



經過上一篇理解光通訊與資料中心的三種擴展架構後,就更能明白,市場如今不僅關注競爭對手 AMD 的動向,更聚焦在 AI 晶片龍頭 NVIDIA 與全球通訊晶片巨頭博通之間的競爭關係。
事實上,現在 AI 產業的競爭除了晶片間的競爭外,更是擴大到系統間解決方案的競爭。
博通與 NVIDIA 第一個交集就是「客製化 AI 晶片」(ASIC)。由於 NVIDIA GPU 價格高昂,包括 Google、Meta、亞馬遜、微軟等雲端服務供應商(CSP)都在開發自家 AI 晶片,而博通的 ASIC 能力成為這些公司的首要夥伴。
除了自研晶片的競爭外,另一個更關鍵技術是「網路連接技術」,這也是博通與 NVIDIA 的第二個交集。
首先是在 Scale-Up 部分,在 NVLink 和 CUDA 這兩大護城河守護下,博通醞釀了多時,終於在今年推出最新的網路交換機晶片 Tomahawk Ultra(戰斧),有機會切入 Scale-Up 市場,目標挑戰 NVIDIA NVLink 主導地位。
Tomahawk Ultra 是博通一直推動的「縱向擴展乙太網路」(Scale-Up Ethernet,簡稱 SUE)計畫的一部分,這個產品也視為 NVSwitch 的替代方案。博通表示,Tomahawk Ultra 一次可串聯的晶片數量是 NVLink Switch 的四倍,將交由台積電 5 奈米製程。
值得注意的是,博通雖然身在 UALink 聯盟之一,但他也積極推廣基於乙太網路的 SUE 架構,因此市場也相當關注博通與 UALink 的競合關係,以及如何共同應對 NVLink 這個大敵。
為了抵禦博通強襲,NVIDIA 今年也推出 NVFusion 解決方案,開放合作夥伴如聯發科、Marvell、Astera Labs 等共研,並透過 NVLink 生態系打造客製化的 AI 晶片。外界認為,這是為了鞏固生態系而進行的半開放式合作,也給更多合作夥伴一些客製化空間與機會。
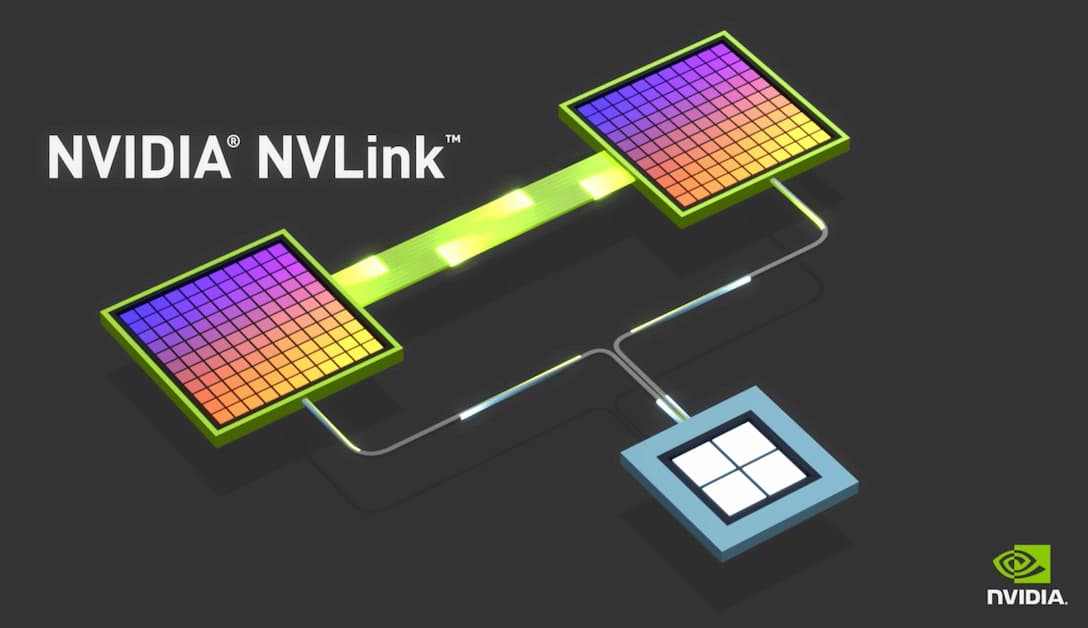
Scale-Out 部分,主要由在乙太網深耕已久的博通壟斷,近期最新出的產品包括 Tomahawk 6、Jericho4,搶攻 Scale Out 和更遠傳輸距離的商機。
而 NVIDIA 則推出許多 Quantum InfiniBand 交換器產品,以及 Spectrum 乙太網路交換平台,加強更多面向的 Scale-Out 產品。雖然 InfiniBand 屬於開放架構,但因產品生態環境主要仍由 NVIDIA 收購的 Mellanox 所壟斷,限制了客戶的選擇彈性。

▲ 根據博通照片,三款產品各自橫跨兩種不同的伺服器擴展架構 。(Source:科技新報)
針對更長距離的跨資料中心擴展的 Scale-Across,目前還不確定博通或 NVIDIA 誰會領先,不過 NVIDIA 針對這一概念率先推出 Spectrum-XGS,該解決方案透過新的網路演算法,來實現站點之間更遠距離的資料有效移動,也可以作為現有 Scale-Up 和 Scale-Out 架構的補充方案。
至於博通的 Jericho4 也符合 Scale-Across 的概念。博通指出,Tomahawk 系列晶片能串聯單一資料中心內的機櫃,連線距離通常不超過一公里(約 0.6 英里),而 Jericho4 設備則能處理距離超過 100 公里的跨機房距離內連線,維持無損 RoCE 傳輸,其資料處理能力則約前一代產品的四倍。
那麼 NVIDIA 和博通的 CPO 解決方案?
