



在人工智慧(AI)領域進入兆級(gigascale)時代的背景下,全球每天皆聽到關於多少 GW 的 AI 基礎設施正在建置的消息,資料中心也變得日益密集且功能強大。在這其中,輝達 (NVIDIA ) 正積極推動技術、複雜性、創新與發明,以建立這些被譽為世界上最偉大的工程奇蹟的資料中心。這些資料中心不僅能在 AI 方面取得驚人成就,它們本身更是會升值的資產,隨著時間推移變得更智慧、更有價值且成本更低。
現有架構的突破:GB200 成本與性能革命
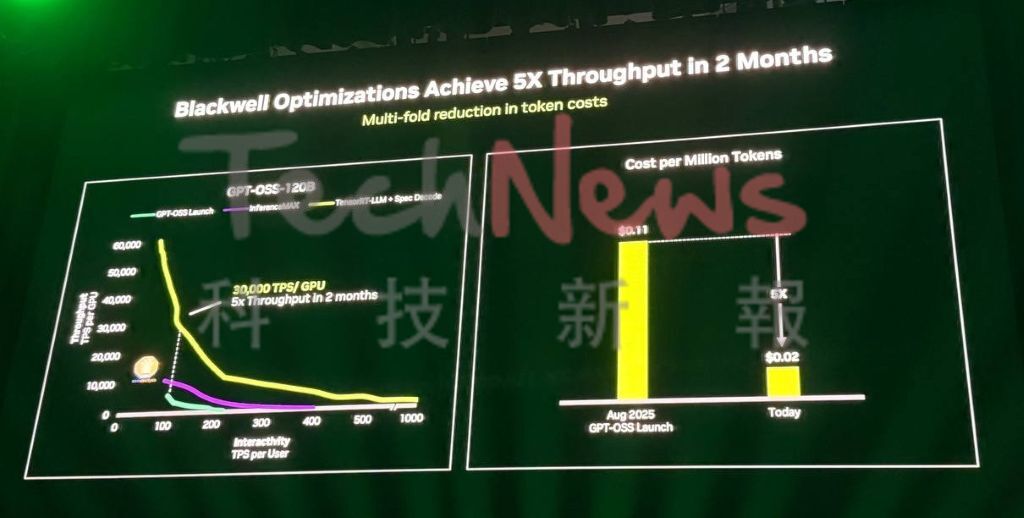
2025 年全球開放運算高峰會輝達表示,現有架構展現驚人的性能提升。因為僅兩個月內,輝達就將 B200 資料中心對開放原始碼 AI 模型 GPTO OSS 的性能提升了 5 倍。這一性能上的顯著改進,使資料中心提供每百萬個 token 的成本從 11 美分大幅降至僅 2 美分。
在實際應用中,這種性能提升直接轉化為營收。例如,在 Semi Analysis 推理最大基準測試中,搭載 NVL72 的 GB200 資料中心在處理 Deepseek R1 模型時,比同等的 H200 系統高出 15 倍的性能,這直接影響了資料中心的營收。
另外,所有在 OCP 中為推進和改進性能所做的努力,包括提高機架的智慧性、更高的密度、更智慧高效的電力傳輸以及 Scale Up 和 Scale Out 互連技術,都在建設能大幅降低成本、提高性能的資料中心。這些資料中心甚至會隨著時間的前進自行變得更智慧,進一步優化這些指標。
AI 模型的複雜性與情境處理的挑戰
輝達指出,隨著 AI 推理與模型複雜性呈爆炸式成長,所需的 AI 核心數量急劇增加。過去處理如 Llama 3 這類單一密集模型時,可能需要約 10,000 個不同的 AI 核心。然而,如今面對 HSCR1 和 GPTO OSS 等模型,為了提供高性能,則需要約 1,000 萬個核心。這種複雜性源於模型的規模、大小,以及經常包含數百個專家的混合專家模型。

未來,推理的關鍵方向之一是「情境」。這指的是模型在提供第一個 token 或答案之前必須學習或攝取多少資訊。暉達預見,未來的應用可能需要模型攝取約一百萬個 token 後,才能給出第一個答案。而這種高價值應用情境涵蓋了電影製作、影片、媒體和內容生成。今天的多媒體內容生成市場約為 40 億美元,預計在未來十年內將增長到 400 億美元。例如,在編程領域,AI 代理可能需要理解數百萬行代碼,才能添加新功能。
2026 年下一代 Vera Rubin 架構
為了解決情境處理的挑戰,輝達宣布下一代架構 Vera Rubin 將於 2026 年下半年推出。該架構將部分貢獻給 OCP 社群,並與現有的 GB200 OCP 基礎設施和機架兼容。

