根據 TrendForce 最新 AI server 研究,在大型雲端服務供應商(CSP)加大自研晶片力道的情況下,NVIDIA 於 GTC 2026 大會改為著重各領域的 AI 推理應用落地,有別於以往專注雲端 AI 訓練市場。其推動 GPU、CPU 以及 LPU 等多元產品軸線分攻 AI 訓練、AI 推理需求,並藉由 Rack 整合方案帶動供應鏈成長。
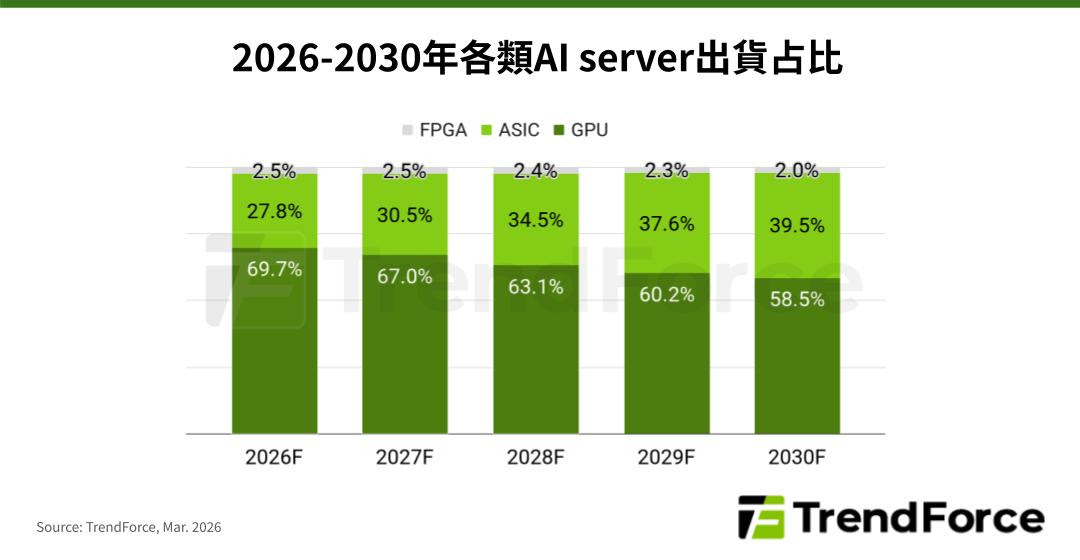
TrendForce表示,隨著以Google、Amazon等CSP為首的自研晶片態勢擴大,預估ASIC AI server占整體AI server的出貨比例將從2026年的27.8%,上升至2030年的近40%。