



最快且成本效益最高的 Gemini 3 系列新模型——Gemini 3.1 Flash-Lite 來了,是為大規模、高頻率的工作負載所打造。
根據 Artificial Analysis 基準測試,Gemini 3.1 Flash-Lite 在回應首字元所需時間比 Gemini 2.5 Flash 快 2.5 倍,輸出速度提升 45%,同時維持相似或更好的品質。這種低延遲對高頻工作流程相當重要,成為開發者建構即時、回應敏捷體驗的理想模型選項。
在 Arena.ai 排行榜上,Gemini 3.1 Flash-Lite 取得令人印象深刻的 1,432 Elo 分數,並在多項推理與跨模態理解基準測試超越其他同級模型,包括在 GPQA Diamond 得到 86.9%、在 MMMU Pro 得到 76.8%,甚至勝過 Gemini 2.5 Flash 等較大規模的 Gemini 模型。
除原生效能外,Gemini 3.1 Flash-Lite 在 Google AI Studio 與 Vertex AI 配備「思考等級」,讓開發者控制模型在執行任務時要投入多少「思考」程度,對於管理高頻率工作負載非常重要。Gemini 3.1 Flash-Lite 可處理大規模任務(比方說大量翻譯與內容審查),同時也能勝任比較深度推理的複雜工作,例如生成使用者介面與儀表板、建立模擬或遵循複雜指示。
Google AI Studio 與 Vertex AI 早期存取的開發者,以及像 Latitude、Cartwheel、Whering 等公司,已在使用 Gemini 3.1 Flash-Lite 解決大規模複雜問題。參與早期測試的開發者強調 Gemini 3.1 Flash-Lite 效率與推理能力,表示它能以接近更高等級模型的精準度處理複雜輸入,並能遵循指示且維持一致性。
Gemini 3.1 Flash-Lite 收費為每百萬個輸入詞元(token)收費僅 0.25 美元、每百萬個輸出詞元收費僅 1.5 美元,價格是 Gemini 3.1 Pro(輸入 2 美元、輸出 12 美元)的八分之一,能以遠低於大型語言模型的成本提供強化的性能。比較模型等級與價格下,Gemini 3.1 Flash-Lite 可提供高品質表現。
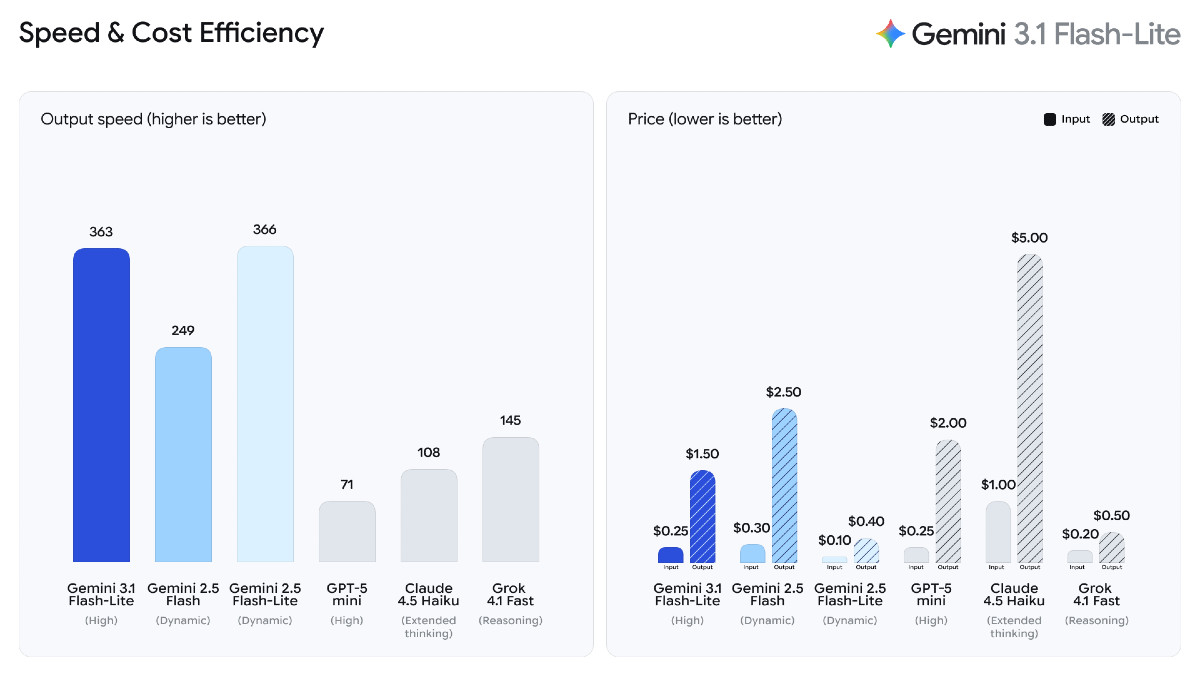
▲ Gemini 3.1 Flash-Lite 擁有成本效益。
Gemini 3.1 Flash-Lite has landed.
It’s our most cost-efficient Gemini 3 series model yet, built for intelligence at scale. Here’s what’s new 🧵 pic.twitter.com/BzD2bdg3Dx
— Google DeepMind (@GoogleDeepMind) March 3, 2026
▲ Gemini 3.1 Flash-Lite 在速度和品質方面優於 Gemini 2.5 Flash。
這次模型發表距離 Gemini 3.1 Pro 在上個月首次亮相僅幾週時間,定位策略分明,使開發者與企業客戶能在不同層級擴展智慧應用。即日起,Gemini 3.1 Flash-Lite 以預覽形式,透過 Gemini API 在 Google AI Studio 向開發者開放,並透過 Vertex AI 平台提供給企業客戶。
(圖片來源:Google Blog)





