



你花錢買了一本書,卻發現作者壓根不存在,這是知名心臟病專家艾瑞克·托波爾(Eric Topol)教授的真實遭遇,亞馬遜卻有數十本冒充他名號和肖像的烹飪書與健康指南大肆販售,他卻毫不知情。Topol 怒稱這是「徹頭徹尾的詐欺」,他的亞馬遜維權之路也彷彿打在棉花上,只換來客服冷冰冰的罐頭回覆。
在 Instagram 查看這則貼文
這只是冰山一角。
最近知名風投a16z公布令人深思的數據:ChatGPT橫空出世後,亞馬遜電子書月發行量直接翻兩倍。到2025年末,每月新書上市量飆升到誇張的30萬本。說穿了,你現在隨便逛逛電子書賣場,映入眼簾的新書,很大部分都是AI產生的流水線產品。
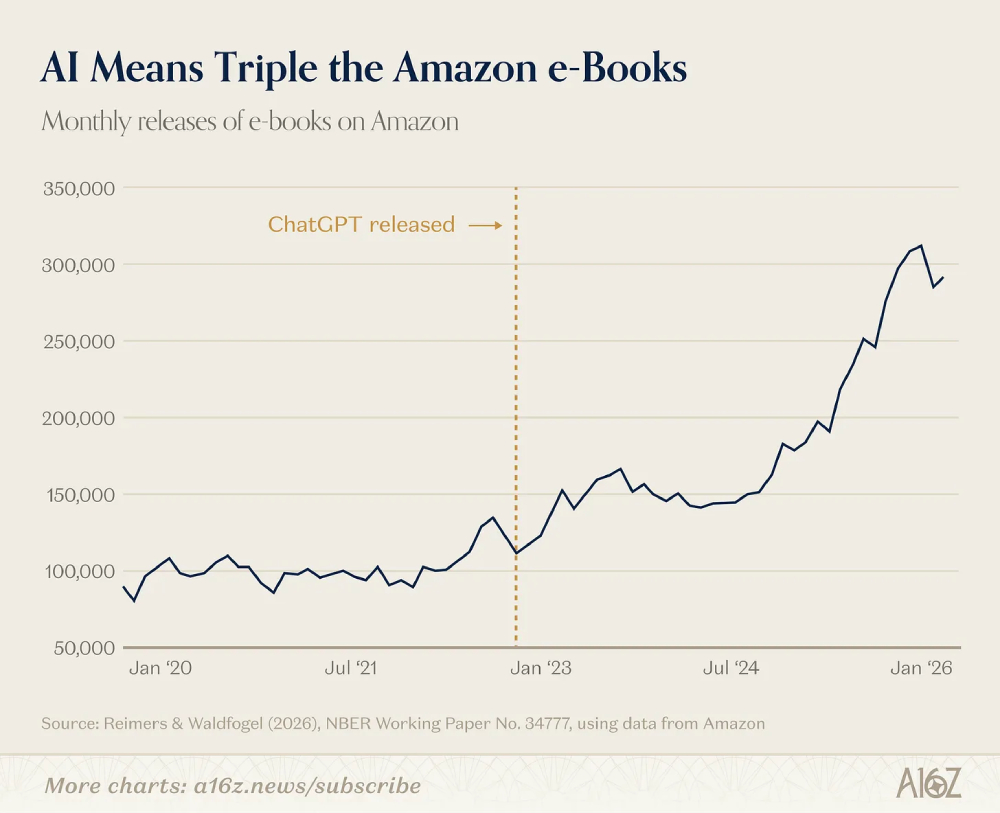
(Source:a16z)
2026年的出版界很魔幻,我們熟悉的「白紙黑字即是權威」信任體系,已被無孔不入的AI慢慢瓦解。
被AI書籍包圍的電子書架
想像極具畫面感的場景:夜深人靜,你裹著毯子,捧著一本剛買的熱門奇幻言情小說《Darkhollow Academy: Year 2》,準備讓主角的極限拉扯幫你分泌多巴胺。結果翻到最刺激的章節,劇情急轉直下,赫然出現一行字:「我已經重寫這段文字,使其更符合J. Bree的風格,這種風格包含更多緊張感。」
這才不是打破第四面牆,而是作者連AI提示詞都忘了刪,直接一鍵出版。甚至若你想當「暢銷書作家」,門檻已低到超乎想像。
你只需要花幾十塊美元訂閱AI工具「Youbooks」,就能幫你融合ChatGPT、Claude、Gemini甚至Llama,每月提供數十萬字額度。它能一鍵編造看似邏輯嚴密的內容,自動從網路抓取最新資料,連排版都能搞定,最後直接匯出PDF或EPUB格式。
有了這種神器,投機分子簡直殺瘋了。
27歲年輕人Tommi Pedruzzi在社群網路高調炫耀,說自己靠大量產生1,500本AI電子書,硬生生在亞馬遜賺到300萬美元。他分享暴富哲學時直言:「出版一本沒人想讀的書毫無意義。」
At 24, I lost $60k in crypto.