隨著網路傳輸戰場持續,相信在光網路的競爭將會更加激烈,對此 NVIDIA 和博通都針對 CPO 光通訊找尋新解方,而台積電、格羅方德也積極開發用於 CPO 的製程與解決方案。
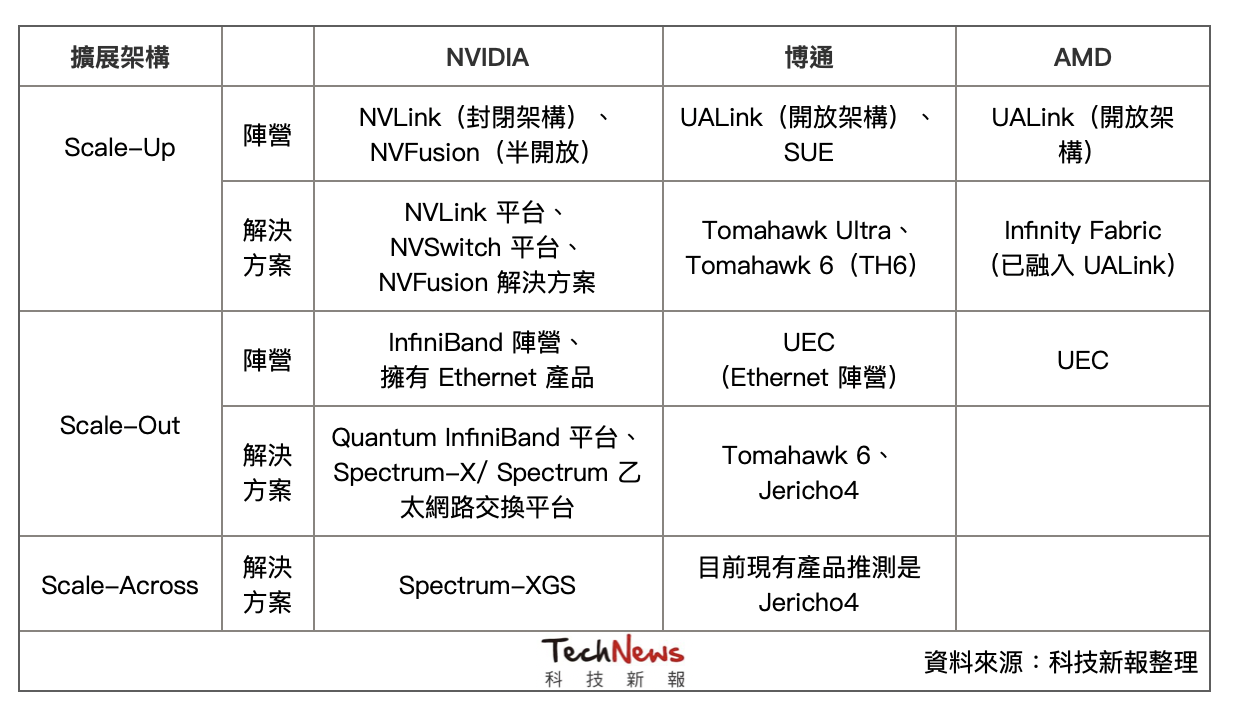
NVIDIA 的策略是以系統架構為出發點,並將光學互連視為 SoC 的一部分,而非外掛式模組,並於今年 GTC 正式發表 Quantum-X Photonics InfiniBand 交換器和 Spectrum-X Photonics Ethernet 交換器,前者將於年底推出,後者則於 2026 年問世。
兩個平台均採用台積電 COUPE 平台,透過 SoIC-X 封裝技術將 65 奈米的光子積體電路(PIC)與電子積體電路(EIC)整合。而這個策略出發點,是為了強調自家平台整合,加強整體效益與規模擴展。
