



在人工智慧(AI)、機器學習的推動下,全球資料流量正以倍數成長,目前資料中心伺服器與交換機之間的連線正從 200G、400G 快速邁向 800G、1.6T,甚至可能到達 3.2T 的時代。
市場調研機構 TrendForce 預期,2023 年 400G 以上的光收發模組全球出貨量為 640 萬個,2024 年約 2,040 萬個,預期至 2025 年將超過 3,190 萬個,年增率達 56.5%。其中,AI 伺服器的需求持續推升 800G 及 1.6T 的成長,而傳統伺服器也隨著規格升級,帶動 400G 光收發模組的需求。
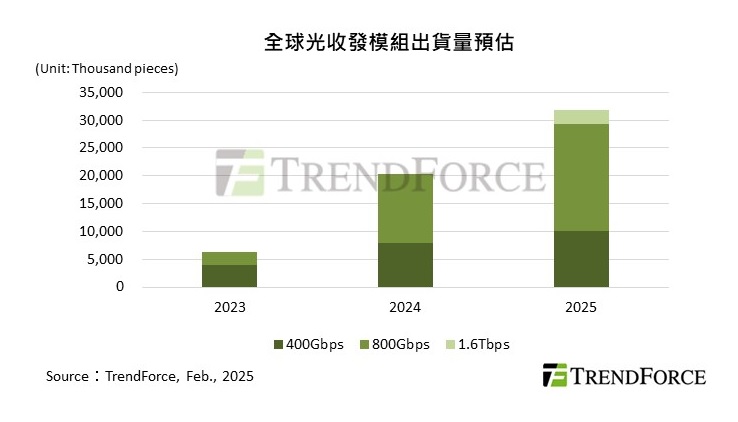
另據法人調查,2026 年 1.6T 光模組需求將大幅超出預期,總出貨量預期高達 1,100 萬支,主要動能來自 NVIDIA 與 Google 的強勁拉貨,以及 Meta、微軟、AWS 的部分占比。
光通訊因為高頻寬、低損耗與長距離特性,逐漸成為機櫃內外互連間的主要選擇方案,使得光收發模組成為資料中心互連的關鍵。TrendForce 指出,未來 AI 伺服器之間的資料傳輸,都需要大量的高速光收發模組,這些模組負責將電訊號轉換為光訊號,並透過光纖傳輸,以及將接收到的光訊號轉換回電訊號。
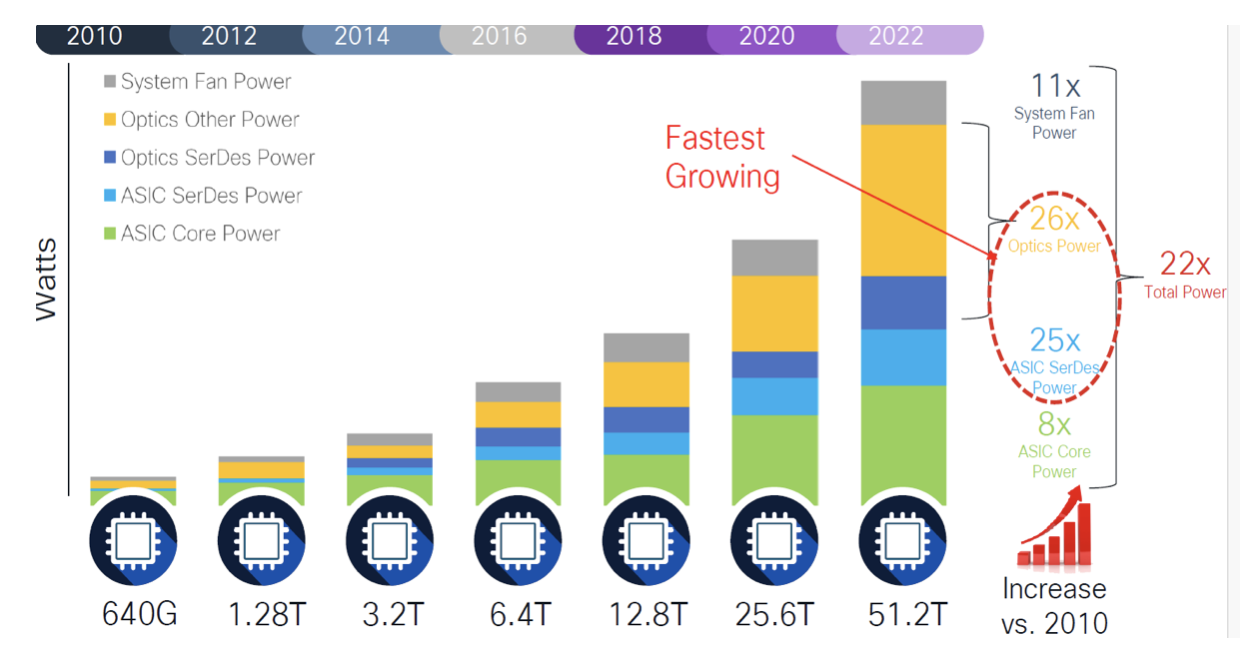
(Source:思科)
光收發模組、光通訊和矽光子有何關係?
