



先前輝達(NVIDIA)在論文中公開壓縮 KV 快取的新技術 KVTC,如今 Google 也在 Google 部落格中分享最新的「TurboQuant」技術,表示會以極致壓縮重新定義 AI 效率,而這項技術在業界掀起討論,大摩甚至以「另一個 DeepSeek 時刻」來表示這可能顛覆 AI 技術曲線。而這項技術到底是怎麼運作的?《科技新報》帶你一次了解這項新技術。
這篇部落格由 Google 研究院的研究科學家 Amir Zandieh 和副總裁暨 Google 研究員 Vahab Mirrokni 撰寫,表示會提出一個先進、具有理論基礎的量化(quantization)演算法,為大型語言模型與向量搜尋引擎帶來大幅壓縮能力。
目前 Google 和 NVIDIA 都想辦法透過 KV 快取來降低記憶體用量,以提升算力,外界也期待隨著更多企業投入,進一步促使成本和用量降低。若想知道 NVIDIA 的 KV 技術,可見〈LLM 記憶體用量縮減 20 倍!NVIDIA 超狂新技術 KVTC,靠「KV 快取」翻轉記憶體瓶頸〉。

(Source:AI 生成)
傳統資料壓縮技術有哪些問題?想解決記憶體反而增加用量
該部落格指出,向量是 AI 模型理解與處理資訊的基本單位,「低維向量」(Small vectors)能描述簡單屬性,例如圖中一個點;而「高維向量」(High-dimensional vectors)能捕捉複雜資訊,例如影像特徵、詞語語意或資料集特性。由於高維向量極為強大,但也會消耗大量記憶體,進而在關鍵的 KV 快取中形成瓶頸。
小知識:KV 快取
KV 快取可視為一種高速「數位速查表」,以簡單標籤儲存常用資訊,使電腦能即時存取,而不需搜尋龐大且緩慢的資料庫。
Google 研究員指出,傳統的資料壓縮技術「向量量化」(Vector quantization)可縮減高維向量的大小,這能改善 AI 兩個核心面向:一是加速向量搜尋,使相似度查詢更快;二是緩解 KV 快取的瓶頸,透過縮小鍵值對(Key-Value Pairs)的大小,即將 KV 快取的每一筆資料都縮小,從而加快相似度搜尋速度,並降低記憶體成本。
然而,傳統的向量量化通常會增加記憶體的額外負擔,雖然縮小了向量大小,但每個小區塊都必須存取額外的量化參數,每個數值反而會增加 1~2 個 bit,這反而抵銷了原本的記憶體壓縮效益。
這次 Google 將介紹的新壓縮演算法「TurboQuant」(將於 ICLR 2026 發表),可最佳化解決量化記憶體負擔問題。之後也將分享兩個技術:Quantized Johnson-Lindenstrauss(QJL)與 PolarQuant(將於 AISTATS 2026 發表),作為 TurboQuant 的核心組件。在測試中,這三項技術在降低 KV 快取瓶頸的同時,仍能維持 AI 模型效能,對於搜尋與 AI 領域等場景都具備潛力。
TurboQuant 是什麼?它是怎麼運作的?
TurboQuant 是一種壓縮方法,能在不損失準確度的情況下大幅縮減模型大小,特別適用 KV 快取與向量搜尋。這個流程主要分為兩階段,首先是透過高品質壓縮(PolarQuant 技術),再來消除隱藏誤差(QJL 技術),進而達到壓縮效果。
步驟一:高品質壓縮(採 PolarQuant 方法)
TurboQuant 首先會隨機旋轉資料向量,以簡化資料的幾何結構,能輕鬆將標準的高品質量化器分別套用至向量的每個部分進行處理。在這階段,使用了大部分的位元(bits)用來捕捉原始向量的主要資訊與強度,並提供主要的壓縮效果。
小知識:量化器
量化器的作用是將大量連續數值(如精確的小數)映射到較小、離散的符號或整數,例如音訊量化或 JPEG 壓縮。
步驟二:消除隱藏誤差(採 QJL 演算法)
TurboQuant 使用極少的剩餘位元(僅 1 bit)對第一階段留下的微小誤差套用 QJL 演算法。QJL 在此扮演「誤差修正器」,可消除偏差(bias),從而提升注意力分數(attention score)的準確性。
TurboQuant 外還有兩項技術超重要!QJL 與 PolarQuant 是什麼?
Google 剛剛在上述提到 QJL 與 PolarQuant 也是非常重要的技術。
QJL 技術是什麼?
