



中國封殺輝達的中國客製版 RTX Pro 6000D ,要科技大廠採用中國自產 AI 晶片,中國媒體報導,阿里巴巴旗下半導體設計部門「平頭哥」(T-Head)已開發人工智慧(AI)晶片,效能可與輝達上款中國客製 H20 晶片匹敵。即便晶片性能可以追上,但能否用輝達「稱霸武林」的 CUDA 生態架構,仍是關鍵。專業人士表示,雖然正常狀況 CUDA 不支援其他 AI 晶片,但有非正規方法界接,當然效能會有落差。
專業人士表示,CUDA 是輝達專屬的 GPU 加速架構,緊緊綁定輝達 GPU 驅動程式 (NVIDIA Driver) 與硬體指令集 (PTX / SASS)。如果不是用輝達 GPU,即使 Docker Image 有 CUDA toolkit,也無法執行 CUDA kernel,因底層硬體不支援。Docker Image 的 CUDA 軟體只能經 NVIDIA Container Runtime (nvidia-docker2 / NVIDIA Container Toolkit) 呼叫宿主機 NVIDIA 驅動,所以宿主必須要有輝達 GPU+驅動。
但市場 AI 晶片並非只有輝達一家,AMD、英特爾甚至極力強調半導體自主的中國也有華為、阿里巴巴、百度產品在測試或商品化。只要有市場,就一定有供應,即便其他 AI 晶片不能直接用 CUDA 生態架構,仍有可行替代方案。
專業人士表示,如果硬體不是輝達 GPU,但想在 Docker Image 使用 CUDA 生態 / CUDA 程式碼,有有幾種路線:
1. 模擬層 (translation layer)
ZLUDA:將 CUDA API call 翻譯成對 Intel / AMD GPU 的呼叫(目前支援度有限,不完全相容)。
HIPIFY + ROCm:AMD 的 ROCm 生態提供 HIP (Heterogeneous-Compute Interface for Portability),能把 CUDA 程式碼轉換成可用 AMD GPU 執行 HIP 程式。但因不是透明 Docker CUDA 執行,需修改程式碼或特殊 runtime。
2. CPU fallback
使用 LLVM-based CUDA 模擬器(例如 cuda-sim 或 cpu-only build)。其缺點是效能極差,幾乎只適合測試程式正確性,不適合實際運算。
3.OpenCL / SYCL / oneAPI
如果目標是「跨平台 GPU 加速」,建議用 SYCL / oneAPI 或 OpenCL。Docker Image 可打包這些 runtime,不用靠 CUDA。這方法缺點是需修改原 CUDA 程式。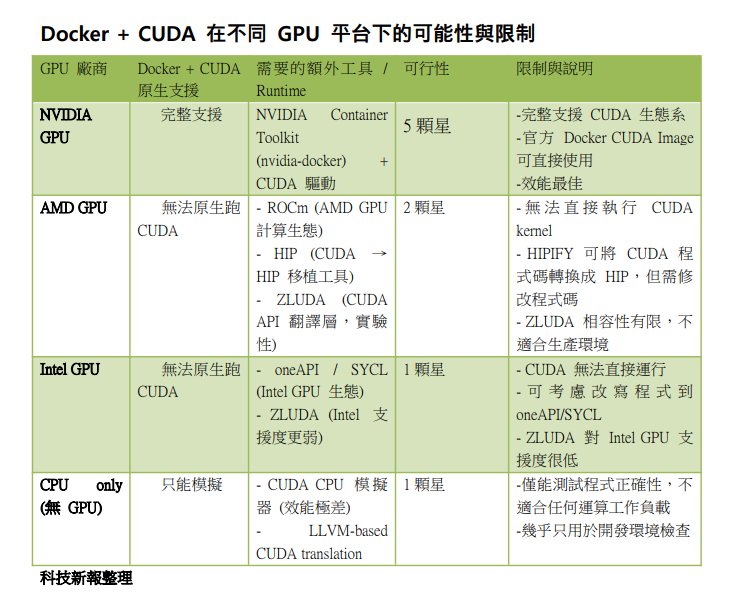
總結,沒有輝達 GPU 基本上無法原生 Docker Image 執行 CUDA,只能考慮 ZLUDA / HIP (ROCm) 跑 CUDA 程式,但相容性有限。如果只想「打包 CUDA 環境」,Docker Image 當然可以,但需要輝達 GPU+驅動支援才真能跑。
(首圖來源:輝達)





