




隨著人工智慧(AI)運算需求的重心從一次性的訓練階段,慢慢轉向持續性且高頻發生的推論(Inference)階段。這場轉變不僅催生了專為 AI 推論設計的新晶片,更在記憶體與儲存領域,帶來一場以「總體擁有成本」(TCO)為核心的異構與分層架構革命。
就深度學習領域來說,其模型訓練(Training)與模型推論(Inference)是兩個截然不同的階段,兩者對圖形處理器(GPU)和記憶體的需求限制大相徑庭。
訓練需要極高的浮點運算能力與高頻寬記憶體
模型訓練是計算密集型任務,需要極高的浮點運算能力與高頻寬記憶體。因此,訓練是模型從數據中學習的過程,涉及反向傳播、大量的計算以及對數據集的多次遍歷。訓練工作負載必須儲存完整的模型參數,同時還需要大量的 GPU 記憶體(VRAM)來儲存用於反向傳播的中間激活值(activations)、每個參數的梯度,以及優化器狀態(例如 Adam 的一階、二階動量)。
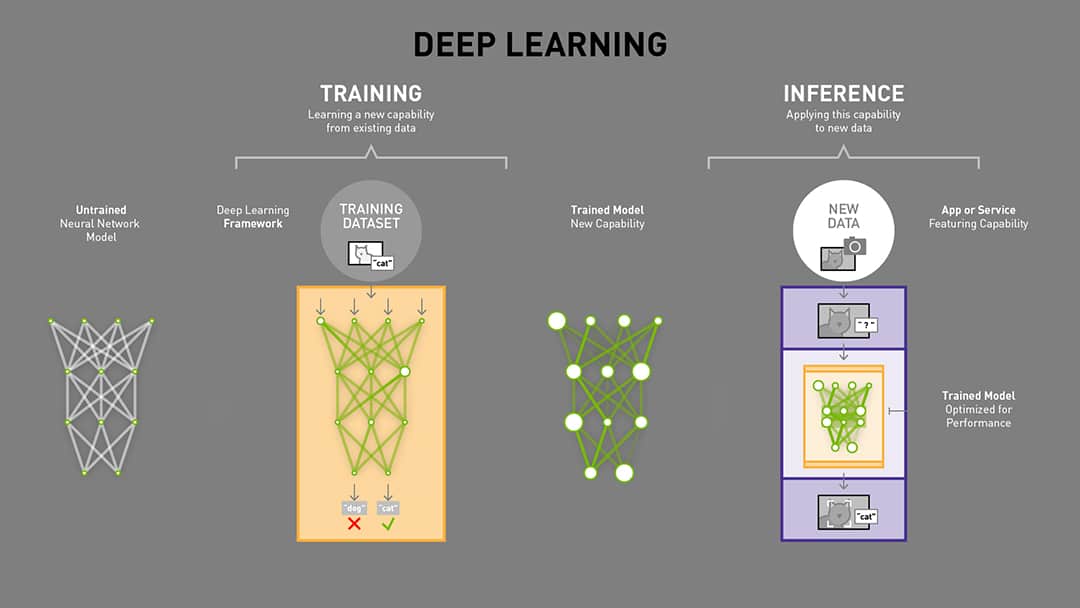
基於以上的因素,訓練階段對記憶體的需求極為苛刻。模型大小通常要再乘上 3-6 倍的額外需求。舉例來說,一個擁有 10 億參數的模型(FP32 權重約 4 GB),加上梯度(4 GB)和優化器狀態(8 GB),以及激活值(4–16+ GB),總計可能需要約 20–30 GB 甚至更多的記憶體。訓練通常使用精度要求高的FP32或混合FP16/BF16,且需要極高頻寬(HBM,>1 TB/s),因為必須持續存取權重、激活值與梯度。記憶體量是限制最大批次大小與可訓練模型規模的主要因素。
推論長情境側重於快速存取大量模型參數
相較之下,模型推論階段,特別是長情境任務,雖然也需要龐大的記憶體頻寬,但更側重於快速存取大量模型參數。推論是按需求(on demand)、即時的,並且完全由使用者行為塑造,這使其不像訓練那樣是可預測、可重複的過程,反而更加混亂且難以優化。因此,每一次使用者與 AI 的互動(無論是詢問聊天機器人或生成圖像)都會觸發推論工作。推論工作負載不像訓練那樣直線運行,它們會迴環、優化和再處理。每一次互動都會觸發大量的讀取、寫入和查找操作,這些每秒輸入/輸出操作(IOPS) 迅速累積,對基礎設施構成指數級的壓力。

