



SanDisk 正押注一項更激進的儲存架構,試圖在人工智慧熱潮推升記憶體需求、卻也暴露供應瓶頸的背景下,為未來的高效能運算找出新解方。根據最新披露,該公司提出將 NAND 快閃記憶體直接堆疊在運算晶片下方的設計,讓資料存取不再完全依賴傳統的旁側(side-by-side)配置,藉此縮短傳輸距離、降低延遲,並減少成本與功耗。
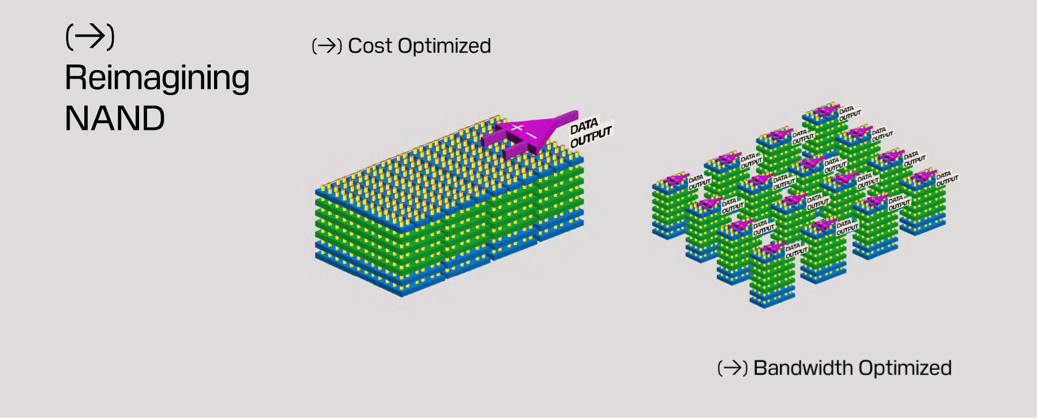
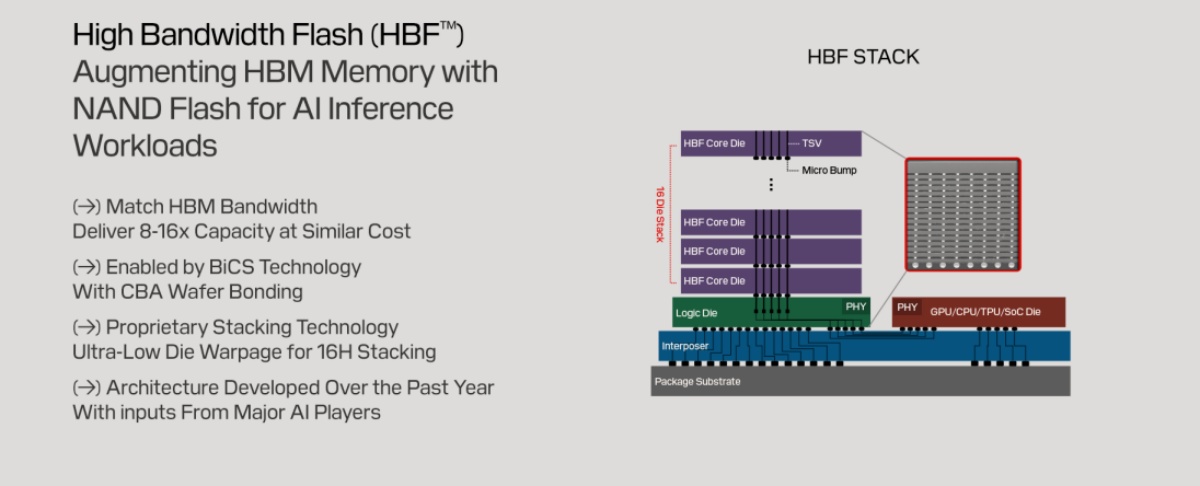
這項構想建立在 SanDisk 先前提出的 HBF(High-Bandwidth Flash)概念之上。HBF 採用類似 HBM 的分層堆疊方式,把多層 NAND 透過 TSV(Through-Silicon Via)互連整合成單一堆疊,容量可望從目前 HBM 每堆約 32 至 64 GB,進一步擴大到最高約 4 TB。然而,面對 AI 與 HPC 對容量、頻寬與延遲的更高要求,SanDisk 最新申請的專利(US 12,430,274 B2)則更進一步,探索把具備 CBA(CMOS Bonded Array)結構的 NAND 晶粒,直接堆疊在 AI 加速器或 GPU 之下,形成「運算在上、NAND 在下」的 3D 架構。
(Source:SanDisk)
在這套設計中,HBM DRAM 仍會配置在同一中介層(interposer)上,但分工不同:HBM 負責即時、低延遲的高優先順序記憶體工作,而 NAND 則承擔較大容量的讀寫與資料保存工作。SanDisk 希望藉由更寬的晶片間連結,改善 NAND 因距離較遠而速度落後於 DRAM 的弱點,同時回應 AI 運算對記憶體供應的持續擠壓。
(Source:SanDisk)
值得注意的是,這些構想目前仍停留在專利與技術路線階段,距離量產還有一段距離。功耗、製造成本,以及在單一封裝中同時整合 NAND 與 DRAM 的工程難度,都是必須先克服的問題。不過,在 AI 帶動 NAND 與企業級 SSD 需求持續升溫、供應偏緊的情況下,SanDisk 正試圖把儲存晶片從「被動支援」推向更接近運算核心的位置,搶先卡位下世代資料中心架構。
(首圖來源:pixabay)