首先是 QJL,這項技術採用一種名為 Johnson-Lindenstrauss Transform 的數學方法,能壓縮複雜的高維技術,同時保留資料點之間的距離與關係。
Google 指出,這項技術可將每個向量數值簡化為單一符號位元(+1 或 -1),這算建立了一種高速的資料「速記形式」,且不需要額外記憶體負擔。此外,為了維持準確度,QJL 使用一種特殊估算器(estimator),可在高精度查詢與低精度資料之間取得平衡,使模型仍能精確計算注意力分數(判斷哪些輸入資訊重要、哪些可以忽略的機制)。
PolarQuant 技術是什麼?
PolarQuant 則以完全不同的方式來解決記憶體的額外負擔問題,甚至說「重新定義壓縮」。
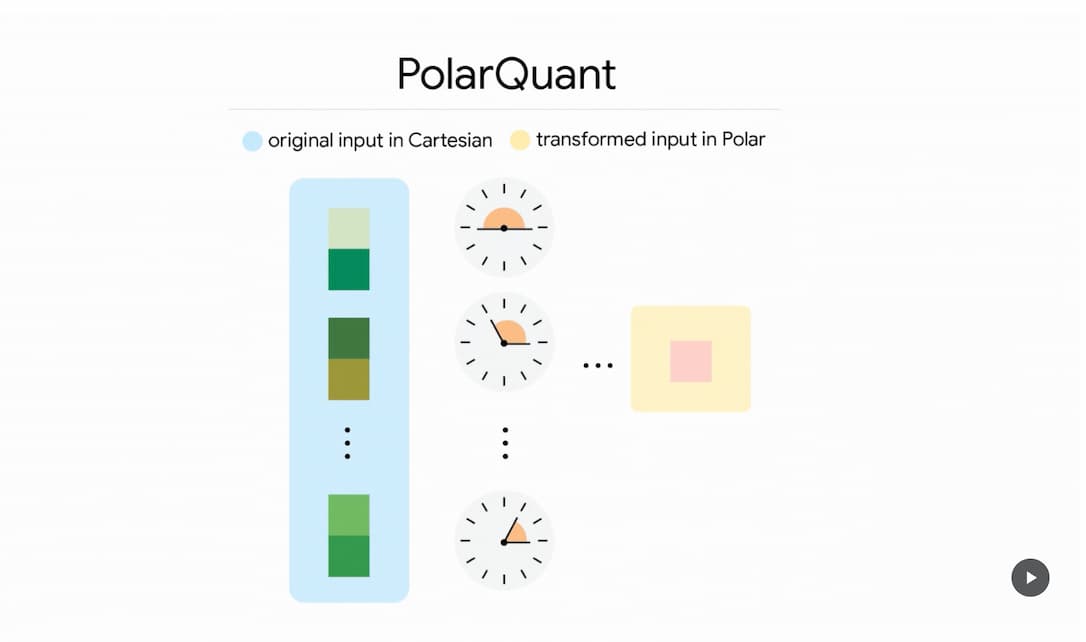
Google 解釋,過去是使用 X、Y、Z 等標準座標來描述向量,但 PolarQuant 技術是將向量轉為「極座標」(Polar),會以「簡寫」方式儲存與處理。舉例來說,過去可能描述「向東走 3 個街區、向北走 4 個街區」,但在新技術下會描述「以 37 度角走總共 5 個街區」,是相當不同的詮釋方式。
這種表現方式會產生兩種新的資訊,即半徑(代表核心資料的強度)和角度(代表資料的方向或意義)。
這種角度模式具有已知且高度集中的特性,因此模型不再需要執行昂貴的資料標準化(normalization)步驟。
另從下圖中可知,過去的圖像呈現方式是方形的,而極座標呈現方式為圓形,Google 解釋,當資料被映射到一個固定且可預測的圓形網格上時,邊界是已知的,不像傳統的方形網格那樣不斷變動邊界,這使 PolarQuant 能消除傳統方法必承擔的記憶體額外負擔。
TurboQuant 兩項指標取得最佳表現!KV 快取記憶體減少 6 倍、效能增 8 倍