輝達介紹 了Vera Rubin 架構。首先,在 Vera Rubin 架構的關鍵創新在於採用雙晶片設計,其中 CPX 處理器部分,專門用於情境處理,它具備豐富的計算能力,但對 IO 和記憶體頻寬的需求較低。至於,Ruben GPU 部分,則是整合為一個單一的解決方案,使得 Vera Rubin 提供超過 8 exaflops 的推理性能,比 GB200 高出 7.5 倍以上,並配備更多的記憶體。在網路方面,將升級至 400G Scale Up 網路,跨所有 GPU 提供 260 TB/秒的頻寬,是 GB200 的兩倍。

另外,Vera Rubin 完全兼容輝達在 GB200 中定義的 OCP NGX 基礎設施。輝達正致力於貢獻全新的 OCP NGX 兼容運算托盤,該托盤將達成 100% 水冷。而該系統也將支持與 GB200 相同的 45 度磁性入口溫度,這代表著資料中心可以利用現有的水冷基礎設施,無需使用更多的冷卻器,而且利用相同的電纜壓力、OCP 機架,並兼容 MGX 和 OCP 兼容底座系統。

輝達也展示 MGX 機架創新設計用於 Vera Rubin 的內容,包括全新 500 安培全水冷匯流排,已提高機架和電力傳輸的能效,減少熱量浪費。還採用靈活的 100 安培 whips 新電源傳輸、SU 自動傳輸開關來提高彈性,也就是當一個機架故障時,另一個可以接替。最後是模組化 L1 領域,達到更好的可維護性和可配置性。而為達成異構計算的緊密耦合,輝達還推出 NVLink Fusion。這是一種 IP 和小晶片技術,允許其他 CPU 和加速器參與 NVLink 和 OCP 設計基礎設施。
輝達宣布多項合作夥伴關係
- 富士通(Fujitsu)旗下 Monaka 處理器將使用 NVLink Fusion 協議與輝達的 GPU 進行緊密耦合。
- 英特爾(Intel)將製造 Fusion 兼容 CPU,以便在資料中心環境中連接到輝達 GPU。
- 輝達正在將三星(Samsung)加入到現有的 Alchip、Alstera 和 RL MediaTek 名單中,協助社群將他們的加速器與輝達 CPU 或 NVLink 整合。

輝達強調,將數十萬乃至百萬級 GPU 連接到一起是一項艱鉅的任務,這需要乙太網標準的支持,這使得輝達對 Spectrum 在 AI 資料中心世界的進展和採用感到興奮。目前,Meta 已宣布向 OCP 貢獻採用 Spectrum XP 和 Facebook 開源交換系統(FBOSS)的 Miniack 3N 交換機。而微軟旗下的 Fairwater 資料中心是世界上最大、最快的 AI 超級電腦之一,採用開放標準乙太網構建,其數十萬 GPU 的背板互連是以 Spectrum X 和 OCP SONiC 操作系統為主。

至於,甲骨文(Oracle)及 OpenAI 共同規劃的星際之門 (Stargate) 資料中心是世界上最大的 AI 超級電腦基礎設施之一,其第一個資料入口就是採用 Spectrum 和 OCP 技術構建,達成了 95% 的有效頻寬和零應用延遲。其他採用輝達 Spectrum XGX 技術的資料中心,在採用 OCP 軟體和標準下,允許多站點進行連接,跨越不同地理區域,甚至整個大陸進行百萬級 GPU 規模的訓練。
展望 2027 年 Kyber 與 800V DC 基礎設施
2027 下半年,輝達將推出 Kyber 設計。Kyber 的目標是將 500 個 GPU 連接到單一機架中。為達成這種規模和能耗密度,輝達正與業界合作,推動 800V 伏特 DC 直流電基礎設施,這是 Mount Diablo 努力的一部分。許多合作夥伴已經開始規劃圍繞 800V DC 的資料中心。
輝達進一步指出,這種基礎設施是與 OCP 社群共同建立的。這是一種能提供驚人 AI 能力,並且能在未來數年內持續成長和擴展的數據中心。輝達已設置 MGX 生態系統牆,展示構建世界上最強大 AI 系統的各種元件。
在 Instagram 查看這則貼文
(首圖來源:科技新報攝)