博通的策略則專注於提供全方位解決方案,聚焦在供應鏈的規模化運作,供應第三方客戶完整的模組化方案,幫助客戶應用落地。博通也表示,公司之所以在 CPO 領域成功,是建立在深厚的半導體與光學技術整合能力之上。

博通目前推出第三代 200G / lane CPO 搶市。博通也表示,其 CPO 產品採用 3D 晶片堆疊架構,PIC 同樣使用 65 奈米,EIC 則採用 7 奈米製程。
由下圖可知,光收發模組由以下關鍵元件組成,如雷射光源(Laser Diode)、光調變器(Modulator)、光感測器(Photo Detector)等。其中,雷射光源負責產生光訊號,光調變器負責將電訊號/數位訊號轉成光訊號,因為涉及電光轉換,也可以說是決定單通道傳輸速度關鍵。
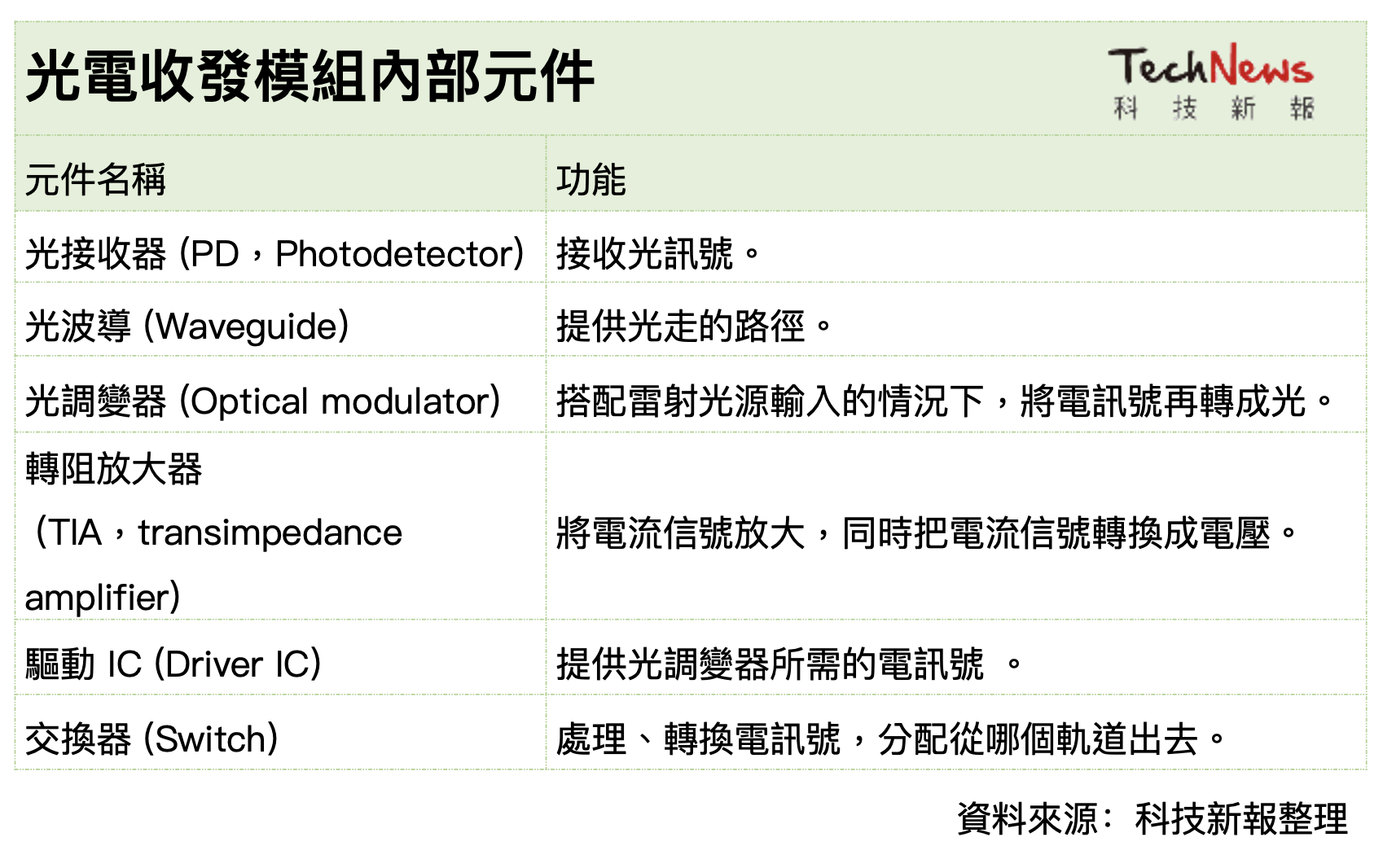
