目前主流大型語言模型(LLM)深度學習 Transformer 架構,運算效能高度依賴記憶體存取。不只海量資料的訓練,權重參數與推論過程中的 KV 快取,都需在 token 生成階段反覆讀取。當處理器運算成長速度,明顯快於記憶體頻寬與資料傳輸能力時,使得大量時間並非花在運算本身,而是耗費在等待資料從記憶體載入。當系統效能受限於資料傳輸速度時,就形成典型的「記憶體牆」(Memory Wall)問題。
近年來 GPU 等 AI 晶片算力成長速度遠高於記憶體頻寬與資料傳輸效率,據《AI and Memory Wall》文內指出,AI 模型算力兩年增長 3 倍,但記憶體頻寬僅成長 1.6 倍、互連網路頻寬成長約 1.4 倍。多數運算實際上受制於記憶體存取與通訊效率瓶頸而非計算。
【產業洞察:記憶體牆困局:AI 算力競逐引爆全球記憶體超級循環】
算力成長速度是記憶體的兩倍,我們是否正撞向一道無法跨越的「記憶體墻」?
傳輸瓶頸: 兩年來,算力增 3 倍但頻寬僅增 1.6 倍,效能受限於資料載入延遲
記憶體超級循環: HBM、DDR5 產能排擠引發連鎖效應,消費電子面臨缺貨漲價衝擊
