



韓國浦項工科大學(POSTECH)研究團隊開發出一款穿戴式 AI 感測器,能透過偵測頸部與喉部周圍的細微肌肉變化,將「無聲說話」轉換為可聽見的語音,為失去聲音的患者與高噪音環境中的溝通開啟新可能。相關成果已發表於《Cyborg and Bionic Systems》。
這項技術的核心是一種名為「多軸應變映射感測器」的穿戴式裝置。它結合迷你攝影機、柔性矽膠層與參考標記點,可貼合或配戴於頸部,追蹤說話時皮膚與肌肉的極細微形變。研究團隊指出,相較於傳統主要依賴 EEG 或 EMG 的靜默語音系統,此做法更輕量,也更適合日常使用,且在重新配戴後仍可自動校正。
在辨識部分,系統結合卷積神經網路(CNN)與 Transformer 模型,解析應變圖樣並重建語音內容,再搭配使用者的聲音特徵進行語音合成。研究團隊以 5,186 筆樣本訓練模型,受試者為 6 名 23 至 32 歲的健康成人,詞彙範圍涵蓋 NATO 音標字母表的 26 個單字。結果顯示,分類準確率達 85.8%。在模型壓縮後,檔案大小從 12.4 MB 降至 3.6 MB,推論速度也由 0.018 秒縮短至 0.003 秒,準確率仍維持在 82%。
研究團隊也強調該裝置在高噪音情境中的表現。系統在約 90 分貝白噪音環境下,辨識效果與一般 60 分貝環境相近;研究同時指出,若配戴過鬆、使用者說話太大聲,或在走動、頭部上下擺動時,辨識率會下降,顯示後續仍需加強穩定性與抗動態干擾能力。
研究團隊表示,這項技術未來可望幫助因聲帶受損或喉部手術而失聲的患者,讓他們透過自身的肌肉動作重新「發聲」;同時也可能應用於工廠、建築工地、會議室或圖書館等不便開口的場景。研究人員並提到,接下來將持續擴大資料集、增加使用者與詞彙範圍,並改善運動干擾問題,以推進實際部署。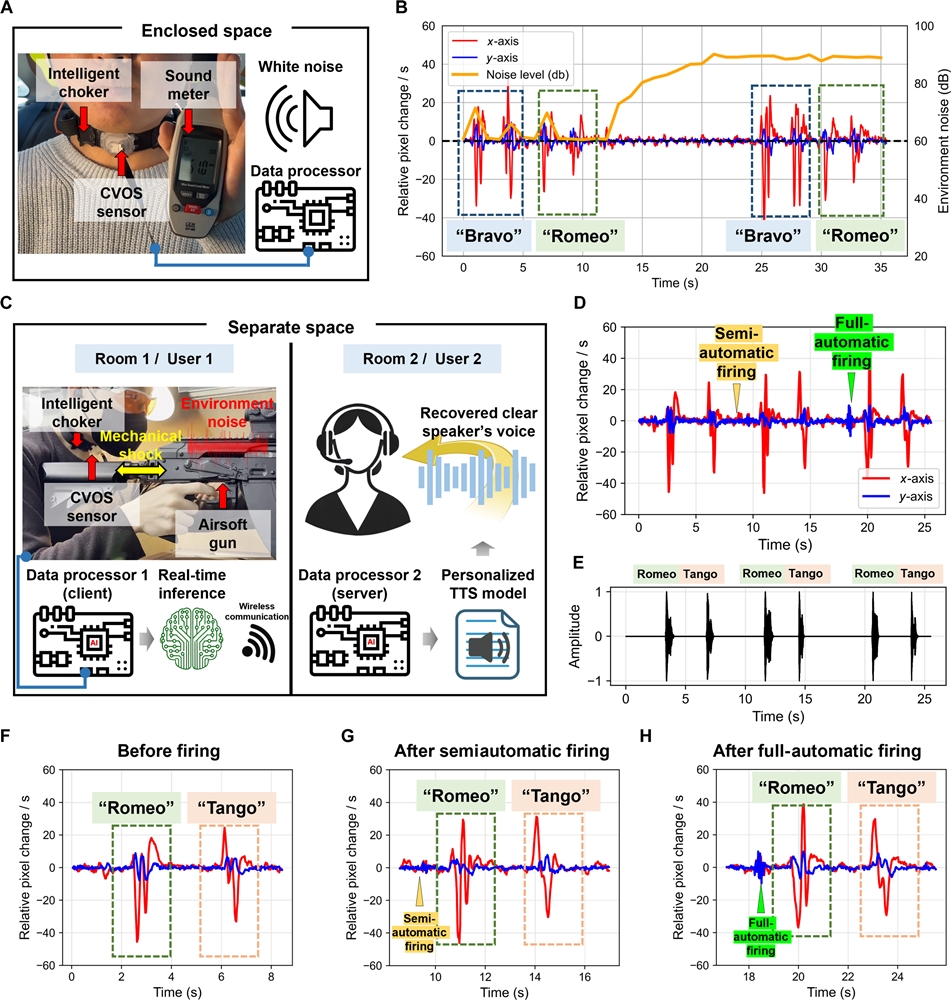
▲ 穿戴式 AI 感測器在環境雜訊與振動干擾下,仍維持穩定語音辨識效能之實驗結果與比較分析。(Source:Cyborg and Bionic Systems)
(首圖來源:pixabay)