At 28, I make $50k/month selling eBooks on Amazon.
Now, I’m finally giving away my entire strategy for free.
This is your only chance to get it before it goes private.
(Limited to only 500 people)
Inside, I’ll show you how to create, package,… pic.twitter.com/adVoraZgkA
— Tommi Pedruzzi (@TommiPedruzzi) March 28, 2026
雖然很快就有Reddit網友肉搜亞馬遜根本搜不到他署名的書,並戳穿他真正賺錢管道是靠賣「教你如何用AI致富」的課程割韭菜。但無論真假,這種大量製造「電子水貨」公式,污染各大出版平台的嚴重程度卻真實存在。更有意思的是這群人蹭熱度的手速和下限。
英格蘭女足去年剛贏得歐洲盃,亞馬遜瞬間就冒出一堆英格蘭職業女子足球運動員克洛伊·凱利(Chloe Kelly)等球員的偽傳記。這些書有多敷衍?封面不僅粗製濫造,甚至誤置成美式足球。全書不到50頁,標價11英鎊,主打願者上鉤。英格蘭女足國家隊前隊長斯蒂夫·霍頓(Steph Houghton)發現自己辛苦寫了300多頁的自傳,被AI抄襲寫成50頁的殘障品,氣得直呼「太差勁了」。
這種粗製濫造也全面圍剿真實創作者。
知名記者卡拉·斯威捨(Kara Swisher)新書剛出版,亞馬遜立刻被各種假冒AI傳記和總結包圍;喜劇演員瑞斯·詹姆斯(Rhys James)發現多本以自己為主角的AI垃圾傳記,封面全是用AI畫的假人。
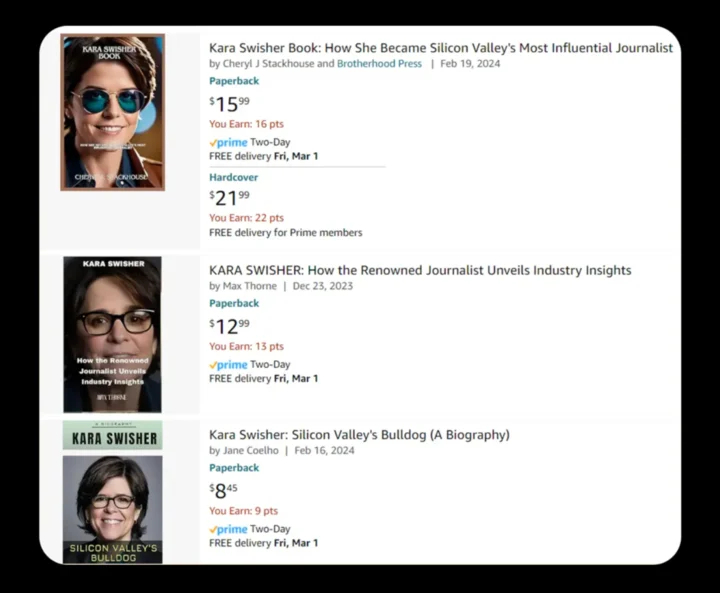
面對洶湧的AI海嘯,平台應付手段卻非常無力。亞馬遜曾規定,限制每位作者每天最多只能發布三本書──這對日產千字的機器來說簡直是隔靴搔癢。不僅如此,雖然作者上傳書籍時要求勾選是否使用AI,但這提示卻一度刻意隱藏,根本沒有顯示給消費者看。
面對劣幣驅逐良幣生態,原生創作者被迫逃亡。因流量和版稅被成千上萬的AI垃圾書籍稀釋,作家Dakota Willink公開表示不得不退出Kindle Unlimited平台,轉而尋求Kobo Plus等其他更透明的海外管道。英國出版商協會也警告:如果放任這種低品質AI書氾濫,消費者的信任將徹底透支。
偷走人類語料,再把AI垃圾塞給你
這場cyber垃圾的狂歡背後,根本性的原罪始終無法迴避:能胡編亂造、模仿名家風格的大模型,究竟如何變得這麼「聰明」?答案很簡單:靠大量未經授權的網路爬蟲。
法庭文件揭露Meta訓練Llama 3時的幕後操作。大模型對高品質資料需求極大,Meta高層討論過購買正版授權,但結論是:流程極其緩慢,價格又高得不合理。工程總監於員工群組赤裸裸指出:「如果我們只授權一本書,那我們將無法以『合理使用』為由抗辯。」翻譯就是:只要我們抓取的資料夠龐大,法不責眾,就算技術創新。
