



全球人工智慧(AI)運算能力與效率需求急遽攀升的浪潮下,由 ChatGPT 開發商 OpenAI 所規劃的龐大「星際之門」(Stargate)計畫,已成為驅動全球記憶體產品市場結構性變革的核心催化劑。這項耗資巨大的計畫,對記憶體晶片的需求達到前所未有的水準,迫使供應鏈加速創新,並重新定義了從高頻寬記憶體(HBM)到標準動態隨機存取記憶體(DRAM),乃至固態硬碟(SSD)的分工與價值。
2024年,全球記憶體市場迎來關鍵轉捩點。根據路透社報導,韓國兩大記憶體廠商──三星電子(Samsung Electronics)與 SK 海力士(SK Hynix),已正式簽署意向書(LOI),將為 OpenAI 的資料中心供應關鍵的記憶體晶片。此舉不僅象徵著韓國晶片製造商正式加入「星際之門」的龐大供應鏈,更確立了記憶體在 AI 時代的戰略地位。
由於韓國企業在全球記憶體市場中扮演著決定性的角色,兩家公司合計掌握了全球 DRAM 市場約 70% 的市占率。更關鍵的是,在 AI 伺服器和資料中心不可或缺的核心零組件 HBM 領域,韓國企業更是擁有近 80% 的絕對領先地位。在 AI 加速運算需求爆炸性成長的環境下,HBM 已成為解決龐大算力需求的理想核心零組件。
然而,「星際之門」等超級 AI 專案對記憶體的需求已不再是單純的容量疊加,而是對速度、容量、成本、效率的綜合挑戰。AI 工作負載的特殊性,尤其是在模型推論階段,正推動記憶體架構從傳統的單一記憶體池,走向精細化、分層化管理的「AI 記憶體分級」時代。
AI 工作負載對記憶體的需求分級
AI 模型,特別是大語言模型(LLM),對數據記憶的需求類似於人類大腦,必須有不同層次的「記憶」來處理即時、短期和長期的資訊。根據市場消息指車,AI 時代對記憶體需求因數據被細分為三個主要層級,每個層級對應不同的記憶體產品,這也決定了未來記憶體市場的產品組合與營收結構。
首先是 HBM 主要儲存實時記憶數據。由於 HBM 具有極高的頻寬與讀寫速度,但容量相對有限,因此它用於處理「極熱數據」與「即時對話」,這類數據對延遲要求極高。HBM 的容量範圍大約在 10GB 至百 GB 級。在 AI 伺服器中,HBM 是搭配 GPU 處理器提供核心運算力的關鍵。其次在 DRAM 方面,將做為短期記憶數據。它的速度相對快、容量較大,在伺服器中常利用新型高速介面協議 CXL 延伸系統主記憶體,將數 TB 的 DDR 主記憶體匯集起來,形成大容量快取。DRAM 主要儲存「熱數據」與「多輪對話」,容量約在 百 GB 到 TB 級。

