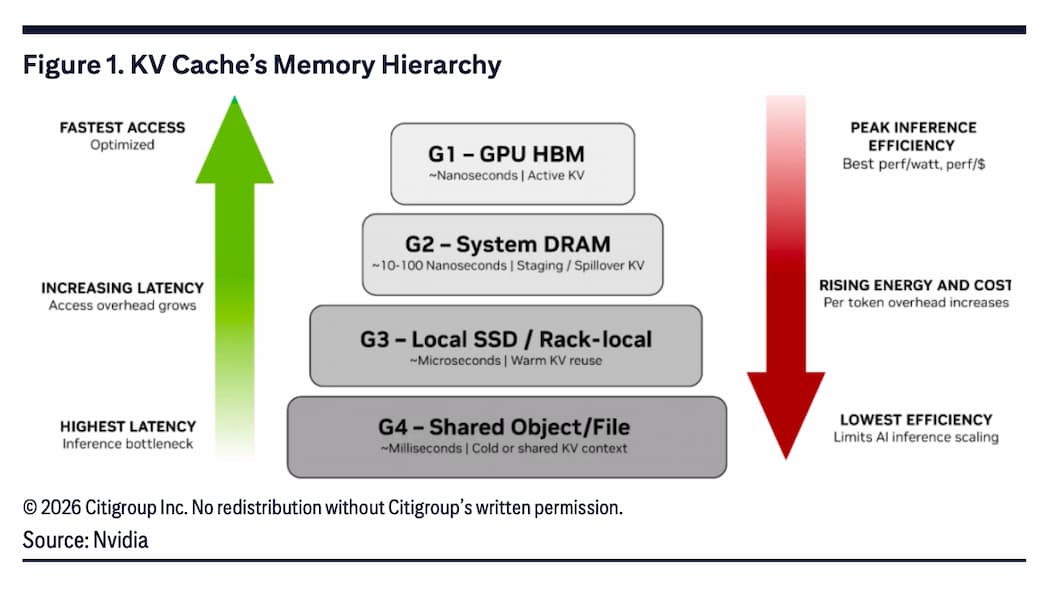
將 KV 快取可配置在不同運算記憶體中
簡單來說,KV 快取是「AI 模型的短期記憶」。由於已經儲存先前已計算過的 key-value 配對,以避免重複運算。依據記憶體階層不同,KV 快取可配置在不同的運算記憶體層級中。
例如,KV 快取可配置於 GPU HBM(G1),做為主動 KV 快取;配置於系統 DRAM(G2)做為暫存/外溢的 KV 快取;或者,做為置於本地 SSD(G3)中的暖 KV 快取;最後一種是容量最大、可跨節點共享的 KV 快取儲存層(G4)。
花旗指出,該平台透過「卸載 KV 快取」至更具延展性的儲存選項,使記憶體容量突破 HBM 限制,以此實現每秒處理 token 數提升,最高可達 5 倍;能源效率提升高達 5 倍;同時讓延遲更低。
花旗指出,ICMS 在本地 SSD(G3)與共享企業級儲存(G4)之間新增一層。做為 G3.5 的 KV 快取層(下圖紅框處),ICMS 將支援把 G4 的冷 KV 快取資料轉為 G2 的暖 KV 快取資料,以提升資料存取速度,並與 HBM 有機協同運作。

花旗預期,全球 NAND 供應短缺將進一步惡化,因為 Vera Rubin 平台預期將為 ICMS 運作採用 16TB TLC SSD,成為全球 NAND 需求成長動能。其中,每一套 Vera Rubin 伺服器系統需額外配置 1,152TB 的 SSD 才能運作 ICMS。
考慮到 2026 年和 2027 年 Vera Rubin 伺服器出貨量分別為 3 萬和 10 萬台,將進一步推升 NAND 需求。花旗認為,輝達宣布採用 ICMS,將成為 NAND 供應商的正向催化劑,主要受惠者包括三星、SK 海力士、SanDisk、鎧俠及美光。
(首圖來源:輝達)