根據下圖的前兩個示意圖可知,目前市面上的可插拔光收發器傳輸速率可達 800G,下一階段的光引擎(Optical Engine,簡稱 OE) 已經可安裝在 ASIC 晶片封裝周圍,這稱為載板光學封裝(On-Board Optics,簡稱 OBO),其傳輸能力可支援至 1.6T。
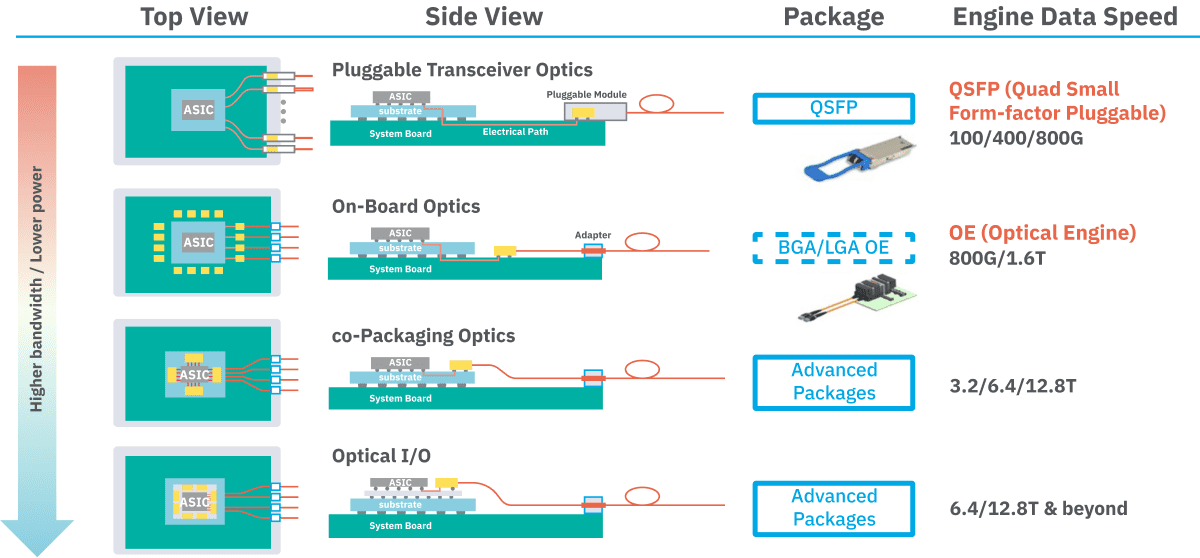
(Source:日月光)
目前業界希望走向「CPO」(Co-packaged Optics,共封裝光學),即光學元件與 ASIC 能共同封裝,透過這項技術實現超過 3.2T、最高達 12.8T 的傳輸速度;而最終目標則是達到「Optical I/O」(光學 I/O),實現類似全光網路的技術,推動傳輸速度超過 12.8T。
如果仔細觀察上圖,可以發現做為黃色方塊的光通訊模組(以前為可插拔型態)距離 ASIC 越來越近,這主要是為了縮短電訊號的傳輸路徑,從而實現更高的頻寬。而矽光子製程技術,就是將光學元件整合到晶片上的技術。

(Source:日月光)
光通訊需求暴增,業界聚焦三種擴展伺服器架構
由於 AI 應用大爆發,對於高速光通訊的需求急遽提升,目前伺服器主要聚焦 Scale Up(垂直擴展)、Scale Out(水平擴展)兩種擴展方向,分別對應不同的傳輸需求與技術挑戰,而近期 NVIDIA 又新宣布「Scale Across」這個概念,為業界增添一個思考方向。
Scale-Up
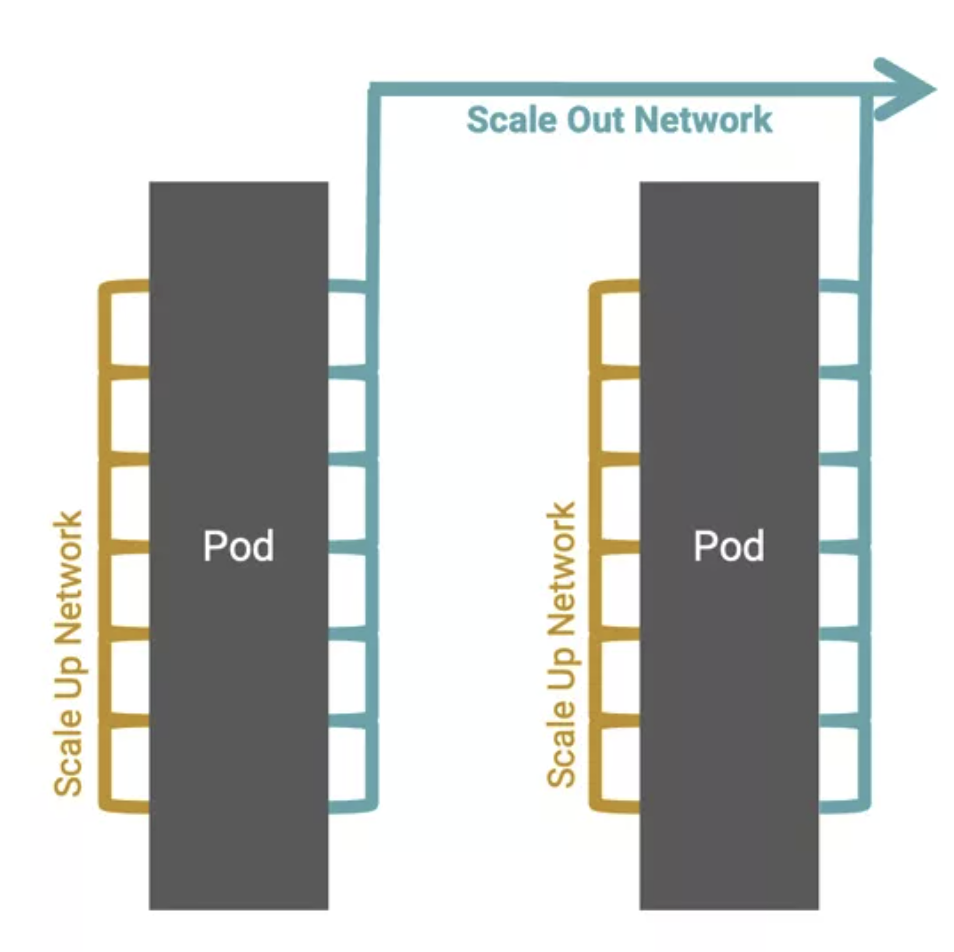
(Source:新思科技)
Scale-Up 主要做為機櫃內高速互連(上圖黃色部分),傳輸距離通常在 10 公尺以內,由於對延遲的要求極低,內部仍主要以「銅互連」(Copper Interconnects),避免光電轉換造成延遲與能耗。目前解決方案主要以 NVIDIA 的 NVLink(封閉架構)及 AMD 及其他公司主導的 UALink(開放架構)。