最後是 SSD 扮演長期記憶角色的狀況,其用於儲存外部知識。SSD 容量極大,範圍約在 TB 級到 PB 級,主要用於儲存「歷史對話」、「RAG 知識庫」以及「語料庫」等熱溫數據。如此的記憶體分級模式顯示,未來 AI 資料中心將是 HBM、DRAM 和 SSD 協同運作的複雜系統,而「星際之門」對規模和效率的極端追求,將加速這一分級架構的普遍部署。
KV 快取為 AI 模型的短期記憶,解決方案成產業觀關注焦點
而在 AI 市場需求爆發的情況下,帶動記憶體容量需求暴增的關鍵技術之一,便是大語言模型在推理階段使用的「注意力機制」及由此衍生的「KV 快取」(KV Cache)機制。現階段在 AI 推理過程中,模型會用到類似人腦的注意力機制,必須記住查詢中重要的部分(Key)以及上下文中重要部分(Value),以便回答提示。傳統上,如果每處理一個新的 token(新詞),模型必須針對先前處理過的所有 token 重新計算每個詞的重要性(Key 與 Value),以更新注意力權重,過程極為耗時。而為解決此瓶頸,LLM 被加入 KV 快取機制。KV 快取類似於學生做筆記的概念,它能將先前的重要資訊(Key 與 Value)儲存在記憶體中,免去每次重新計算的成本,從而將 token 處理與生成速度提升數個數量級。
KV 快取被稱為「AI 模型的短期記憶」。它使得模型能記住之前處理過的內容,無論用戶重啟討論或提出新問題,都不必從頭開始重新計算。這讓 AI 能提供長格式語境,並能隨時了解用戶說過的、推理過的、提供過的內容,為更長、更深入的討論提供更快、更縝密的答案。然而,KV 快取帶來的挑戰是巨大的。因為上下文越長,需要的快取就越大。即使是中等規模的模型,KV 快取也會迅速膨脹到每個會話多 GB,這使得針對 KV 快取的解決方案,成為各家硬體與軟體供應商關注的焦點之一。
針對長情境推論與頂級記憶體配置需求,輝達推出 Rubbin CPX
面對「星際之門」級別的長情境(context)處理需求,GPU 大廠輝達 (NVIDIA) 的劃時代創新技術,直接鎖定記憶體的高效能、高擴展性挑戰。在新推出的 Rubin CPX GPU上,其核心使命就是突破 AI 系統在「長情境」推論上的瓶頸。隨著 AI 模型處理數百萬詞元的需求愈加常見(如長篇文件理解或一小時影片生成),Rubin CPX 以全新設計打破限制,能在單一晶片上整合影片解碼器、編碼器與長情境推論處理,提供前所未有的速度與效能。
輝達創辦人暨執行長黃仁勳指出,Rubin CPX 是首款專為大規模情境 AI 設計的 CUDA GPU。該平台與 Vera Rubin CPU 及 Rubin GPU 協同運作,組成的 Vera Rubin NVL144 CPX 平台,單一機架下可提供高達 8 exaflops 的 AI 運算能力,效能是現有 GB300 NVL72 系統的 7.5 倍。為了支撐如此嚴苛的 AI 工作負載,Rubin CPX 系統必須配備驚人的記憶體配置,100TB 記憶體與每秒 1.7PB 的頻寬,確保資料能以極高速流動。
在單一晶片層面,Rubin CPX 配備 128GB GDDR7 記憶體,採用 NVFP4 精度,運算力達 30 petaflops,能以極高能源效率處理大規模 AI 推論。與前代相比,Rubin CPX 系統的專注力提升 3 倍,讓 AI 模型能處理更長的情境序列,維持高效能而不降速。這樣輝達解決方案代表了記憶體市場的頂級需求:追求極致的速度與容量,並以高階 HBM 和 GDDR7 支撐,這對確保記憶體廠 HBM 業務的長期穩定增長提供了強勁保證。
成本最佳化與快取管理技術崛起,華為開啟 KV 快取記憶體專職時代
雖然 HBM 在 AI 運算中不可或缺,但其高昂的價格成為資料中心記憶體成本的一大瓶頸。為了應對不斷膨脹的 KV 快取體積和降低總體擁有成本(TCO),業界也積極開發以軟體與架構創新最佳化記憶體使用的解決方案,這對標準 DRAM 和 SSD 市場提出了更高的要求。
華為近期開發了一款名為「統一快取管理器」(Unified Cache Manager,簡稱 UCM)的新軟體工具,目標是無需使用 HBM 即可加速大型語言模型(LLM)的訓練與推理。由於UCM 是一款以 KV 快取為中心的推理加速套件,它融合了多類型緩存加速演算法工具。它的核心功能是根據不同記憶體類型的延遲特性,以及各類 AI 應用的延遲需求,將 AI 資料分級分配在 HBM、標準 DRAM 與 SSD 之間。透過分級管理推理過程中產生的 KV 快取記憶數據,UCM 成功擴大了推理上下文視窗,實現高吞吐、低時延的推理體驗,並降低了每 Token 的推理成本。
華為的 UCM 方案強調,即使在缺乏 HBM 的情況下,也能透過軟硬體協同優化來解決 KV 快取的容量和速度問題,這為 DRAM 和 SSD 在 AI 生態系統中扮演更積極的角色提供了強大的技術依據。
Enfabrica 從硬體架構試圖降低資料中心記憶體成本
另外,由輝達支持的晶片新創企業 Enfabrica 則從硬體架構著手,試圖降低資料中心高昂的記憶體成本。他們推出了 EMFASYS 軟體搭配 ACF-S 晶片(又稱為 SuperNIC)的系統。也因為ACF-S 本質上是一顆融合乙太網路(Ethernet)與 PCI-Express/CXL 的交換晶片。Enfabrica 創辦人暨執行長 Rochan Sankar 指出,他們透過自研的專用網路晶片,可讓 AI 運算晶片直接連接到裝滿 DDR5 記憶體規格的設備上。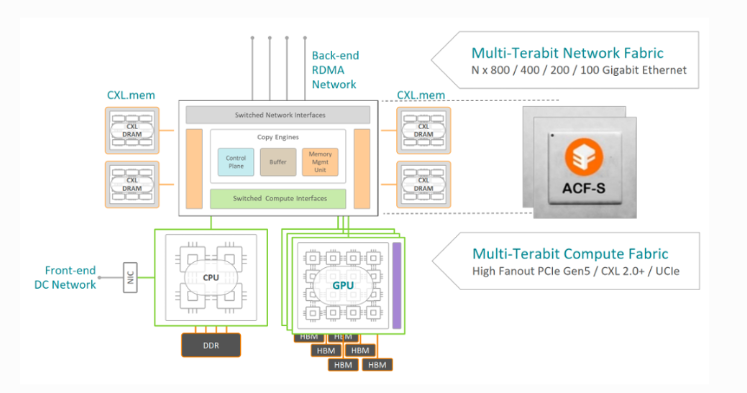
雖然 DDR5 傳輸速度不及 HBM,但價格卻便宜得多。Enfabrica 的目標是擁有一個能以主機主記憶體速度運行、足以存放 KV 向量與 embeddings 的超大共享記憶體池。外媒認為,若能加速用於 AI 推理核心的 KV 快取,有望成為 Enfabrica 等同業期待已久的「殺手級應用」。且透過利用自研的專用軟體在 AI 晶片與大量低成本記憶體之間進行數據傳輸,Enfabrica 在保證資料中心性能的同時,有效控制了成本。這類架構創新突顯市場對於利用低成本、大容量 DDR5 / CXL 記憶體來滿足 KV 快取需求的強烈願望。

整體來說,OpenAI「星際之門」計畫以及整個 AI 產業對長情境、高效率推理的追逐,正對全球記憶體產品市場產生深遠且複雜的影響。例如 HBM 成為不可撼動的戰略核心、DRAM 市場角色重新定義,以及SSD 進入高性能 AI 架構,加上 架構創新的決定性作用等。這使得星際之門所代表的超大規模 AI 推理需求,徹底改變了記憶體市場的供需生態。
(首圖來源:Unsplash)