接著,Google 使用開源大型語言模型(Gemma 與 Mistral),在多個標準長上下文基準測試上,對這三種演算法進行嚴謹評估,其中包括 LongBench、Needle In A Haystack、ZeroSCROLLS、RULER 及 L-Eval。
最後實驗數據顯示,TurboQuant 在「點積失真」(dot product distortion)與「召回率」(recall)兩項指標上均達到最佳表現,同時顯著降低鍵值(KV)記憶體占用。
Google 也分享 TurboQuant、PolarQuant 以及基準方法 KIVI 在問答、程式碼生成與摘要等不同任務中的綜合效能表現。
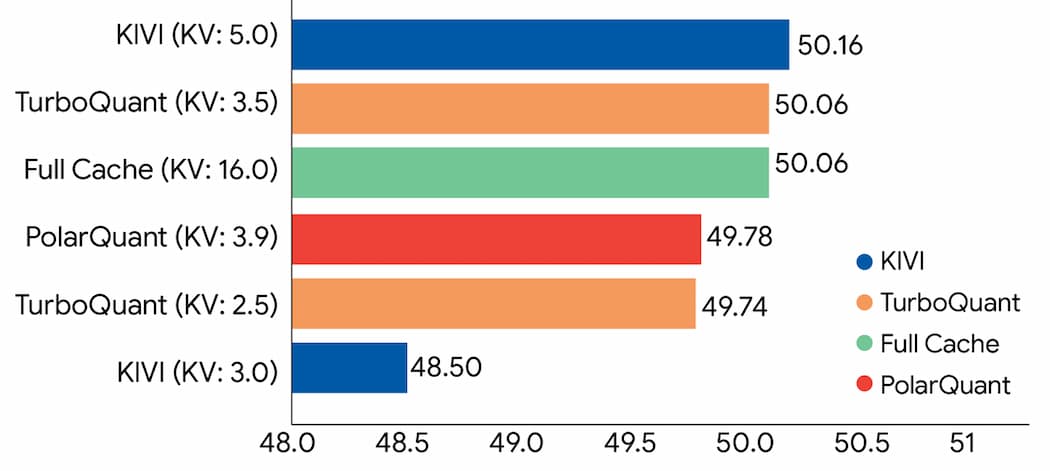
其中,在長上下文的「大海撈針」任務中,是測試模型能否在大量文本中找到極小且特定資訊,結果顯示 TurboQuant 在所有基準測試中都達到完美的下游任務表現,同時將 KV 記憶體大小至少降低 6 倍以上,而 PolarQuant 在此任務中也幾乎沒有精度損失。
Google 指出,TurboQuant 證明在無需訓練或微調的情況下,可將 KV 鍵值快取量化至僅 3 位元,且不會犧牲模型準確度,同時執行速度還比原始 LLM(Gemma 與 Mistral)更快,這代表實作效率極高,執行時幾乎不會產生額外負擔。
接著,Google 也展示了使用 TurboQuant 計算注意力對數(attention logits)時所獲得的加速效果。直接從結果來看,在 H100 GPU 加速器上,4 位元 TurboQuant(4-bit TurboQuant,即淡黃色直線)相較於 32 位元未量化鍵值,性能提升最高可達 8 倍。
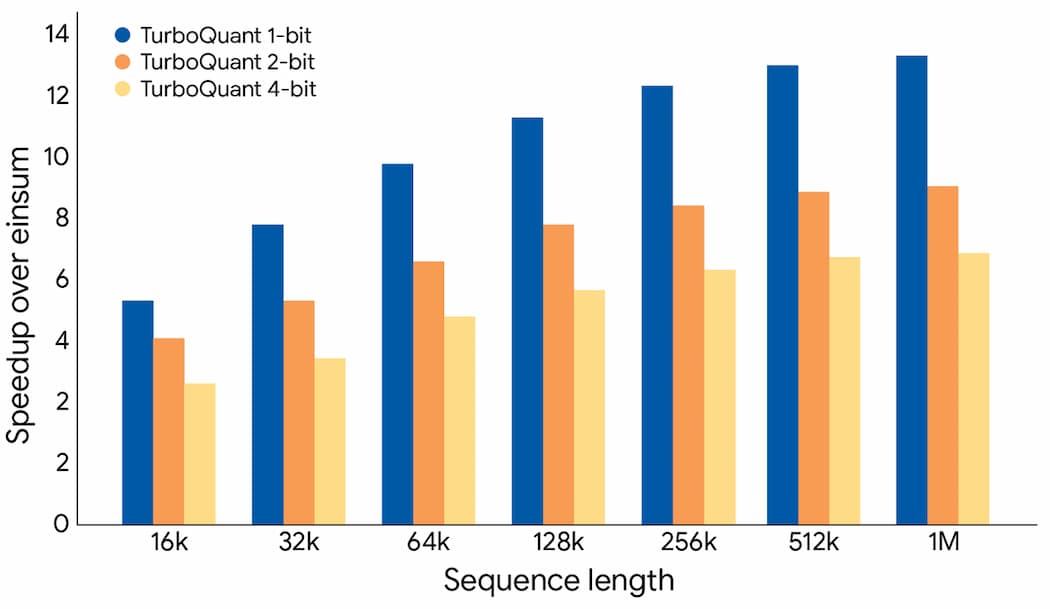
Google 認為,這非常適合用在向量搜尋等應用場景,能大幅加速索引建立流程。