事實上,「推論等同於 IOPS」(Inference = IOPS)是業界對此現象的精準描述。推論應用所驅動的併發 I/O,甚至可能比歷史上基於CPU的計算應用高出數百或數千倍。Meta 的首席 AI 科學家楊立昆(Yann LeCun)曾明確指出,AI 基礎設施的大部分成本用於推論,就為數十億人提供 AI 助理服務。這顯示出推論已成為 AI 基礎設施的真正瓶頸。
生成式 AI 進入多模態融合階段,從比較算力到總擁有成本
整體來說,AI 運算需求的轉變,源自於生成式 AI 進入多模態融合的新階段。AI 應用核心已從專注於文字的 LLM 擴展至聲音、視覺與動態的多模態內容,例如 OpenAI 發布的 Sora 等文字生成影片模型。AI 從影片生成走向可互動的 3D 世界,不僅是運算量的線性增加,更是一次運算邏輯的質變。無論是影片還是 3D 模型,其對硬體需求的嚴苛性都源於 Token 用量的指數級增長。當 AI 從純文字轉向多模態,每個影片畫格或 3D 場景所需的 Token 數量遠超文字,導致日均 Token 消耗量在短時間內暴增數十倍。這股推論需求爆炸正是迫使半導體產業必須優化產品線,轉向專為推論工作負載設計的解決方案的核心驅動力。
為應對推論浪潮,半導體大廠開始推出專門針對推論的解決方案,目的是從「算力競賽」轉向「總體擁有成本」(TCO)優化。NVIDIA 預計推出的 Rubin CPX 晶片,就是為處理長情境影片與程式碼任務而生的專用晶片。值得注意的是,Rubin CPX 採用成本效益更高的 GDDR7 記憶體,而非 HBM。GDDR7 在容量、頻寬與成本之間取得最佳平衡,適合對延遲容忍度較高的推論任務。

此外,推論階段可以透過技術手段降低記憶體壓力。推論只須儲存模型權重與暫存運算緩衝區,記憶體需求會受批次大小影響(batch 越大激活值越多)。推論可以採用量化(Quantization)技術,使用 INT8、FP8 甚至 4-bit 量化,來大幅減少記憶體占用與頻寬需求。例如,透過量化優化後,原本需要 16 位元的 70 億參數模型,可以壓縮到 4 位元並在 8GB GPU 上運行推論。這使得推論的記憶體使用效率遠高於訓練。
人工智慧需求市場發展衝擊記憶體解決方案挑戰與轉變
隨著 AI 模型規模日益龐大,現有的記憶體解決方案面臨挑戰。HBM 雖頻寬極高但容量有限、eSSD 雖容量巨大但頻寬與延遲不足。AI 推論對高 IOPS 的需求,使得儲存系統必須跟上運算的速度,否則再快的計算架構也將無濟於事。
企業級 SSD 的崛起與缺貨預警
在 AI 伺服器的數據處理中,對高 IOPS 的追求使得企業級固態硬碟(eSSD) 正加速取代傳統硬碟(HDD)。儘管 eSSD 單位成本較高,但隨著 QLC 技術進步,其每 GB 成本大幅降低,與 HDD 的價差縮小。eSSD 的存取速度遠高於 HDD。
雲端服務供應商正積極規劃在 2026 年大規模以 eSSD 取代 HDD,這將引發大容量 QLC SSD 需求量暴增,並可能在 2026 年出現「嚴重缺貨」。這標誌著 NAND 市場的增長引擎,正從傳統消費性產品轉向企業級儲存。
高頻寬快閃記憶體(HBF)的出現
為了解決 HBM 與 eSSD 之間的鴻溝,SanDisk 與 SK 海力士正合作推動高頻寬快閃記憶體(HBF)。HBF 的戰略定位是提供兼具高容量與高頻寬的解決方案,使其成為超大型 AI 模型推論的理想選擇。
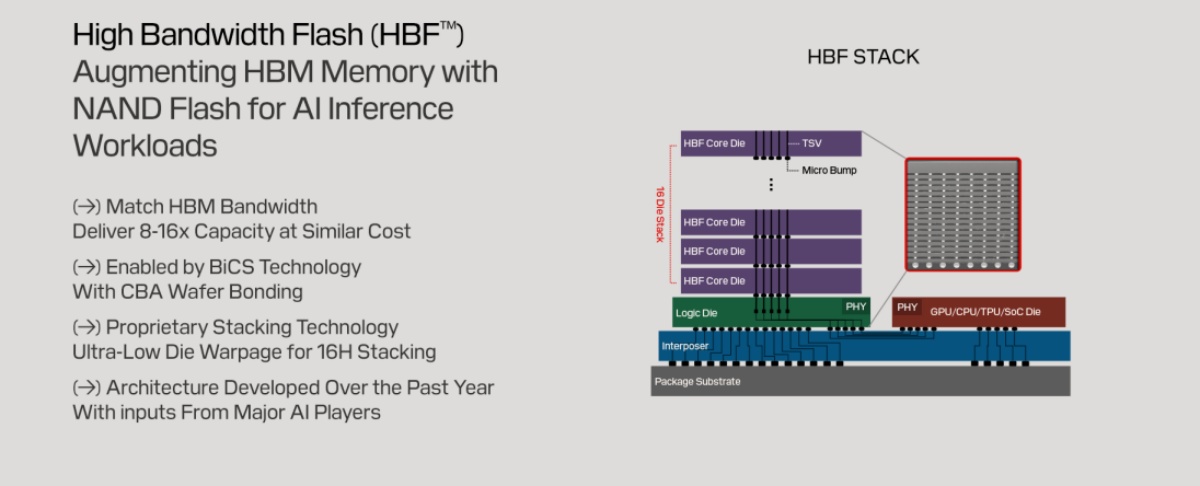
HBF 透過將 NAND 晶片進行 3D 堆疊,並透過矽穿孔(TSV)直接與 GPU 連接。HBF 的頻寬可望媲美 HBM,但容量卻是 HBM 的 8 至 16 倍。這項創新預示著 AI 記憶體架構正形成一個全新的三層級體系,包括 HBM 做為高速快取層,HBF 做為大容量模型儲存層,eSSD 則做為底層資料湖。
邊緣 AI 與 NOR Flash 的機會
AI 對記憶體的影響並非只局限於雲端資料中心。隨著 AI 技術從雲端推向 AI 耳機、AI 眼鏡和 AI PC 等終端設備,邊緣運算的重要性日益凸顯。在這些邊緣 AI 應用中,NOR Flash 成為關鍵元件。由於NOR Flash 的記憶體單元採並聯設計,使其具備優異的隨機存取能力和極快的讀取速度,並允許程式碼直接在晶片內執行(eXecute In Place,XiP)。這使其成為邊緣 AI 裝置中,用於儲存啟動碼、韌體和關鍵程式碼的理想選擇。
記憶體產業鏈的黃金時代與戰略布局
AI 推論需求的爆炸性成長,正以前所未有的速度吞噬記憶體產能,導致 DRAM 與 NAND 快閃記憶體市場供需失衡。
這股浪潮直接推升了 HBM 與 DDR5 的需求,並以「漣漪效應」擴散至整個產業。多家華爾街機構預測,在 AI 需求強勁支撐下,全球關鍵記憶體在 2026 年將面臨供不應求,DRAM 與 NAND 快閃記憶體的合約價格預計將在 2025 年與 2026 年持續上漲。企業級 SSD 的出貨成長也推升了整體 NAND 產業的營收。