有趣的是,今年 NVIDIA 推出 NVLink Fusion,首度開放 NVLink 技術給外部晶片廠商,將 NVLink 從單一伺服器節點延伸至整個機櫃級(Rack-Scale)架構,不排除是為了因應 UALink 的競爭。
另個值得關注的是,原本主要專注在 Scale-Out 的博通,正嘗試透過「乙太網路」(Ethernet)進軍 Scale-Up 市場。該公司近期推出多款可用來 Scale-Up、符合 SUE(Scale-Up Ethernet)標準的晶片,而這部分可以往後看後續的 NVIDIA 與博通的競爭。
Scale-Out
Scale-Out 則是橫跨伺服器的大規模平行運算(上圖中藍色部分),為了解決資料高吞吐量,並實現無限擴充。這是以「光通訊」為主,主要的網路互連技術需要靠 InfiniBand 或者乙太網路(Ethernet),也將帶動光通訊模組市場。
InfiniBand 和 Ethernet 又可以分成兩大陣營,前者較受 NVIDIA、微軟等大廠的青睞,而後者則以博通、Google、AWS 為主。

談到 InfiniBand,不得不提領導廠商 Mellanox,他在 2019 年被 NVIDIA 收購,主要是提供端到端 Ethernet 與 InfiniBand 智慧互連解決方案供應商。而中國近期裁定 NVIDIA 違反反壟斷法,就是針對這起收購案。另個關注點是,雖然 NVIDIA 推出許多 InfiniBand 產品,但也針對乙太網路推出相關產品如 NVIDIA Spectrum-X,可以說是兩種市場兼吃。
做為另一大陣營,包括英特爾、AMD、博通等大廠則於 2023 年 7 月集結組成「超乙太網路聯盟」(Ultra Ethernet Consortium,簡稱 UEC),合作發展改進的乙太網路傳輸堆架構,成為挑戰 InfiniBand 的力量之一。
