




輝達(NVIDIA)研究人員提出一種新技術,可大幅降低大型語言模型在追蹤對話歷史時所需的記憶體,最高可達 20 倍,且不需修改模型本身。外界期待,隨著記憶體用量大幅下降,是否意味著有望降低對記憶體的依賴。
這種方法稱為「KV 快取轉換編碼」(KV Cache Transform Coding,簡稱 KVTC),該方法借鑑了類似 JPEG 等媒體壓縮格式的概念,用於壓縮多輪對話 AI 系統背後的 KV 快取(KV Cache),從而降低 GPU 記憶體需求,並將首次 Token 的生成時間(time-to-first-token)加速最多 8 倍。
這對於依賴代理(agents)與長上下文的企業級 AI 應用來說,有助於降低 GPU 記憶體成本、更有效重複使用提示(prompt),並透過避免重新計算已丟棄的 KV 快取,將延遲降低最多 8 倍。
以後常考這題!KV 快取到底是什麼、K 和 V 又代表什麼?
KV 快取是 AI 模型的「短期記憶」。它能讓模型記住之前的問題中已經處理過的內容,當用戶重啟之前的討論或提出新問題時,系統會依賴既有記憶回答,避免從頭重新計算整段對話歷史。
簡單來說,到了 AI 推論階段時,會用到一種類似人腦的「注意力機制」,包括記住查詢中重要的部分(Key)以及上下文中重要部分(Value),以便回答提示。
如果每處理一個新的 Token,模型必須針對先前處理過的所有 Token 重新計算每個詞的重要性(Key 與 Value),來更新注意力權重,但這樣的做法如同學生每讀一個新句子都要重新回顧整篇文章,過程會相當耗時。
因此大語言模型加入了一種稱為「KV 快取」的機制,能將先前的重要資訊(Key 與 Value)儲存在記憶體中,免去每次重新計算的成本,從而將 Token 處理與生成速度提升數個數量級。
若以剛剛學生讀句子為例,KV 快取類似「筆記」的概念,能將重要資訊記錄下來,當有新的 Token 時,不需要再重新回顧,直接從筆記裡的資訊即可計算新的注意力權重。
KV 快取目前遇到什麼問題?為何反而成為記憶體瓶頸?
然而,這種記憶體需求會迅速膨脹,進而成為延遲與基礎設施成本的主要瓶頸。
NVIDIA 資深深度學習工程師 Konrad Staniszewski、Adrian Lancucki 在論文中指出,過時的快取會佔用寶貴的 GPU 記憶體,迫使系統將其卸載到其他儲存層,或重新進行計算。因此,它們提出輕量級的轉換編碼器 KVTC 的概念,可對 KV 快取進行壓縮,以便在 GPU 內與 GPU 外都能以更精簡的方式儲存。
根據外媒 VentureBeat 的說法,KV 快取會儲存對話中每個 Token 的隱含數值表示。然而,在長上下文任務中,這個快取很容易膨脹到數 GB 規模,隨著模型規模擴大並生成更長的推理鏈,KV 快取逐漸成為影響系統吞吐量與延遲的關鍵瓶頸。
這也給生產環境帶來嚴峻挑戰。該報導也提出一個重點:由於 LLM 在推論時高度受限於記憶體,能同時服務的用戶數量往往受 GPU 記憶體限制,而非運算能力,因此如何釋出記憶體空間,變得相當重要。