於是取得高層默許後,Meta員工熟練地掛上匿名性極強的BitTorrent(BT種子),下載全球最大盜版數位圖書館Library Genesis(LibGen),足足有750萬本書和8,100萬篇論文。巨頭無償使用人類才華與思想,然後AI用戶將AI書再塞給社會。
誠然,如果我們只看冰冷數據,這場AI海嘯似乎還是能賺進某種短期紅利。AI流水線開始接管文字生產,名為Spines的新創出版商因2024年拿到1,600萬美元融資,預定花一年用AI全自動出版8,000本書,從校對到排版只需三週。
NBER(美國國家經濟研究局)論文也佐證這種「繁榮」:儘管AI導致圖書平均品質斷崖式下跌,但由於供給基數龐大,市面「中等偏上」品質書籍絕對數量增加,讀者的「消費者剩餘」提高約7%。部分老牌作家在AI輔助下,生產力也超級強化。這似乎印證投資人Marc Andreessen預測:糟糕內容氾濫會伴隨高品質內容爆發。
但這真的會讓出版社開出第二春嗎?
這種繁榮假象代價非常慘痛:一方面,海量AI垃圾無限稀釋真實作品的曝光率,讓許多沒名氣的作家存活空間更壓縮;另一方面,內容源頭的出版商和創作者被大模型無情「吸血」,失去賴以維生的商業回報。
面對迫在眉睫的生存威脅,Dennis Lehane等70多位知名作家聯合向美國出版界「五大巨頭」請願,要求停止上市AI創作書籍;由於大模型直接搜尋端抓取總結內容,Google AI摘要功能(AI Overviews)導致部分出版商外部網站流量暴跌超過34%,原生內容生存土壤也徹底掏空。
更致命的是,這種竭澤而漁玩法,最終就是技術層面不可逆轉的反噬作用。
電腦科學界有句至理名言「Garbage in, garbage out」(垃圾進,垃圾出),大語言模型想變更聰明,必須投餵高品質的人類資料。但過去兩年,由於巨頭縱容,亞馬遜和整個網路都被大量AI垃圾塞滿了。

(Source:Unsplash)
這下尷尬了。當OpenAI或Google派出新爬蟲抓取新訓練資料時,它們會抓到什麼?是連「重新產生答案」都沒刪的羅曼史小說;是錯把橄欖球當足球的名人傳記;還是27歲年輕人真有機會一鍵產生的1,500本水貨。
宛如吞食自己尾巴的「銜尾蛇」(Ouroboros), AI曾經吞下人類文明的經典,現在卻都在吃自己和同類的數位廢物。不用多久模型就會退化,就是學術界一直擔心的「模型崩潰」。
所以我們到底為什麼要閱讀?
阿根廷作家博赫斯小說構思過一座無限龐大的「通天塔圖書館」,收錄了所有可能的字母組合,書本數量浩如煙海。但遺憾的是,多數書籍都是毫無意義的亂碼,真正蘊含真理和情感的文字,永遠被冗餘訊息的汪洋淹沒。
不知疲倦的生成式AI,正在為我們建造現實版的通天塔圖書館。當電子書架被每月30萬本流水線垃圾填滿,當整個行業不得不面對「垃圾進,垃圾出」困局時,我們或許該重新思考文字本身的意義。
英國作家CS路易斯曾說:「我們閱讀,是為了知道自己並不孤單。」書真正的重量在於,碰到另一群真實的人。他們也和你一樣,會痛、會笑、會迷茫、會心碎,他們把這些滾燙的生命體驗,笨拙又真誠地糅入文字,留給將來某個他們永遠不認識的人。
AI能幾秒鐘內產生100萬個結構精巧的故事,卻不會了解一滴眼淚的重量。文字可無限量產、廉價批發的時代,真正有溫度的作品卻愈發稀少,愈發珍貴。去讀書吧,讀真正有作者的書。