TrendForce 分析師儲于超認為,Scale Out 所帶動的光通訊模組市場,正是未來數據傳輸的核心戰場。
Scale-Across

(Source:NVIDIA)
做為新興的解決方案,NVIDIA 近期提出「Scale-Across」的概念,即跨資料中心的「遠距連接」,距離能超過數公里以上,並推出以乙太網路為基礎、串接多座資料中心的 Spectrum-XGS 乙太網路。
Spectrum-XGS 乙太網路將做為 AI 運算是 Scale-Up 和 Scale-Out 以外的第三大支柱,主要用來擴展 Spectrum-X 乙太網路的極致效能與規模,可連接多個分散式資料中心。NVIDIA 介紹,NVIDIA Spectrum-X 乙太網路除了提供 Scale-Out 的架構,連結整個叢集、將多個分散式資料中心進行互連,快速將大量資料集串流至 AI 模型,還可在資料中心內協調 GPU 與 GPU 之間的通訊。
換言之,這個解決方案結合 Scale-Out 與跨域擴展,能根據跨域距離靈活調整負載平衡、動態調整演算法,因此概念更類似「Scale-Across」。
NVIDIA 創辦人暨執行長黃仁勳表示,「我們在 Scale-Up 與 Scale-Out 能力之上,進一步加入 Scale-Across,把跨城市、跨國家乃至跨洲際的資料中心連結起來,打造龐大的超級 AI 工廠。」
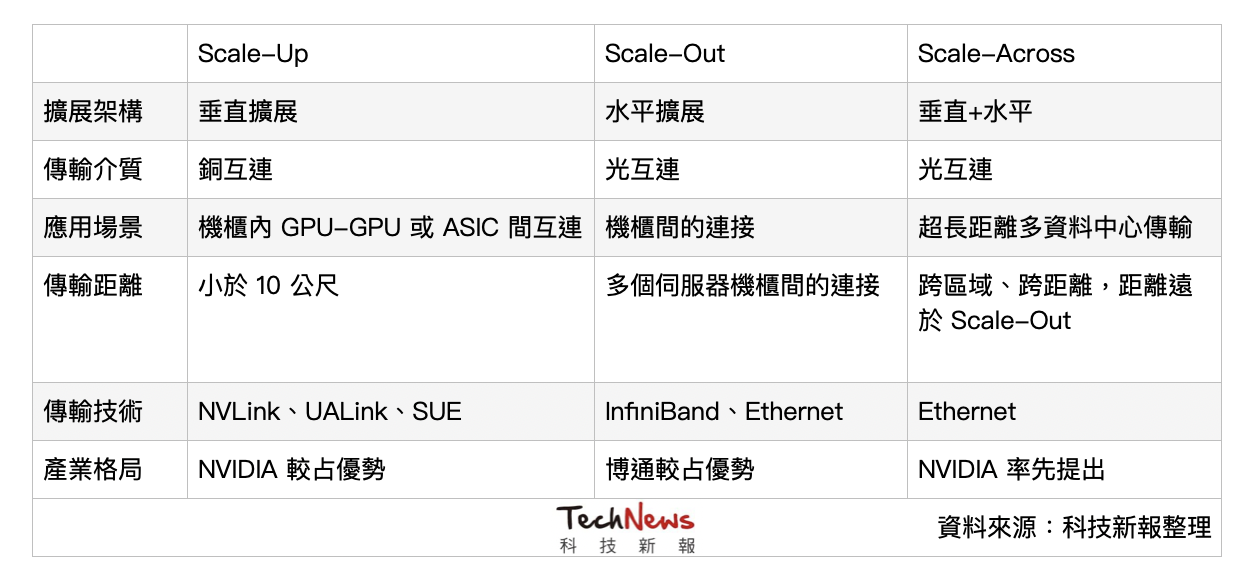
如果從目前產業走向來看,Scale-Up 和 Scale-Out 都是必爭之地,可以看出 NVIDIA 和博通如何從對方手中奪取多一分領地。而 NVIDIA 新喊出的 Scale-Across 則是聚焦橫跨數公里乃至於數千公里的跨資料中心傳輸,有趣的是,博通也有推出相關的解決方案,詳情請見下一篇:《AI 晶片傳輸到 CPO 卡位戰:NVIDIA、博通到底在競爭什麼?(下)》
(首圖來源:shutterstock)