NVIDIA 資深深度學習工程師 Adrian Lancucki 向 VentureBeat 表示,如何有效管理 KV 快取變得非常重要,因為閒置的快取須快速從 GPU 記憶體卸載,以騰出空間給其他使用者,並在對話恢復時迅速載回。這些基礎設施成本如今也反映在商業定價中,並針對快取服務收取額外費用(如「提示詞快取」,prompt caching)。
小知識:提示詞快取(Prompt Caching)
為了讓大語言模型依指示產生正確回應,使用者會進行提示工程,在提示詞中加入大量資訊,使提示詞往往會多達上千字甚至上萬字,不但費用增加,也減慢大語言模型的回應時間。
「提示詞快取」是將先前處理過的提示詞及其結果儲存,當再次遇到相同提示詞時,便可直接從快取中取得結果,無需再次傳遞給大語言模型運算。
(資料來源:國立台灣大學計資中心電子報;作者:周秉誼)
即使是選擇將快取卸載到較低階儲存(如 CPU 記憶體或 SSD)等折衷方案,也會帶來顯著的資料傳輸開銷,導致網路頻寬飽和並形成新的瓶頸。
為了降低記憶體占用問題,最常見的解法是壓縮 KV 快取。不過,有一些針對網路傳輸設計的壓縮工具壓縮率有限;其他壓縮方法則需要在每次使用者輸入時進行高資源消耗的即時計算。此外,量化(quantization)或稀疏化(sparsification)等主流技術,可能導致延遲與準確度下降,或需修改模型權重,這降低了其實用性。
NVIDIA 研究人員發表新技術,靠 KVTC 將 LLM 記憶體用量縮減 20 倍
論文指出,過去文獻提到許多探討 KV 快取壓縮方法,如 KV 快取可以量化、稀疏化、可被壓縮等,甚至可在不同層之間共享。這些方法在長上下文任務中,能透過減少 KV 快取大小,降低下一個 Token 預測過程中的記憶體傳輸量,從而顯著提升吞吐量與降低延遲。但因系統對延遲要求很高,又要避免改動模型權重,這些技術通常比較脆弱,且準確率也會下降,使得多種方法一起使用時難以取得更好的效果。
NVIDIA 研究人員也認為,現有方法「很少利用 KV 張量的強烈的『低秩結構』(low-rank structure)」。
小知識:低秩結構(low-rank structure)
「低秩結構」是指用來描述一個矩陣或張量(tensor)中,數據其實可以用比原始維度少得多的「主要成分」來近似表示的特性。
以最直覺方式來理解,如果有張很大的照片,裡面大部分顏色和圖案都重複,這時不需要存每個像素的資訊,只要存主要顏色和形狀就能重建整張圖。
這也意味著,雖然 KV 快取具有高維度、體積龐大(達數 GB),但底層資訊高度相關,可用更少的變數、更精簡的方式來精確表示。而 KVTC 的核心,就是利用這一特性來達成高效壓縮。
從 JPEG 等媒體壓縮技術邏輯,來壓縮 KV 快取
研究人員指出,KVTC 是一種簡單但強大的轉換程式碼(Transform Code)方案,主要受傳統 JPEG 影像與影片壓縮格式所啟發,來解決 AI 記憶體瓶頸問題。該框架透過一系列快速的多步驟流程,在推論階段之間縮小快取體積,以避免拖慢實際的 Token 生成速度。
