



由創意電子前總經理賴俊豪擔任董事長的 IC 設計公司 Skymizer 於近期正式發表其首款實體 AI 推論晶片 「HTX301」,並預告將於下週的 Computex 電腦展中進行實機展示。根據 Skymizer 的簡介指出,HTX301 專注於推論(Inference)與解碼(Decode)任務,主打讓企業能以低成本、低功耗的方式,在本地端實現超級大模型的自主部署。
賴俊豪在發表會前的致詞時表示,在當前 AI 晶片動輒追求 6 奈米以下先進製程的趨勢中,HTX301 最具顛覆性的特點在於它採用了台積電成熟的 28 奈米製程。賴俊豪強調,由於公司具備深厚的軟體與編譯器底蘊,晶片的效能主要是由軟體來定義與達成,因此不需一味追求極致的硬體算力。
此外,賴俊豪還指出,HTX301 在硬體設計上極度簡化,採用標準的 BGA 封裝與標準的 DDR 記憶體,完全不需依賴昂貴且產能受限的 HBM 或 CoWoS 先進封裝。量產版的 HTX301 將設計為標準的 PCIe 擴充卡形式,大幅降低了系統設計與製造的門檻。
Skymizer 簡介指出,HTX301 單卡搭載 512GB 記憶體,鎖定兆級參數 MoE 模型 HTX301 的設計哲學是「先求放得下,再求算得快」。另外,現行 AI 伺服器最昂貴的成本往往來自於跨卡溝通的頻寬(如 NVLink 等機制),因此 HTX301 致力於將超級大模型濃縮在一張卡上執行。
根據規格規劃,最頂級的一卡八套客製化版本,單卡即可搭載 8 顆 HTX301 晶片與記憶體,提供高達 512GB 的記憶體空間。這使得單張卡就能夠放得下且運行如 DeepSeek-R1(671B)這類接近兆級參數的超級大模型,並預期能達到接近每秒 20 個 Token 的解碼速率。另外,也有針對 30B 中型模型的一卡一套方案,以及針對 397B 大模型的一卡四套(256GB)標準版方案。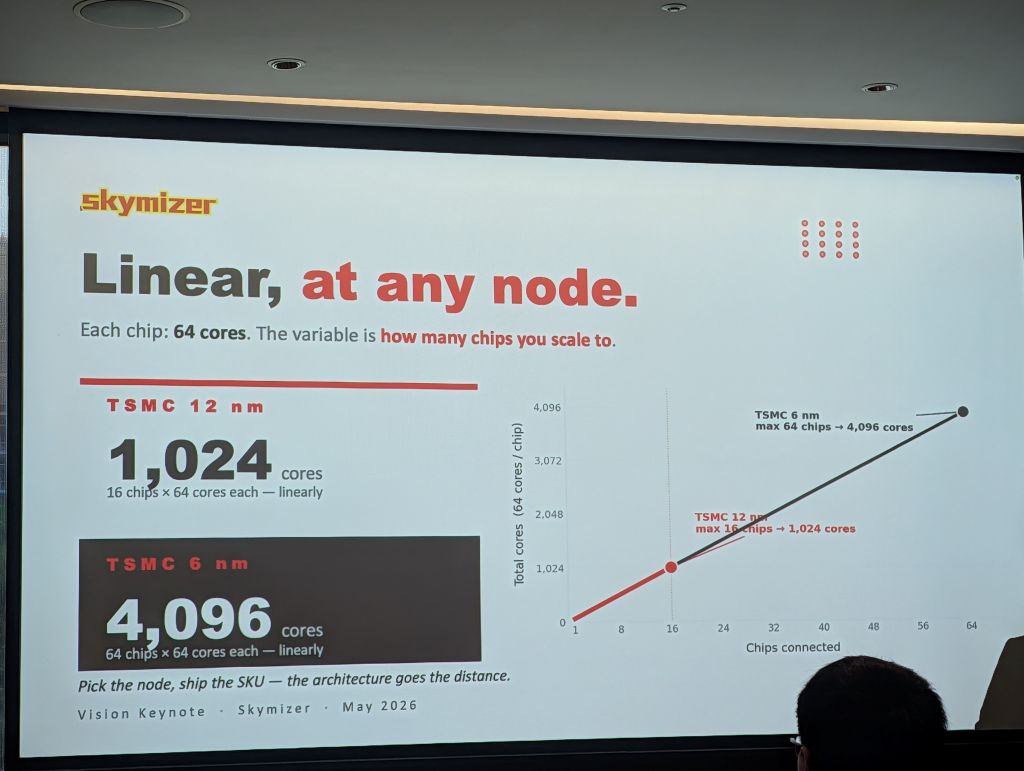
Skymizer表示,HTX301 解決了目前企業導入生成式 AI 的三大痛點:資料安全、雲端訂閱成本(Token 吃到飽),以及硬體建置與耗能成本。以運行 DeepSeek-R1 模型為例,若採用傳統 GPU 方案,通常需要建置一台包含 8 張 H100 的伺服器,總功耗高達 10kW 且建置成本極其昂貴。然而,使用 HTX301 的一卡八套方案,晶片總功耗僅約 325W,搭配基礎伺服器整體耗能僅約 1.3kW。其冷卻系統也極為簡單,無需複雜的水冷設備,僅靠一般風扇即可散熱,讓企業甚至可以在桌上型主機上部署超大模型,達成真正的「資料自主可控」。
針對未來的發展,Skymizer 的研發團隊也公開了其「Scale out (向外擴充)」的次世代藍圖。透過軟硬體協同設計,Skymizer 即將推出的 LISA v4 架構能將「溝通」與「運算」徹底分開並重疊隱藏。這項技術能將 LLM 張量平行處理所需的跨晶片頻寬,大幅縮減至傳統教科書要求的 1/500 到 1/4000。這代表著未來不需特殊的 Switch 架構,僅依靠標準的 SerDes(如 UCIe、PAM4 等)就能將晶片一路無痛串接。
針對未來發展,Skymizer 預計於 2027 年推出採用 12 奈米與 6 奈米製程的新一代晶片。在線性擴充的架構下,12 奈米版本最多可無痛串接 16 顆晶片(1,024 核心)。而 6 奈米版本更可支援串接高達 64 顆晶片(4,096 核心),目標是在效能上擊敗現有 3 到 2 奈米的晶片,並以極低的功耗滿足中小型資料中心的需求。
最後,在商業策略上,Skymizer 指出,目前雙管齊下,一方面持續提供 IP 授權服務(IP offering),讓合夥夥伴進行 SoC 整合;另一方面也將提供 IC 貼牌服務,開放晶片授權讓客戶貼牌,共同拓展廣大的超大模型地端推論市場。
(首圖來源:科技新報攝)