接著,Google 也將 TurboQuant 與目前最先進的方法 PQ、RabbiQ 進行比較,確認在高維向量搜尋任務中、使用 1@k 召回率的結果。最後發現,TurboQuant 仍持續更優異的召回率,也驗這了其在高維搜尋任務中的穩健性與效率。
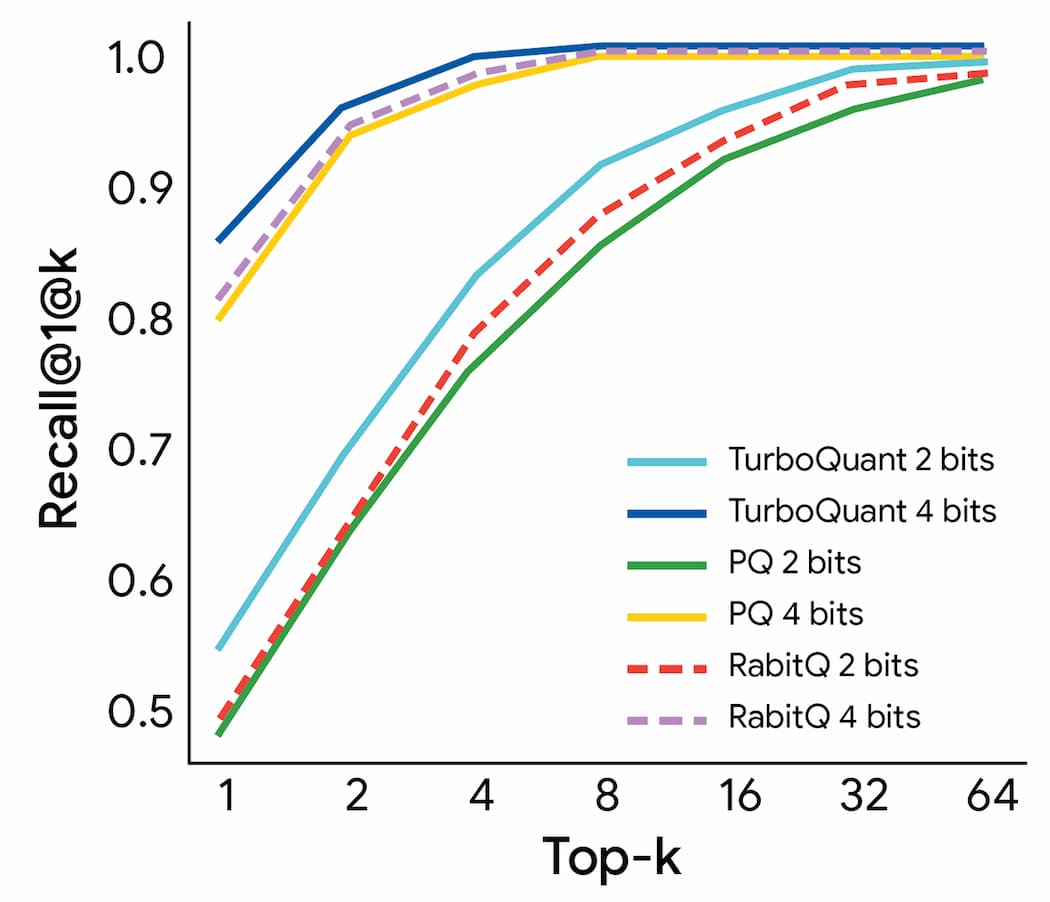
Google 認為,TurboQuant 這項技術其中一個應用是解決大語言模型中的 KV 快取瓶頸,但預期也會有更多應用,尤其能在極低記憶體使用量、幾乎為零的前處理時間,以及最先進的準確度條件下,建立並查詢大規模向量索引,有助於 Google 的語意搜尋變得更快速且更高效率。
看好 TurboQuant 前景,大摩直言是「另一個 DeepSeek 時刻」
Google 發布這項技術時,便引起外界討論。美系外資摩根士丹利(大摩)認為,目前 AI 服務擴展最大瓶頸在於「KV 快取」,若模型能在顯著降低記憶體需求的情況下維持效能,每次查詢的服務成本可大幅下降,進而提升 AI 部署的獲利能力。
而 TurboQuant 縮小資料體積與資料傳輸量,提升了加速器的吞吐效率,並降低單次查詢成本,有助於降低成本。
大摩認為,短期來看,TurboQuant 主要針對推論階段的 KV 快取進行壓縮,對模型權重(GPU/TPU 上的 HBM 使用量)與訓練工作負載並無影響。然而,它可以讓相同硬體支援 4 到 8 倍更長的上下文,或在不耗盡記憶體的情況下處理更大的 batch size(批次大小)。因此,這並非表示整體記憶體或硬體需求降低 6 倍,而是「效率提升」,增加每顆 GPU 的吞吐量。
至於長期部分,大摩表示將出現「Jevons Paradox」(傑文斯悖論)效應,效率提升反而推動總需求增加。從這個角度來看,TurboQuant 與其說是漸進式優化,不如說是「改變 AI 部署的成本曲線」,甚至以「另一個 DeepSeek 時刻」來解釋這項技術。
(首圖來源:Unsplash)