Adrian Lancucki 表示,這種「媒體壓縮」方法為非侵入式,不需修改模型權重或程式碼,且運作位置接近資料傳輸層,有利於企業部署。
根據論文介紹,KVTC 轉換程式碼流程主要結合「主成分分析」的特徵去相關(decorrelation)、自適應量化(adaptive quantization)以及熵編碼(entropy coding)。
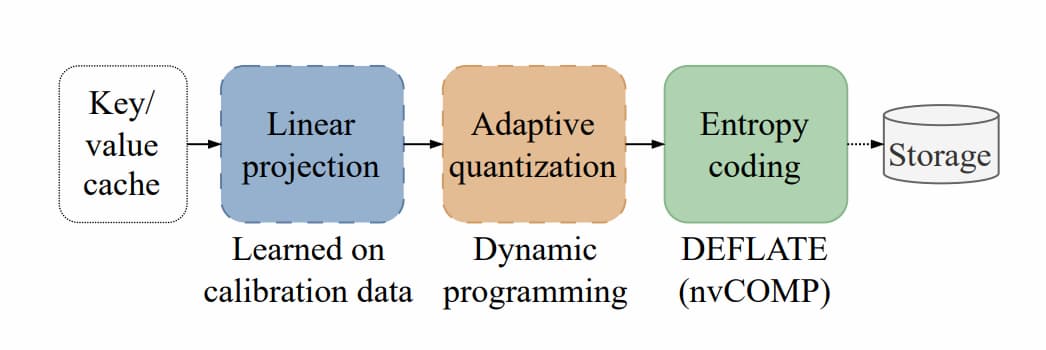
首先,KVTC 使用「主成分分析」,根據重要性對 KV 快取的特徵進行對齊。這個步驟只需在每個模型的初始校準階段執行一次,由於 PCA 對齊矩陣是在離線狀態下計算並重複使用,因此不會拖慢針對個別使用者提示在推論階段的壓縮過程。
小知識:主成分分析(Principal Component Analysis,簡稱 PCA)
PCA 是機器學習中常見的統計技術,是一種分析資料、降低數據維度以及去關聯的線性降維方法。簡單來說,是在複雜數據中,找到幾個最關鍵指標(主成分)來代表原本的全部數據,同時盡量不丟失重要的資訊。
接著,到了「自適應量化」這個流程,系統使用「動態規畫」(dynamic programming)演算法,自動為每個資料維度分配實際所需的記憶體量。最關鍵的主成分會分配較高精度,次要的主成份則分配較少位元、甚至可能完全捨棄。
如此一來,透過該演算法可找到一個「最佳配置」,在有限記憶體下保留最多資訊。
小知識:自適應量化(Adaptive Quantization)
這是一種在資料壓縮或模型加速中常用的技術,根據資料的重要性或特性,自動調整每個數值使用的位元數來進行量化。
小知識:動態規畫(dynamic programming)
將複雜的大問題拆成許多相對簡單的小問題,先計算並記錄每個小問題的結果,找到其中的規律,再利用這些結果組合出大問題的答案,避免重複計算。
最後在「熵編碼法」步驟中,量化後的數值會被打包成單一的位元組陣列,並透過名為「DEFLATE」演算法進行壓縮。研究人員強調,在這步驟中,關鍵是利用了 NVIDIA 的高速資料壓縮和解壓縮庫 nvCOMP,這可以直接在 GPU 上並行運作,因此運行速度非常快。
當使用者回到對話時,KVTC 只需將上述流程反向執行(即熵解碼 → 反量化 → 逆 PCA),即可完成解壓縮。為了加速過程,系統會以分塊(chunk)與逐層(layer-by-layer)的方式進行解壓,讓 AI 模型可以在第一批資料解壓後就開始計算下一個回應,同時在背景持續解壓後續資料。
壓縮率提高 20 倍,精確度損失低於 1%
NVIDIA 研究人員在多種模型上測試 KVTC,參數量涵蓋從 15 億到 700 億,包括 Llama 3 系列、Mistral NeMo,以及以推理能力見長的 R1-Qwen 2.5 模型;同時使用 AIME25、GSM8K、LiveCodeBench、LongBench、MATH-500、MMLU、Qasper 與 RULER 等多種基準來測試 KVTC。