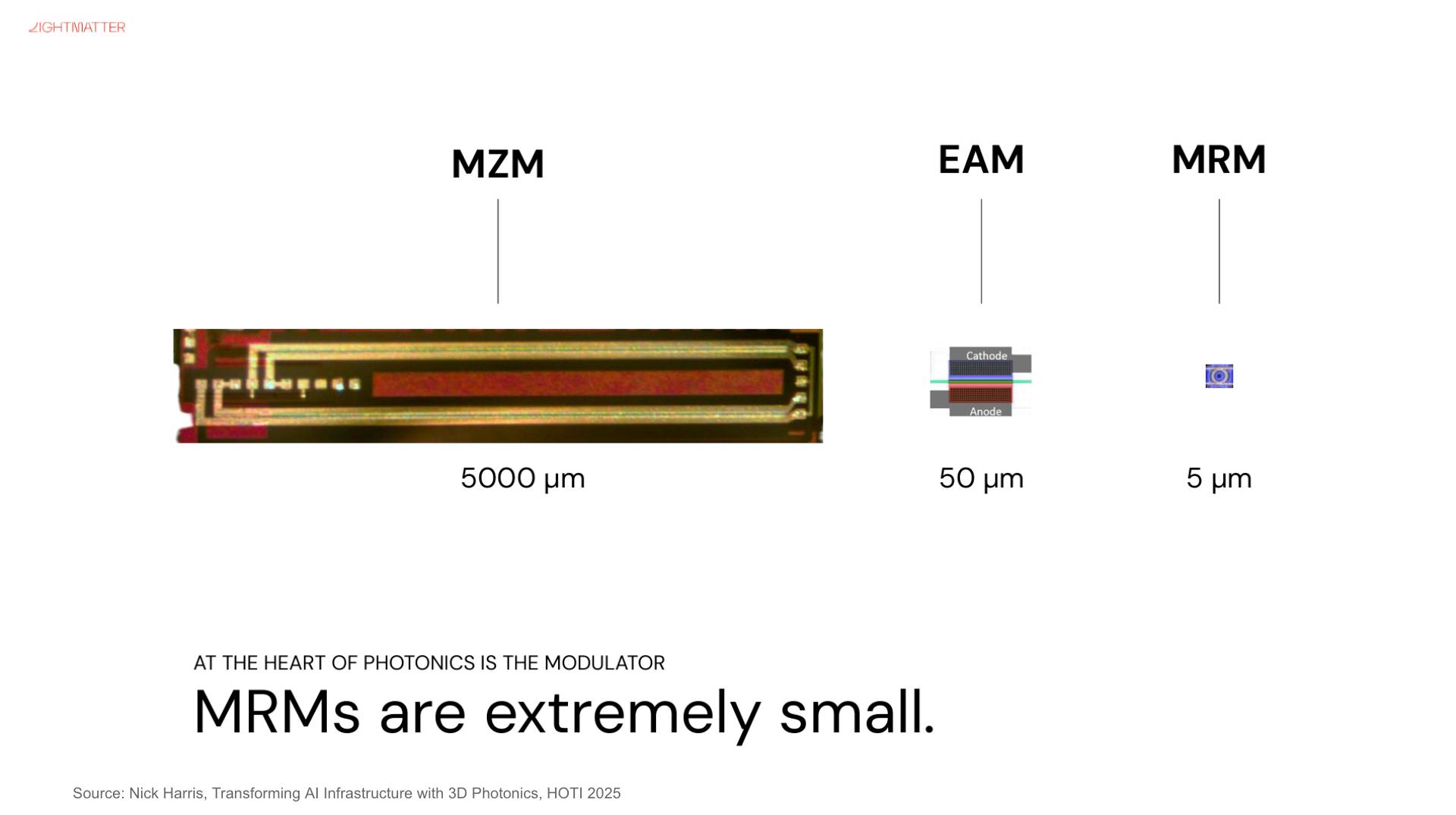
在關鍵的光調變器上,NVIDIA 選擇 MRM(微環調變器,Micro-Ring Modulator)。由於 MRM 尺寸較小,容易受誤差及溫度影響,也將是導入 MRM 的挑戰之一。
至於博通,則選擇使用技術較成熟的 MZM 調變器(馬赫–曾德爾調變器,Mach-Zehnder Modulator),同時布局 MRM 技術,目前已經通過 3 奈米製程試產,並以晶片堆疊方式,持續領導 CPO 進展。
(Source:Redefine Innovation)
目前在 AI 推論持續擴張浪潮下,市場焦點已逐漸從「算力競賽」轉向「資料傳輸速度」,無論是博通主打的網路與交換技術、NVIDIA 推動的端到端解決方案,誰能率先突破傳輸效率與延遲的限制,誰就有機會在下一波 AI 競賽中奪得先機。
(首圖來源:AI 生成)