而隨著 AI 帶動 HBM 需求激增,各家廠商正積極開發替代技術,以平衡性能、功耗與成本。首先三星宣布重啟 Z-NAND,並導入 GPU 直通存取(GIDS),使 GPU 可直接讀取儲存數據,消除 CPU/DRAM 瓶頸,提升 LLM 與 HPC 訓練效率。新一代 Z-NAND 性能將達傳統 NAND 的 15 倍,功耗降 80%,延續 2018 年 SZ985 Z-SSD 的技術基礎。
其次,NEO Semiconductor 則推出 X-HBM 架構,採用 3D X-DRAM,突破 HBM 頻寬與容量限制。其單晶片容量達 512Gbit、數據總線 32K-bit,頻寬與密度分別為現有技術的 16 倍與 10 倍,遠超預計 2030 年的 HBM5 及 2040 年的 HBM8。還有Saimemory 由軟銀、英特爾與東京大學成立,專注堆疊 DRAM,結合 Intel EMIB 技術,實現兩倍容量、功耗比 HBM 降低 40%~50%,成本亦更具優勢,計劃 2027 年完成原型,2030 年商業化,主打綠色運算。

最後是,SanDisk 與 SK 海力士則合作開發高頻寬快閃記憶體(HBF),結合 NAND 非揮發特性與 HBM 封裝,容量達 DRAM 型 HBM 的 8~16 倍,成本更低但延遲略增,預計 2026 年推出樣品、2027 年應用於 AI 推理設備。整體而言,這些方案各自強調頻寬突破、能效優化或成本降低,代表業界正多路探索 HBM 之外的 AI 記憶體新路徑。
未來,AI 記憶體的發展將圍繞分層儲存架構,一個由 HBM 做為高速快取層、HBF 做為大容量模型儲存層,以及 eSSD 做為底層資料湖所構成的新型體系正在形成。或者,透過新儲存產品與技術的發展,建構新的儲存架構。尤其,AI 推論對 IOPS 的極高要求,已將儲存系統提升至核心基礎設施的地位,這場計算與儲存的硬體革新才剛拉開序幕。能洞察並布局這場變革的企業,無疑將在 AI 新紀元中取得領先地位。
(首圖來源:shutterstock)