結果顯示,KVTC 始終優於推論時的標準方法,如 Token Eviction、量化(quantization)與基於 SVD 的方法,且壓縮比更高。論文指出,這些結果支持 KVTC 作為具備可重複使用 KV 快取的記憶體高效 LLM 服務的實用基礎模組。
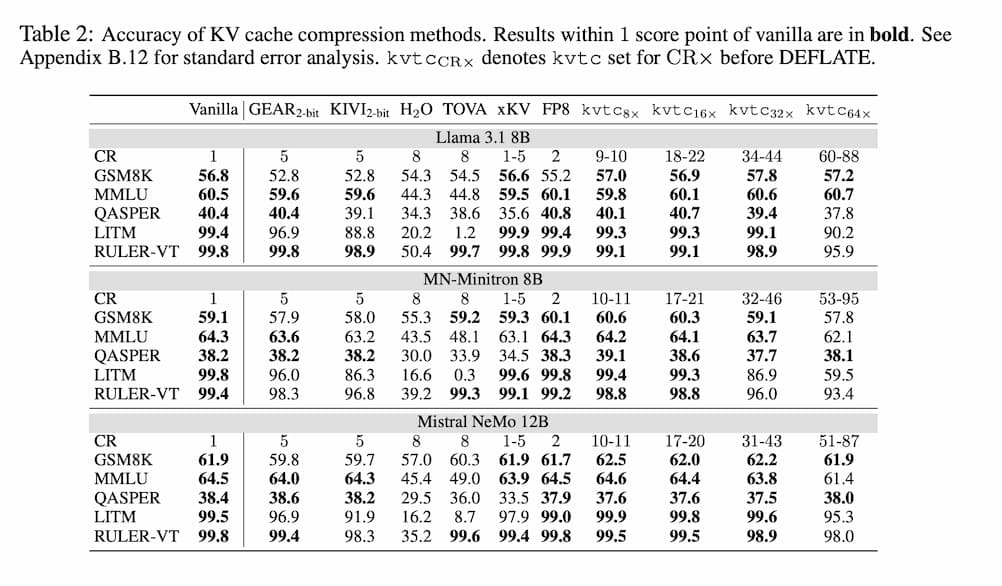
當壓縮比達到約 20 倍時,KVTC 在大多數任務中,準確率損失始終保持在 1 個百分點以內,幾乎維持與原始未壓縮模型相同的表現。即使將壓縮推至極端的 32 倍與 64 倍,KVTC 仍展現出相當穩定的性能。
相比之下,當採用 KIVI 與 GEAR 等主流方法時,在僅約 5 倍壓縮時,特別是在長上下文任務中,就出現顯著的準確率下降。而像 H2O、TOVA 這類 Token Eviction 的方法作為通用壓縮方案,則在需要檢索深層上下文資訊時幾乎失效。
以 Qwen 2.5 1.5B 這種較小型的推理模型為例,在一般情況下,該模型每處理一個 Token 約需 29KB 記憶體;相較之下,Llama 3.1 8B 約為每個 Token 131 KB;經過 9 倍壓縮後,其大小可縮減至每個 Token 3.2KB。

對企業架構師而言,是否導入這項技術高度取決於使用場景。Lancucki 指出,KVTC 是針對長上下文、多輪互動場景最佳化的,像是程式設計助理、迭代式代理(agentic)推理流程,以及迭代式 RAG(檢索增強生成)都是理想應用場景。然而,在短對話中應避免使用 KVTC,因為在較短的互動中,未壓縮的最新 Token 會佔據主要比例,難以達到有意義的壓縮效果。
KVTC 具有高度可移植性,NVIDIA 考慮即將整合進 Dynamo 框架內的 KV Block Manager(KVBM),使其能與主流開源推論引擎(如 vLLM)相容。
根據 VentureBeat 報導,在使用者體驗方面,KVTC 最關鍵的提升在於顯著縮短首個 Token 生成時間(TTFT),即從送出提示到模型產生第一個回應 token 的延遲。以一個 8,000 Token 的提示為例,在 H100 上運行 120 億參數標準模型,若從頭重新計算歷史,大約需要 3 秒;而使用 KVTC,系統僅需約 380 毫秒即可完成快取解壓,將首 Token 生成時間縮短最多達 8 倍。
隨著模型逐步擴展至支援數百萬甚至上百萬 Token 的上下文視窗,對高效記憶體管理的需求只會持續增加。Lancucki 認為,考量到不同模型架構中 KV 快取的結構相似性與重複模式,未來很可能會出現專門且標準化的壓縮層,這意味著如同今日串流媒體中的影片壓縮一樣。
- KV CACHE TRANSFORM CODING FOR COMPACT STORAGE IN LLM INFERENCE
- Nvidia says it can shrink LLM memory 20x without changing model weights
- 國立台灣大學計資中心電子報
(首圖來源:Unsplash)