—— —— —— —— —— —— —— —— —— —— —— —— ——
以下內容節錄自 TrendForce 集邦科技專欄,完整深度分析請參考 原文➜
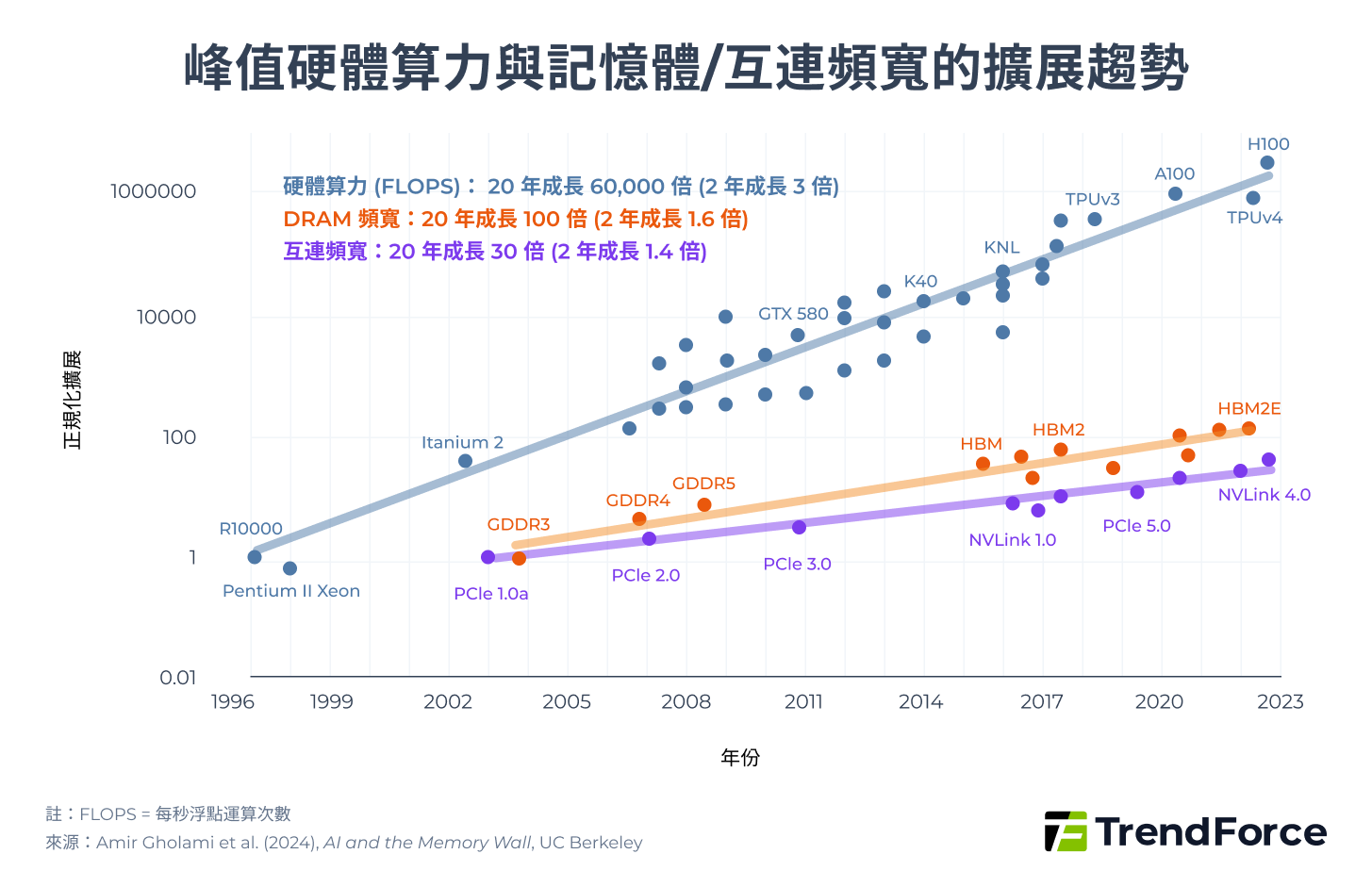
▲ 峰值硬體算力與記憶體/互連頻寬的擴展趨勢
從理論模型角度來看,這樣的結構性失衡可透過 Roofline Model(屋頂線模型)來解釋。深度學習模型本質上由大量矩陣乘法組成,通常用浮點運算次數(FLOPs,Floating Point Operations)來計算總運算量。
Roofline Model 是用來計算理論可達效能的框架,公式如下:
P = min(π, β × I)
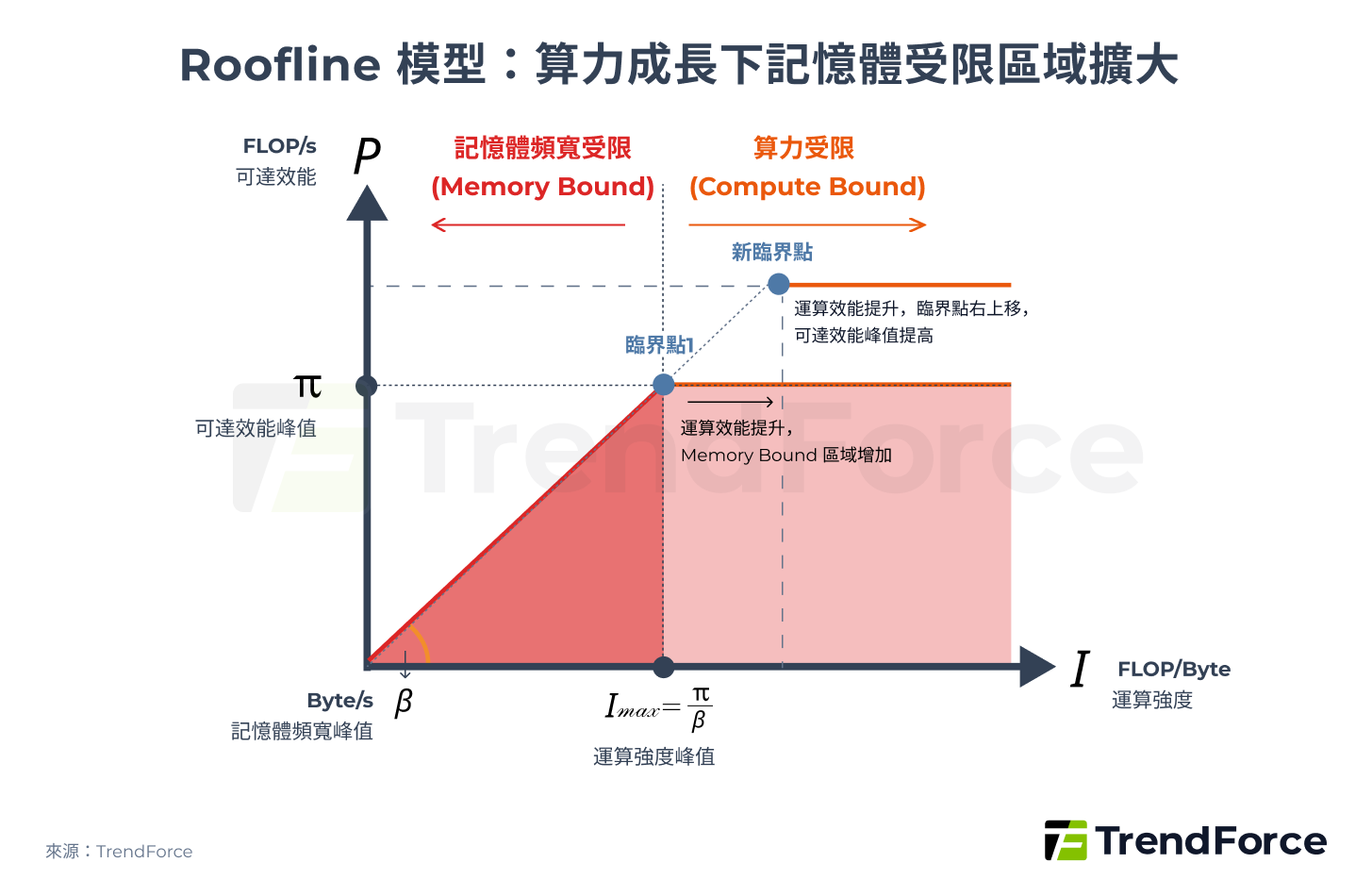
▲ Roofline Model:算力成長下記憶體受限區域擴大
模型指出系統效能同時受限於可達效能峰值(π)與記憶體頻寬峰值(β),而兩者的臨界點代表達到最高效能所需的最小運算強度。
當 AI 晶片算力持續提升(π 上升),若記憶體頻寬斜率未同步提升(β 不變),臨界點會向右上移動,使得更多運算工作負載落入 Memory-Bound 區域。換言之,算力的持續增長,反而加劇了記憶體對可達效能的限制。這正是為何在 AI 時代,AI 巨頭們競逐焦點從單純 FLOPs 算力的提升,轉向記憶體的軍備競賽。
AI 巨頭的規格軍備競賽,引爆 HBM 需求巨浪
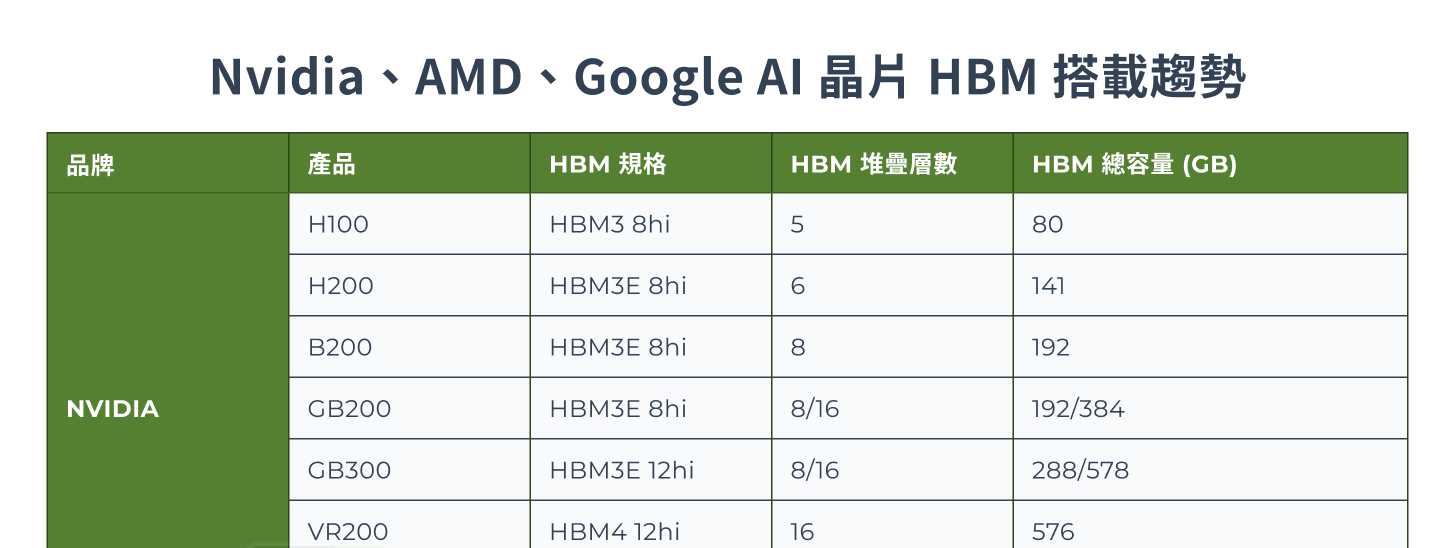
HBM 逐代發展,除了在性能、I/O 數量與頻寬有顯著提升,同時也成為各家 AI 加速器規格升級的核心。近幾年,NVIDIA、AMD 與 Google AI 晶片持續往最新 HBM 世代推進,個別晶片搭載的 HBM 顆數、記憶體容量也明顯提升,拉動 HBM 需求。
TrendForce 以 2025 年 AI 晶片出貨量推估,HBM 需求量年增達 130% 以上;預計 2026 年 HBM 消耗量將持續增加,年成長仍有 70% 以上,主要驅動力包括 B300、GB300、R100/R200、VR100/VR200 的滲透,加上 Google TPU、AWS Trainium 皆積極推進至 HBM3e 世代。